
如何用pyspark图形框架pregel API实现循环检测
我正在尝试用Pyspark和图形框架实现来自Rocha & Thatte (http://cdsid.org.br/sbpo2015/wp-content/uploads/2015/08/142825.pdf)和pregel包装器的算法。在这里,我被用于消息聚合的正确语法卡住了。
这一想法是向前推进的:
...In每经过一次,G的每个活动顶点都会向其外部邻居发送一组顶点序列,如下所述。在第一遍中,每个顶点v向它的所有外部邻居发送消息(v)。在随后的迭代中,每个活动顶点v将v附加到它在上一次迭代中接收到的每个序列中。然后,它将所有更新的序列发送给它的外部邻居。如果v在前一次迭代中没有接收到任何消息,那么v将自己停用。当所有顶点都被停用时,该算法将终止。..。
我的想法是将顶点in发送到目标顶点(dst),并在聚合函数中将它们收集到一个列表中。然后,在我的顶点列" sequence“中,我想将这个新的列表项添加/合并到现有的列表项中,然后如果当前顶点id已经在序列中,则使用when语句进行检查。然后,我可以根据顶点列将顶点设置为true,将其标记为循环中的顶点。但是我在Spark中找不到正确的语法来连接它。有人有主意吗?或者实现了类似的东西?
我的当前代码
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql import SQLContext
import pyspark.sql.functions as f
from pyspark.sql.functions import coalesce, col, lit, sum, when
from graphframes import GraphFrame
from graphframes.lib import *
SimpleCycle=[
("1","2"),
("2","3"),
("3","4"),
("4","5"),
("5","2"),
("5","6")
]
edges = sqlContext.createDataFrame(SimpleCycle,["src","dst"]) \
.withColumn("self_loop",when(col("src")==col("dst"),True).otherwise(False))
edges.show()
+---+---+---------+
|src|dst|self_loop|
+---+---+---------+
| 1| 2| false|
| 2| 3| false|
| 3| 4| false|
| 4| 5| false|
| 5| 2| false|
| 5| 6| false|
+---+---+---------+
vertices=edges.select("src").union(edges.select("dst")).distinct().distinct().withColumnRenamed('src', 'id')
#vertices = spark.createDataFrame([[1], [2], [3], [4],[5],[6],[7],[8],[9]], ["id"])
#vertices.sort("id").show()
graph = GraphFrame(vertices, edges)
cycles=graph.pregel \
.setMaxIter(5) \
.withVertexColumn("is_cycle", lit(""),lit("logic to be added")) \
.withVertexColumn("sequence", lit(""),Pregel.msg()) \
.sendMsgToDst(Pregel.src("id")) \
.aggMsgs(f.collect_list(Pregel.msg())) \
.run()
cycles.show()
+---+-----------------+--------+
| id| is_cycle|sequence|
+---+-----------------+--------+
| 3|logic to be added| [2]|
| 5|logic to be added| [4]|
| 6|logic to be added| [5]|
| 1|logic to be added| null|
| 4|logic to be added| [3]|
| 2|logic to be added| [5, 1]|
+---+-----------------+--------+不起作用的代码,但我认为逻辑应该是
cycles=graph.pregel \
.setMaxIter(5) \
.withVertexColumn("is_cycle", lit(""), \
when(Pregel.src("id").isin(Pregel.src(sequence)),True).otherwise(False) \
.withVertexColumn("sequence", lit("null"),Append_To_Existing_List(Pregel.msg()) \
.sendMsgToDst(
when(Pregel.src("sequence").isNull(),Pregel.src("id")) \
.otherwise(Pregel.src("sequence")) \
.aggMsgs(f.collect_list(Pregel.msg())) \
.run()
# I would like to have a result like
+---+-----------------+---------+
| id| is_cycle|sequence |
+---+-----------------+---------+
| 1|false | [1] |
| 2|true |[2,3,4,5]|
| 3|true |[2,3,4,5]|
| 4|true |[2,3,4,5]|
| 5|true |[2,3,4,5]|
| 6|false | null |
+---+-----------------+---------+回答 1
Stack Overflow用户
发布于 2019-11-26 15:36:02
最后,我不是通过pregel实现了Rocha-Thatte算法,而是使用了graphframe/graphX的底层消息聚合功能。如果有人感兴趣,我想分享一下解决方案
该解决方案工作正常,可以处理非常大的图形,而不会失败,但是,如果周期长度或图形很长,则会变得非常慢。不知道现在该怎么改进。可能是使用检查点或聪明地广播
对任何改进的投入都很高兴
# spark modules
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql import SQLContext
from pyspark.sql.types import *
from pyspark.sql import Row
from pyspark.sql.window import Window
import pyspark.sql.functions as f
# graphframes modules
from graphframes import GraphFrame
from graphframes.lib import *
AM=AggregateMessages
def find_cycles(sqlContext,sc,vertices,edges,max_iter=100000):
# Cycle detection via message aggregation
"""
