
将类别在我的dataframe中的一列中分离
将类别在我的dataframe中的一列中分离
提问于 2019-09-20 18:38:05
我需要研究一下什么是最具成本效益的电影类型。我的问题是,这些类型都是在一个字符串中提供的:
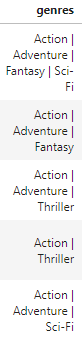
这给了我大约300个不同的类别。我如何把它们分成12个原始的虚拟体裁专栏,这样我就可以分析每一个主要的体裁。
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-09-21 12:46:23
感谢王勇,他提出了熊猫的get_dummies功能。我们可以大大缩短代码:
df = pd.DataFrame({
'movie_id': range(5),
'gernes': [
'Action|Adventure|Fantasy|Sci-Fi',
'Action|Adventure|Fantasy',
'Action|Adventure|Thriller',
'Action|Thriller',
'Action|Adventure|Sci-Fi'
]
})
dummies = df['gernes'].str.get_dummies(sep='|')
final = pd.concat([df, dummies], axis=1)结果:
movie_id gernes Action Adventure Fantasy Sci-Fi Thriller
0 0 Action|Adventure|Fantasy|Sci-Fi 1 1 1 1 0
1 1 Action|Adventure|Fantasy 1 1 1 0 0
2 2 Action|Adventure|Thriller 1 1 0 0 1
3 3 Action|Thriller 1 0 0 0 1
4 4 Action|Adventure|Sci-Fi 1 1 0 1 0原始答案
一种结合熊猫和机器学习数据准备技术的解决方案。假设你用的是熊猫v0.25或更高的版本。
首先,让我们从屏幕截图中创建一个dataframe:
df = pd.DataFrame({
'movie_id': range(5),
'gernes': [
'Action|Adventure|Fantasy|Sci-Fi',
'Action|Adventure|Fantasy',
'Action|Adventure|Thriller',
'Action|Thriller',
'Action|Adventure|Sci-Fi'
]
})
movie_id gernes
0 0 Action|Adventure|Fantasy|Sci-Fi
1 1 Action|Adventure|Fantasy
2 2 Action|Adventure|Thriller
3 3 Action|Thriller
4 4 Action|Adventure|Sci-Fi一部电影可以属于多种细菌。我们想要的是通过一个叫做一热编码的过程来分离这些细菌。我们定义的类别(行动,冒险,颤栗等)并将每部电影标记为属于或不属于每一类别:
from sklearn.preprocessing import OneHotEncoder
s = df['gernes'].str.split('|').explode()
encoder = OneHotEncoder()
encoded = encoder.fit_transform(s.values[:, None])
one_hot_df = pd.DataFrame(encoded.toarray(), columns=np.ravel(encoder.categories_), dtype='int') \
.groupby(s.index) \
.sum()
Action Adventure Fantasy Sci-Fi Thriller
0 1 1 1 1 0
1 1 1 1 0 0
2 1 1 0 0 1
3 1 0 0 0 1
4 1 1 0 1 0这意味着第一部电影属于“行动”、“冒险”、“幻想”和“科幻”,而不是“颤栗”类,第二部属于“行动”、“冒险与幻想”等等。最后一站是把它们结合在一起:
final = pd.concat([df, one_hot_df], axis=1)
movie_id gernes Action Adventure Fantasy Sci-Fi Thriller
0 0 Action|Adventure|Fantasy|Sci-Fi 1 1 1 1 0
1 1 Action|Adventure|Fantasy 1 1 1 0 0
2 2 Action|Adventure|Thriller 1 1 0 0 1
3 3 Action|Thriller 1 0 0 0 1
4 4 Action|Adventure|Sci-Fi 1 1 0 1 0页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58033652
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号