
蒙特卡罗数据输入(r脚本)
有人能帮我做以下代码,这将是一个输入R遵循这些说明?:
使用R:
(a)从具有平均uniform和方差4的4分布中提取一千次,并绘制出结果值的核密度估计图(plot(density(arguments)))。(请记住,要了解R从各种发行版中提取的能力,请使用help(“Distributions”) )。同时计算样本均值和样本标准差。
(b)现在,使用10和10,000复制的样本大小,确定样本标准差(用sd()计算)对于真实标准差是否是无偏的(在本例中为2 = √4)。
(c)绘制样本标准差的密度,并就其是否看起来无偏见和是否呈正态分布作出评论。
(d)现在,增加N (如类中的示例),并确定样本标准差与实际标准差是否一致。
(e)现在,做同样的工作,以确定样本标准差看起来是否渐近正常。如果绘制√N(ˆθ − θ)的密度,而不是绘制估计量本身的密度,则估计样本标准差(或一般估计量)的渐近正态性要容易得多。N的平方根可以防止密度随着N的上升而上升到无穷大。
对于(a)部分,我假设我应该根据所给出的信息使用rnorm(1000,mean=4,sd=2),尽管我不确定这是否正确。
我也做了plot(density(replicate(n=1000,Draw.bar(rv.mean=4,rv.sd=2))))来绘制a部分,但不知道这是否正确。
然后,我会考虑使用mean(replicate(n=10000,Draw.bar(samp.size=1000,rv.mean=4,rv.sd=2)))来计算平均值,但我也不确定这是否正确。
回答 1
Stack Overflow用户
发布于 2019-09-23 22:14:11
我不介意帮助别人开始做作业,但我不会回答所有的家庭作业问题。
考虑到问题中可以理解的部分,这很可能有助于回答问题a。
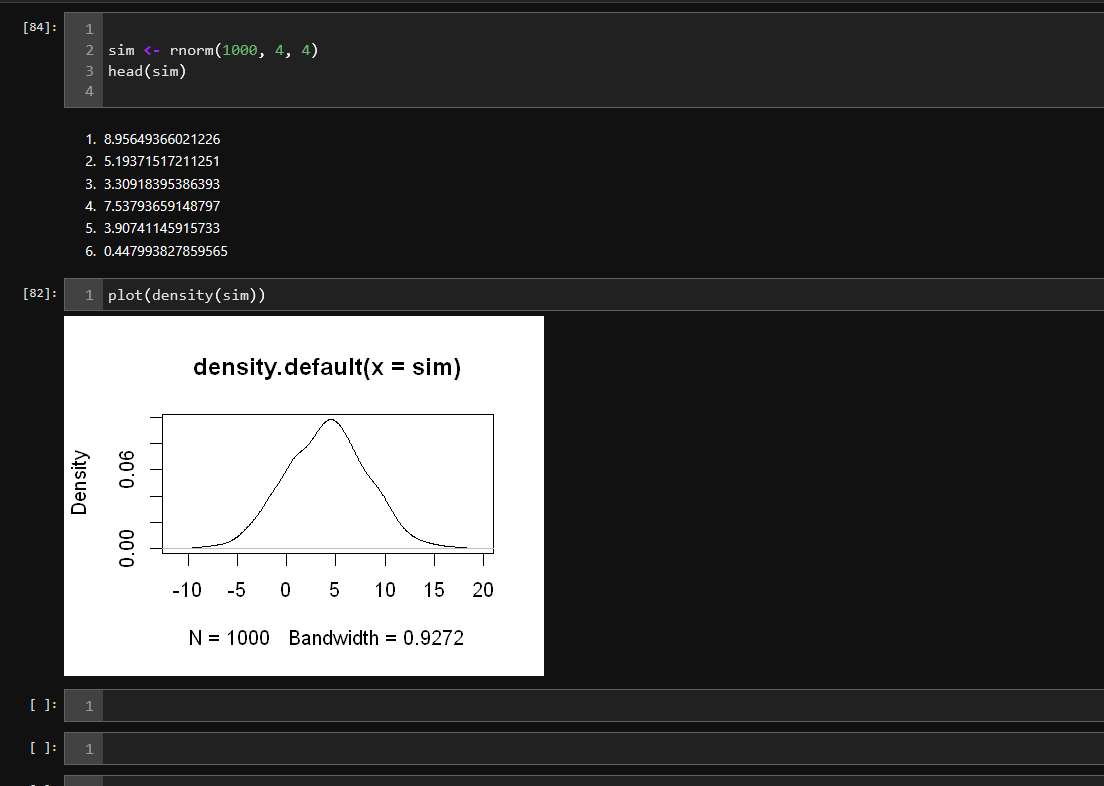
sim <- rnorm(1000, 4, 4)
head(sim)
plot(density(sim))
https://stackoverflow.com/questions/58070650
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号