This code is an implementation of the Rocha-Thatte algorithm for large-scale sparce graphs
Source:
==============
wiki: https://en.wikipedia.org/wiki/Rocha%E2%80%93Thatte_cycle_detection_algorithm
paper: https://www.researchgate.net/publication/283642998_Distributed_cycle_detection_in_large-scale_sparse_graphs
The basic idea:
===============
We propose a general algorithm for detecting cycles in a directed graph G by message passing among its vertices,
based on the bulk synchronous message passing abstraction. This is a vertex-centric approach in which the vertices
of the graph work together for detecting cycles. The bulk synchronous parallel model consists of a sequence of iterations,
in each of which a vertex can receive messages sent by other vertices in the previous iteration, and send messages to other
vertices.
In each pass, each active vertex of G sends a set of sequences of vertices to its out- neighbours as described next.
In the first pass, each vertex v sends the message (v) to all its out- neighbours. In subsequent iterations, each active vertex v
appends v to each sequence it received in the previous iteration. It then sends all the updated sequences to its out-neighbours.
If v has not received any message in the previous iteration, then v deactivates itself. The algorithm terminates when all the
vertices have been deactivated.
For a sequence (v1, v2, . . . , vk) received by vertex v, the appended sequence is not for- warded in two cases: (i) if v = v1,
then v has detected a cycle, which is reported (see line 9 of Algorithm 1); (ii) if v = vi for some i ∈ {2, 3, . . . , k},
then v has detected a sequence that contains the cycle (v = vi, vi+1, . . . , vk, vk+1 = v); in this case,
the sequence is discarded, since the cycle must have been detected in an earlier iteration (see line 11 of Algorithm 1);
to be precise, this cycle must have been detected in iteration k − i + 1. Every cycle (v1, v2, . . . , vk, vk+1 = v1)
is detected by all vi,i = 1 to k in the same iteration; it is reported by the vertex min{v1,...,vk} (see line 9 of Algorithm 1).
The total number of iterations of the algorithm is the number of vertices in the longest path in the graph, plus a few more steps
for deactivating the final vertices. During the analysis of the total number of iterations, we ignore the few extra iterations
needed for deactivating the final vertices and detecting the end of the computation, since it is O(1).
Pseudocode of the algorithm:
============================
M(v): Message received from vertex v
N+(v): all dst verties from v
functionCOMPUTE(M(v)):
if i=0 then:
for each w ∈ N+(v) do:
send (v) to w
else if M(v) = ∅ then:
deactivate v and halt
else:
for each (v1,v2,...,vk) ∈ M(v) do:
if v1 = v and min{v1,v2,...,vk} = v then:
report (v1 = v,v2,...,vk,vk+1 = v)
else if v not ∈ {v2,...,vk} then:
for each w ∈ N+(v) do:
send (v1,v2,...,vk,v) to w
Scalablitiy of the algorithm:
============================
the number of iteration depends on the path of the longest cycle
the scaling it between
O(log(n)) up to maxium O(n) where n=number of vertices
so the number of iterations is less to max linear to the number of vertices,
if there are more edges (parallel etc.) it will not affect the the runtime
for more details please refer to the oringinal publication
"""
_logger.warning("+++ find_cycles(): starting cycle search ...")
