
catplot(kind="count")明显慢于countplot()
我正在处理一个相当大的数据集(大约40m行)。我发现,如果我直接调用sns.countplot(),那么我的可视化图景就会非常快:
%%time
ax = sns.countplot(x="age_band",data=acme)
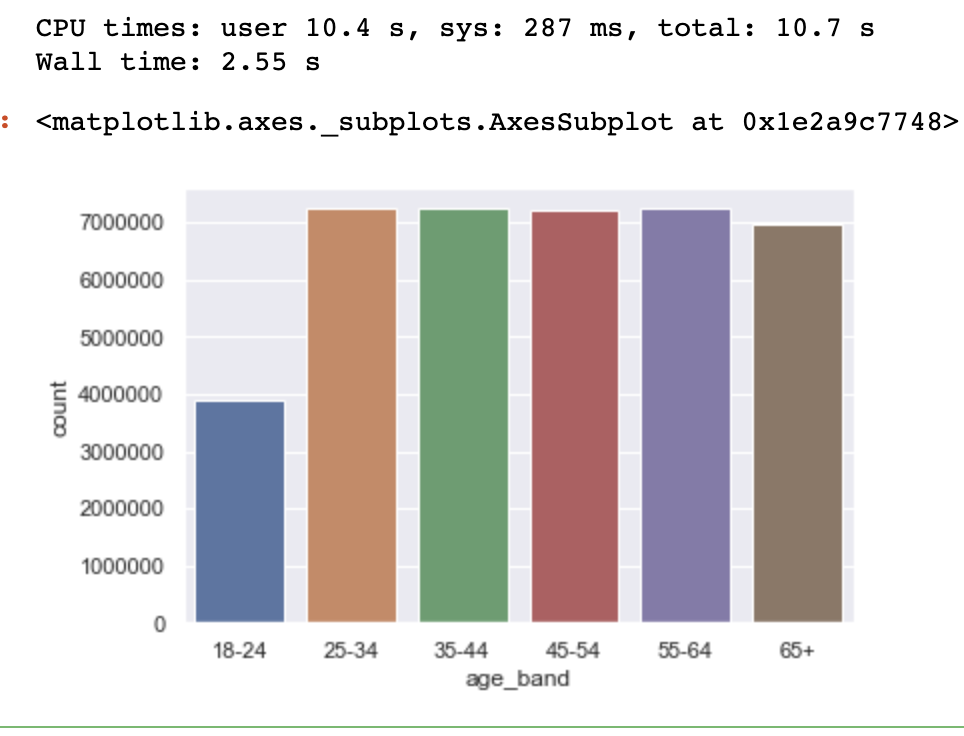
然而,如果我使用catplot(kind="count")进行同样的可视化,那么执行的速度就会大大减慢:
%%time
g = sns.catplot(x="age_band",data=acme,kind="count")
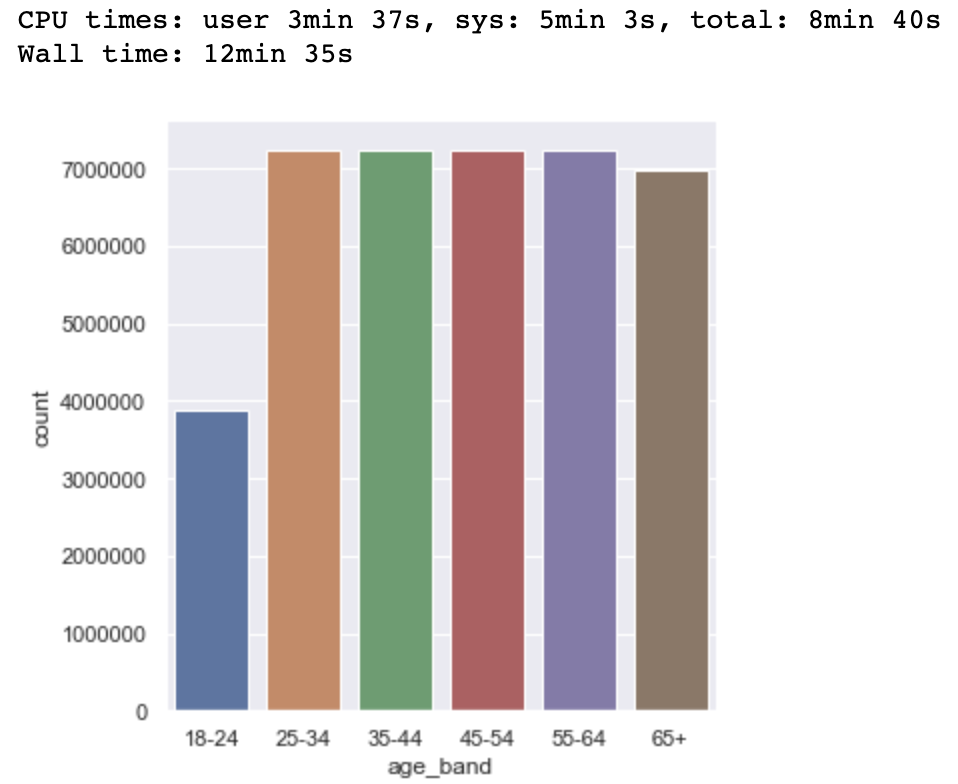
有这么大的性能差异的原因吗?catplot()是否对我的数据进行了某种形式的转换,然后才能绘制它呢?
如果有一个已知的原因,那么它是否扩展到所有图形级函数和轴级函数(如sns.scatterplot()比sns.relplot(kind="scatter")等更快?)
我的首选是使用catplot(),因为我喜欢它的灵活性和在FacetGrid上简单地绘图,但是如果要花很长时间才能实现相同的绘图,那么我将直接使用轴级函数。
回答 1
Stack Overflow用户
发布于 2019-09-18 13:15:36
在catplot中,或者在FacetGrid中有很多开销,这将确保网格中的类别是同步的。例如,假设您有一个沿网格列绘制的变量,对于这些变量,并不是每个年龄组都会发生。你仍然需要证明没有出现的年龄组,并保持它的颜色。因此,彼此相邻的两个计数情节不一定构成一个小情节。
但是,如果您只对一个计数图感兴趣,那么猫图显然是过火的。另一方面,即使是一个计数图,也比一次计票的计票计谋过高。那是,
counts = df["Category"].value_counts().sort_index()
colors = plt.cm.tab10(np.arange(len(counts)))
ax = counts.plot.bar(color=colors)速度将是
ax = sns.countplot(x="Category", data=df)https://stackoverflow.com/questions/57990852
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号