
对于非中央卡方的参与,输入'nc‘是如何定义的?
scipy.stats.ncx2实现了一些非中央卡方分布的函数.这些函数有一个输入'nc‘。
假设N(mu,1)中有k个独立随机数
我的问题是nc应该定义为k_mu^2还是\sqrt(k_mu^2)。
我之所以问这个问题,是因为维基百科明确指出:
“另外,pdf也可以写成
(-(nc+df)/2)* 1/2 *(x/nc)**(df-2)/4)* I(df-2)/2
其中,这个公式中的非中心性参数是平方和的平方根。
在scipy.stats.ncx2的文档中,pdf的形式与上面完全相同。
所以输入'nc‘应该是平方和,或者是平方和的平方根。
有什么办法对此进行数值验证吗?
回答 1
Stack Overflow用户
发布于 2019-10-30 22:54:12
维基百科页面中PDF的这两种表示形式中的非中心性参数的含义是相同的。他们没有改变λ的定义,它是正态分布平均值的平方和。
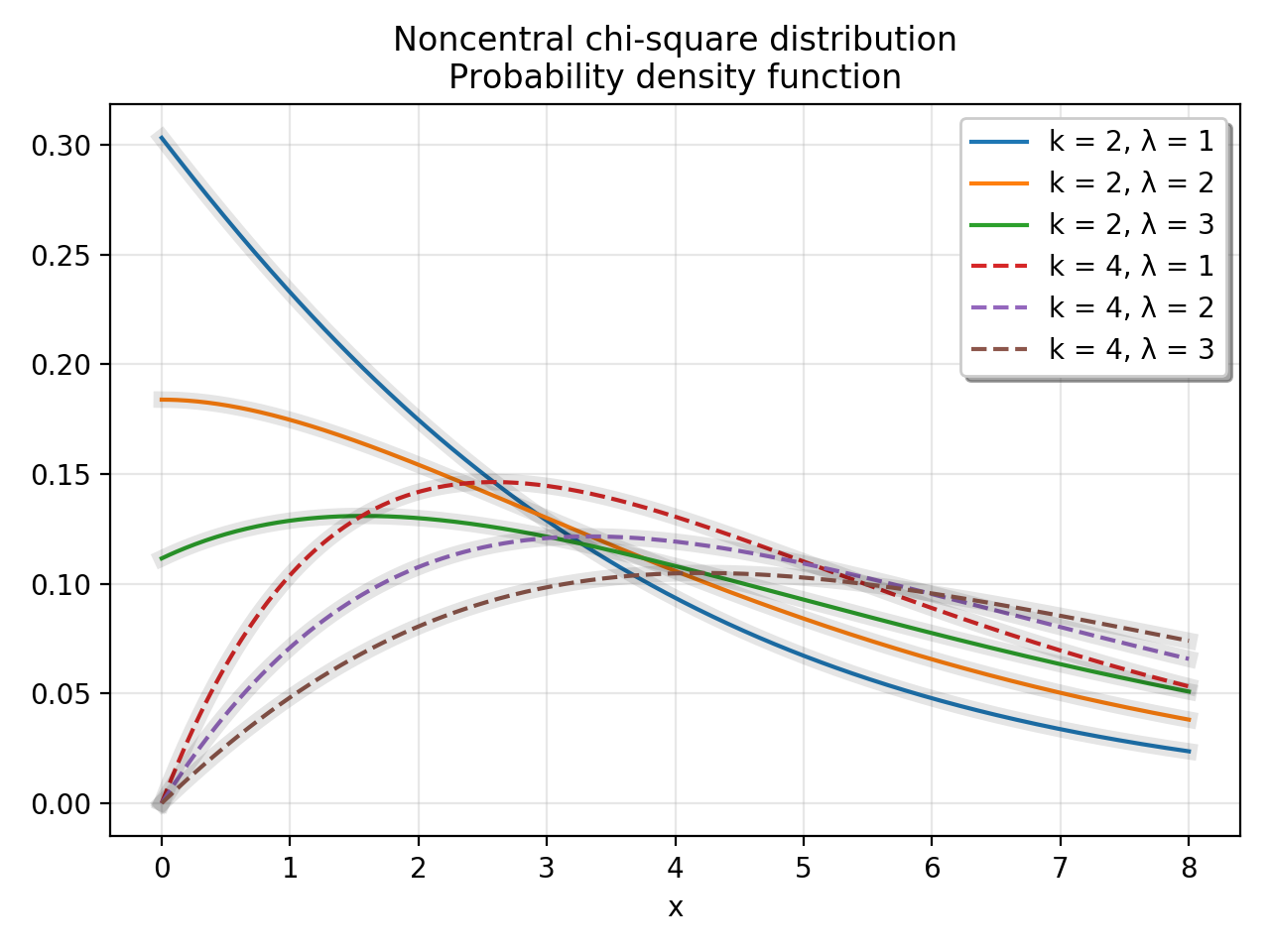
这里有一个脚本,它生成与维基百科页面中的情节相同的曲线。彩色线使用scipy.stats.ncx2.pdf计算,灰色线使用维基百科页面中无限级数的前10个项计算。图中将验证这些表达式是否只是相同值的不同表达式。
import numpy as np
from scipy.stats import ncx2, chi2
import matplotlib.pyplot as plt
def approx_pdf(x, k, lam):
p = np.zeros_like(x, dtype=np.float64)
f = 1
for i in range(10):
p += np.exp(-lam/2) * (lam/2)**i * chi2.pdf(x, k + 2*i) / f
f *= (i + 1)
return p
# df == k on wikipedia
# nc == lambda on wikipedia
x = np.linspace(0, 8, 400)
linestyle = '-'
for df in [2, 4]:
for nc in [1, 2, 3]:
plt.plot(x, ncx2.pdf(x, df, nc), linestyle=linestyle,
label=f'k = {df}, λ = {nc}')
plt.plot(x, approx_pdf(x, df, nc), 'k', alpha=0.1, linewidth=6)
linestyle = '--'