# create emtpy dataframe to collect all cycles
cycles = sqlContext.createDataFrame(sc.emptyRDD(),StructType([StructField("cycle",ArrayType(StringType()),True)]))
# initialize the messege column with own source id
init_vertices=(vertices
.withColumn("message",f.array(f.col("id")))
)
init_edges=(edges
.where(f.col("src")!=f.col("dst"))
.select("src","dst")
)
# create graph object that will be update each iteration
gx = GraphFrame(init_vertices, init_edges)
# iterate until max_iter
# max iter is used in case that the3 break condition is never reached during this time
# defaul value=100.000
for iter_ in range(max_iter):
# message that should be send to destination for aggregation
msgToDst = AM.src["message"]
# aggregate all messages that where received into a python set (drops duplicate edges)
agg = gx.aggregateMessages(
f.collect_set(AM.msg).alias("aggMess"),
sendToSrc=None,
sendToDst=msgToDst)
# BREAK condition: if no more messages are received all cycles where found
# and we can quit the loop
if(len(agg.take(1))==0):
#print("THE END: All cycles found in " + str(iter_) + " iterations")
break
# apply the alorithm logic
# filter for cycles that should be reported as found
# compose new message to be send for next iteration
# _column name stands for temporary columns that are only used in the algo and then dropped again
checkVerties=(
agg
# flatten the aggregated message from [[2]] to [] in order to have proper 1D arrays
.withColumn("_flatten1",f.explode(f.col("aggMess")))
# take first element of the array
.withColumn("_first_element_agg",f.element_at(f.col("_flatten1"), 1))
# take minimum element of th array
.withColumn("_min_agg",f.array_min(f.col("_flatten1")))
# check if it is a cycle
# it is cycle when v1 = v and min{v1,v2,...,vk} = v
.withColumn("_is_cycle",f.when(
