
我需要为CNN模型建立一个混乱的矩阵
我需要为CNN模型建立一个混乱的矩阵
提问于 2019-11-18 13:59:38
嗨,我是机器学习的新手,我只是想知道如何从这段代码中生成一个混淆矩阵,我只是按照youtube上的说明,我想我迷路了,我只需要画出混淆矩阵,我的数据集都是关于癌症的,有两类癌症和癌症,我只是跟踪了sentdex的视频,改变了他的数据集。
import tensorflow as tf
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
import numpy
import matplotlib.pyplot as plt
import os
import cv2
DATADIR = "C:/Users/Acer/imagerec/MRI"
CATEGORIES = ["yes", "no"]
for category in CATEGORIES:
path = os.path.join(DATADIR,category)
for img in os.listdir(path):
img_array = cv2.imread(os.path.join(path,img) ,cv2.IMREAD_GRAYSCALE)
plt.imshow(img_array, cmap='gray')
plt.show()
break
break
print(img_array)
print(img_array.shape)
IMG_SIZE = 50
new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE))
plt.imshow(new_array, cmap='gray')
plt.show()
training_data = []
def create_training_data():
for category in CATEGORIES:
path = os.path.join(DATADIR, category)
class_num = CATEGORIES.index(category)
for img in os.listdir(path):
try:
img_array = cv2.imread(os.path.join(path, img), cv2.IMREAD_GRAYSCALE)
new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE))
training_data.append([new_array, class_num])
except Exception as e:
pass
create_training_data()
print(len(training_data))
import random
random.shuffle(training_data)
for sample in training_data[:10]:
print(sample[1])
X = []
y = []
for features, label in training_data:
X.append(features)
y.append(label)
X = numpy.array(X).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
import pickle
pickle_in = open("X.pickle","rb")
X = pickle.load(pickle_in)
pickle_in = open("y.pickle","rb")
y = pickle.load(pickle_in)
X = X/255.0
model = Sequential()
model.add(Conv2D(256, (3, 3), input_shape=X.shape[1:]))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(256, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(X, y, batch_size=5, epochs=1, validation_split=0.1)
model.save('64x2-CNN.model')回答 1
Stack Overflow用户
回答已采纳
发布于 2019-11-18 14:05:06
这将显示分类器在哪里预测训练数据的正确/错误(因为您的代码中没有测试集)。
from sklearn.metrics import confusion_matrix
pred = model.predict(X)
conf = confusion_matrix(y, pred)Out[1]:
array([[5, 8], # rows are actual classes, columns are predicted classes
[9, 3]], dtype=int64)要绘制它(最小的例子):
import seaborn as sns
sns.heatmap(conf, annot=True)
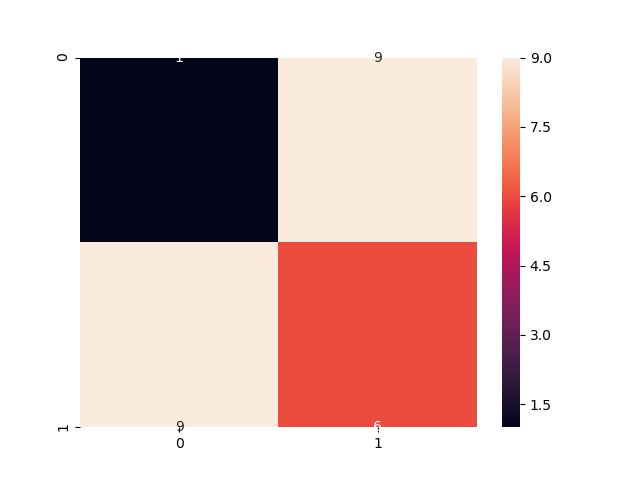
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58916267
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号