plt.title("Noncentral chi-square distribution\nProbability density function")
plt.xlabel('x')
plt.legend(shadow=True)
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()脚本生成的情节:
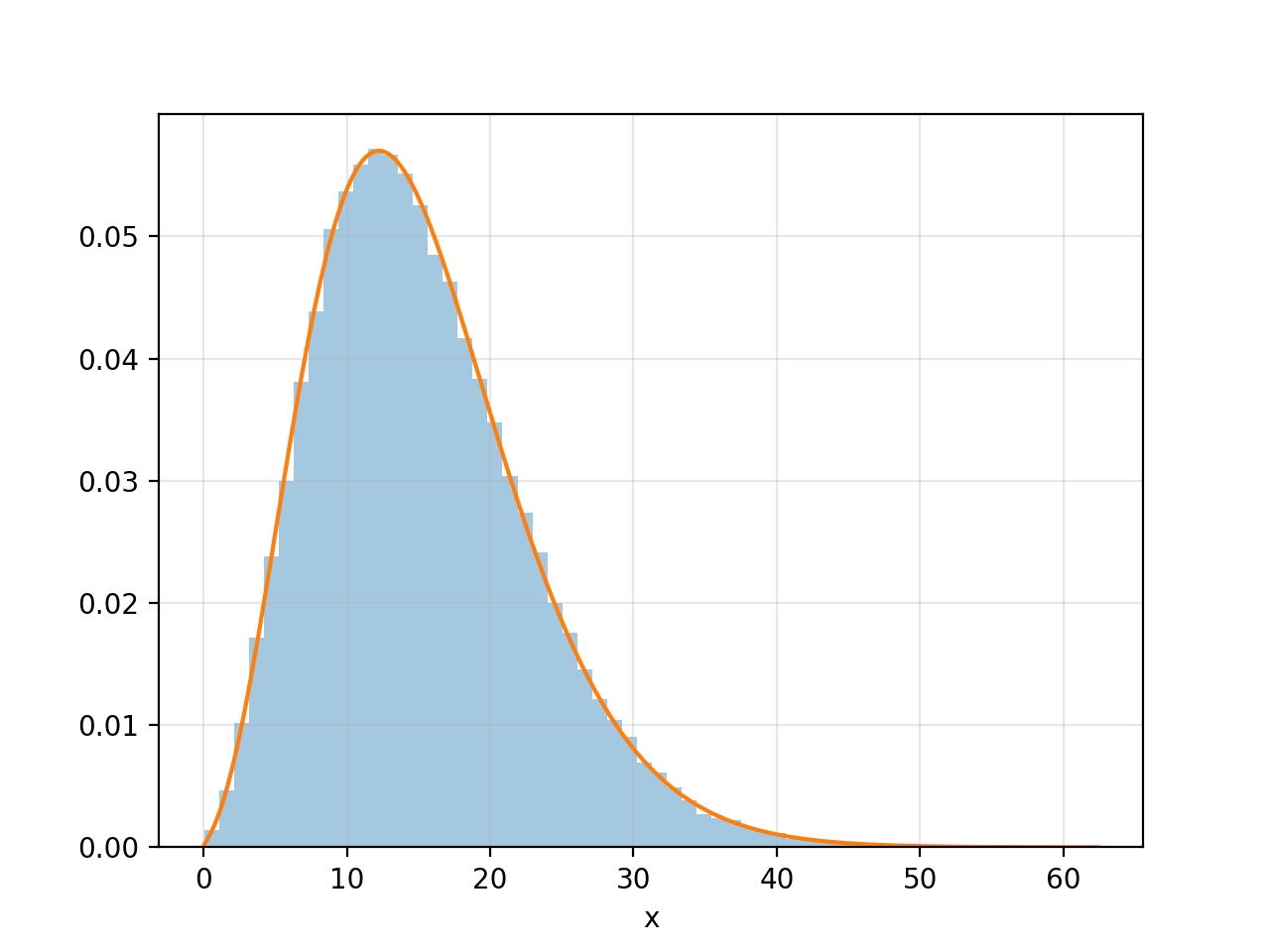
这是另一个简短的脚本,演示非中心性参数实际上是正态分布平均值的平方和。它生成一个大样本的值,每个值是三个正态随机变量的平方和,均值分别为1、1.5和3。这个样本的分布应该是一个非中心的卡方,具有3个自由度,非中心性参数等于平均值的平方和。
import numpy as np
from scipy.stats import ncx2
import matplotlib.pyplot as plt
# Means of the normal distributions.
mu = np.array([1, 1.5, 3])
k = len(mu) # df in scipy.stats.ncx2
lam = (mu**2).sum() # nc in scipy.stats.ncx2
# The distribution of sample should be a noncentral chi-square
# with len(mu) degrees of freedom and noncentrality sum(mu**2).
sample = (np.random.normal(loc=mu, size=(100000, k))**2).sum(axis=1)
# Plot the normalized histogram of the sample.
plt.hist(sample, bins=60, density=True, alpha=0.4)
# This plot of the PDF should match the histogram.
x = np.linspace(0, sample.max(), 800)
plt.plot(x, ncx2.pdf(x, k, lam))
plt.xlabel('x')
plt.grid(alpha=0.3)
plt.show()如图中所示,理论PDF与样本的规范化直方图相匹配。
https://stackoverflow.com/questions/58634358
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号