(f.col("id")==f.col("_first_element_agg")) &
(f.col("id")==f.col("_min_agg"))
,True)
.otherwise(False)
)
# pick cycle that should be reported=append to cylce list
.withColumn("_cycle_to_report",f.when(f.col("_is_cycle")==True,f.col("_flatten1")).otherwise(None))
# sort array to have duplicates the same
.withColumn("_cycle_to_report",f.sort_array("_cycle_to_report"))
# create column where first array is removed to check if the current vertices is part of v=(v2,...vk)
.withColumn("_slice",f.array_except(f.col("_flatten1"), f.array(f.element_at(f.col("_flatten1"), 1))))
# check if vertices is part of the slice and set True/False column
.withColumn("_is_cycle2",f.lit(f.size(f.array_except(f.array(f.col("id")), f.col("_slice"))) == 0))
)
#print("checked Vertices")
#checkVerties.show(truncate=False)
# append found cycles to result dataframe via union
cycles=(
# take existing cycles dataframe
cycles
.union(
# union=append all cyles that are in the current reporting column
checkVerties
.where(f.col("_cycle_to_report").isNotNull())
.select("_cycle_to_report")
)
)
# create list of new messages that will be send in the next iteration to the vertices
newVertices=(
checkVerties
# append current vertex id on position 1
.withColumn("message",f.concat(
f.coalesce(f.col("_flatten1"), f.array()),
f.coalesce(f.array(f.col("id")), f.array())
))
# only send where it is no cycle duplicate
.where(f.col("_is_cycle2")==False)
.select("id","message")
)
print("vertics to send forward")
newVertices.sort("id").show(truncate=False)
# cache new vertices using workaround for SPARK-1334
cachedNewVertices = AM.getCachedDataFrame(newVertices)
# update graphframe object for next round
gx = GraphFrame(cachedNewVertices, gx.edges)
