
为什么在训练中损失曲线会有很大的跳跃(向上)?
我已经训练了两次完全相同的模型(完全相同的训练数据集),但是结果是非常不同的,我对它们的损失曲线的行为感到困惑。
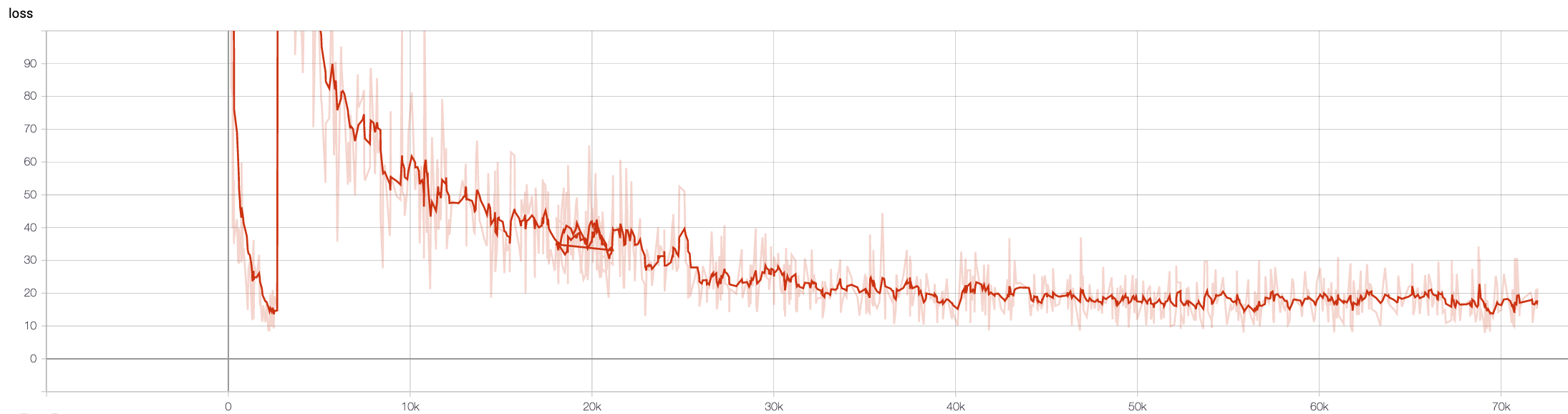
第一次实验的损失曲线(红色曲线)在第一次实验结束时突然跃升,然后缓慢下降。
然而,第二次实验的损失曲线(蓝色曲线)并没有跳到任何地方,而且总是在不断下降以收敛。20世纪后的损耗远低于第一次实验,获得了很好的质量输出。
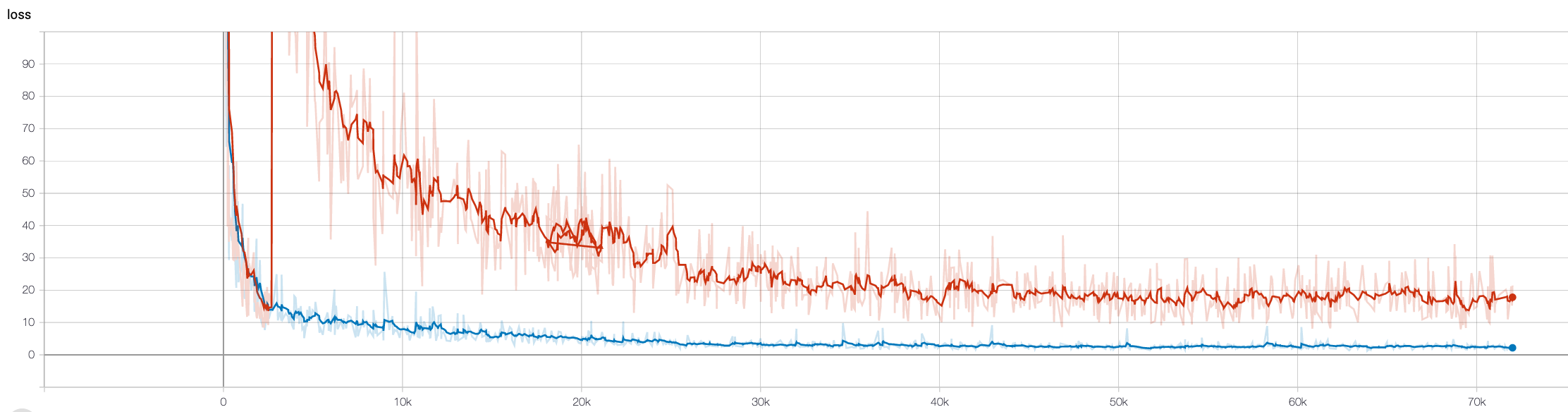
我不知道第一次这么大的跳跃是什么原因。两个实验都使用相同的模型和训练数据集。
模型描述:我的项目是稀疏视点CT图像重建.我的目标是利用迭代方法+ CNN在每次迭代中重建稀疏视图图像。这与陈提出的学习算法非常相似。
该过程包含30个迭代次数,每次迭代时,我使用CNN来更好地训练正则化项。
由于我有30个迭代,3+ (我一直在尝试不同的架构复杂性)层在每个迭代中,我知道会有大量的参数和层。
到目前为止,对于所有的CNN架构,我一直在测试,“大跃进”发生在他们每一个相当平常。
训练数据由3600 512*512稀疏视点CT图像组成,测试数据包括360张稀疏视点CT图像。
批次大小为1,epoch = 20。
更新:谢谢大家的建议。在阅读了答案之后,我开始思考渐变爆炸/消失问题。因此,我将ReLU改为ELU,并将权值初始化从Xavier更改为He,并添加了梯度裁剪。结果很好。我又运行了五次标准模型(与我前面提到的相同的模型),它们都在稳步减速。对于其他带有CNN arch的车型,其损失也有所减少,没有发生重大罢工。
代码已经在每个时代开始时对训练数据集进行了洗牌。接下来我计划做的是添加批处理规范化,并尝试max_norm正则化。
回答 2
Stack Overflow用户
发布于 2019-10-31 06:19:47
这将是一个类似的回答@Anant,但以一种不同的方式。我通常更喜欢用回溯的方法来获得直觉。
给出:损失函数在110年代突然出现(让我们假设)。deviate.
- --可能发生的事情:
- ,在第109号,你可能设置了导致y_hat到y_hat的权重。
在深度神经网络的情况下,这可能是由于爆炸/消失梯度。您可能希望执行重裁剪、或调整权重初始化,从而使权重接近1,从而减少爆炸的可能性。
而且,如果你的学习率很高,那么就会出现这样的问题。在这种情况下,您可以降低学习速率,也可以使用学习速率衰减。
Stack Overflow用户
发布于 2019-10-31 02:20:54
损失值只有在对参数进行极端更新时才能突然跳转,这在采取大梯度步骤时才会发生--这个问题通常称为梯度爆炸。
为了讨论这种爆炸的潜在原因,这可能是因为随机初始化权值、学习速率以及迭代过程中传递的大量训练数据的糟糕组合。
在不知道模型的具体细节的情况下,我只能提出一个一般性的解决方案--您应该尝试更小的学习速率,并且可能很好地调整您的培训数据。希望这能有所帮助。
https://stackoverflow.com/questions/58633177
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号