# materialize results and get number of found cycles
#cycles_count=cycles.persist().count()
_cycle_statistics=(
cycles
.withColumn("cycle_length",f.size(f.col("cycle")))
.agg(f.count(f.col("cycle")),f.max(f.col("cycle_length")),f.min(f.col("cycle_length")))
).collect()
cycle_statistics={"count":_cycle_statistics[0]["count(cycle)"],"max":_cycle_statistics[0]["max(cycle_length)"],"min":_cycle_statistics[0]["min(cycle_length)"]}
end_time =time.time()
_logger.warning("+++ find_cycles(): " + str(cycle_statistics["count"]) + " cycles found in " + str(iter_) + " iterations (min length=" + str(cycle_statistics["min"]) +", max length="+ str(cycle_statistics["max"]) +") in " + str(end_time-start_time) + " seconds")
_logger.warning("+++ #########################################################################################")
return cycles, cycle_statistics此函数接受如下所示的图形
SimpleCycle:
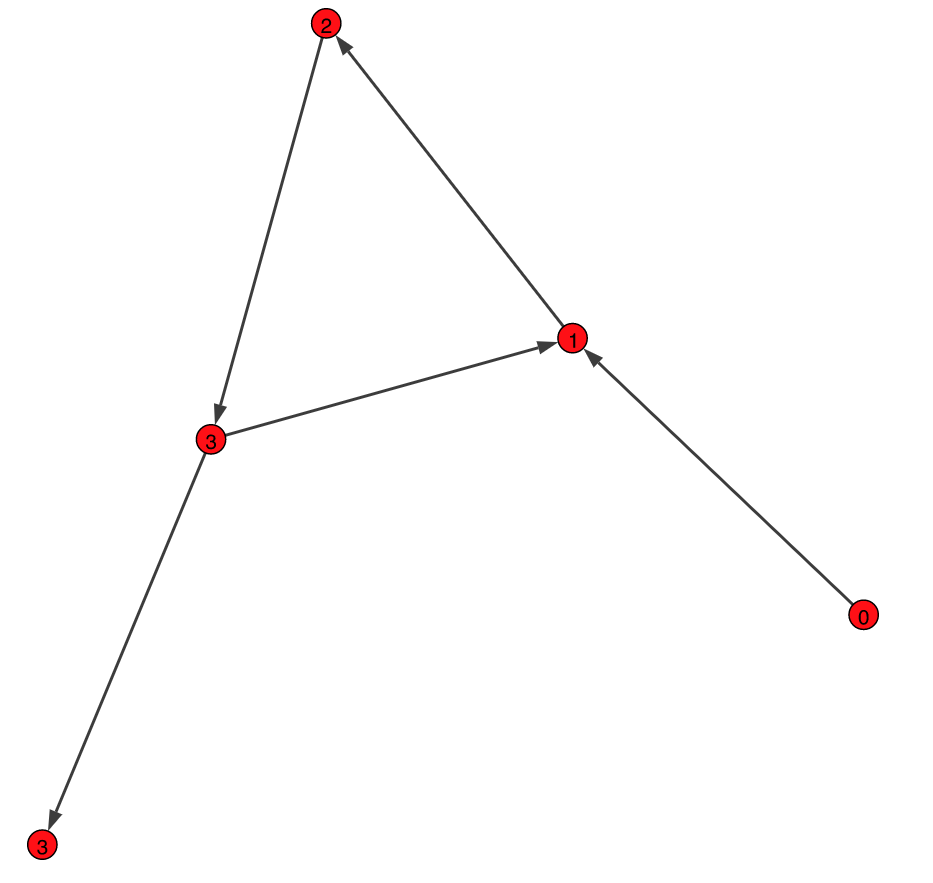
NestedCycle:
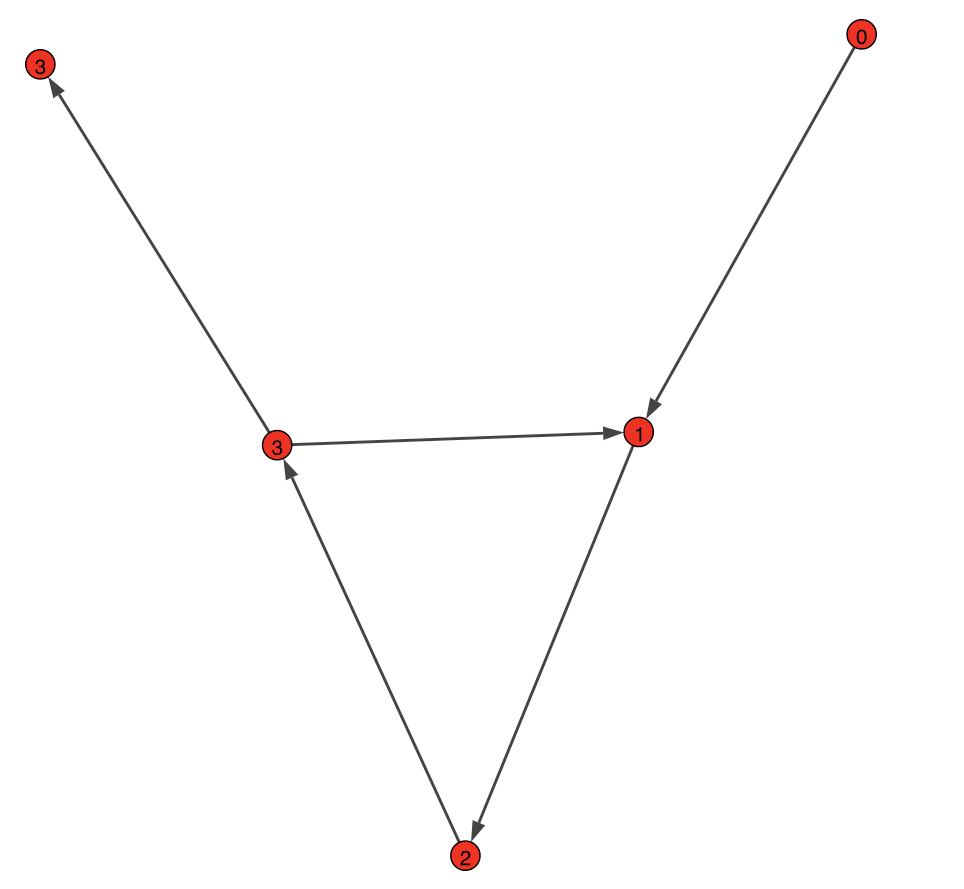
SimpleCycle=[
("0","1"),
("1","2"),
("2","3"),
("3","4"),
("3","1")]
NestedCycle=[
("1","2"),
("2","3"),
("3","4"),
("4","1"),
("3","1"),
("5","1"),
("5","2")]
edges = sqlContext.createDataFrame(SimpleCycle,["src","dst"])
vertices=edges.select("src").union(edges.select("dst")).distinct().distinct().withColumnRenamed('src', 'id')
edges.show()
# +---+---+
# |src|dst|
# +---+---+
# | 1| 2|
# | 2| 3|
# | 3| 4|
# | 4| 1|
# | 3| 1|
# | 5| 1|
# | 5| 2|
# +---+---+
raw_cycles=find_cycles(sqlContext,sc,vertices,edges,max_iter=1000)
raw_cycles.show()
# +------------+
# | cycle|
# +------------+
# | [1, 2, 3]|
# |[1, 2, 3, 4]|
#+------------+https://stackoverflow.com/questions/58895858
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号