
我必须将PDF文件存储在Azure Blob存储到OCR并对其进行索引吗?
我正在测试Azure搜索,以索引我的网站进行搜索。
我已经创建了一个索引,我能够从网站页面中获取信息并将其推送到索引中。
我的问题是如何索引PDF文件中的内容,包括文本,以及使用认知服务从PDF文件中的图像中提取文本。
在与索引PDF文件相关的教程中,似乎假定PDF文件位于Search (如)可访问的位置。因此,我似乎必须将我网站中已经存在的所有PDF文件存储在Azure Blob存储中(以某种方式保存它们的原始URL ),这样我就可以使用数据源索引器索引来索引它们并提取内容。
我想要寻找的功能是,您可以访问我的网站,搜索PDF文件文本或图像中的文本,作为搜索结果,您可以获得PDF文件的原始URL (而不是Azure存储URL)。
可以直接从我的网站(包括认知服务)用Azure REST索引PDF文件的内容吗?或者我必须先将这些文件放在Azure Blob存储中,如果必须这样做,我将如何保存/保存URL,以便在索引器运行和提取内容时,我可以将原始文件URL添加到索引中?
回答 1
Stack Overflow用户
发布于 2019-09-24 03:46:27
目前,Azure搜索支持以下平台作为数据源:
- Blob存储
- 表存储
- Azure Cosmos DB
- Azure SQL数据库和Azure VM上的Server
因此,如果您想要索引您的pdfs,您应该将它们存储在Azure存储中,以便Azure搜索能够精确地确定内容并对它们进行索引。
如果您想将原始文件URL包含到索引中,可以为您的pdf blob添加一个用户定义元数据,即"originalUrl":
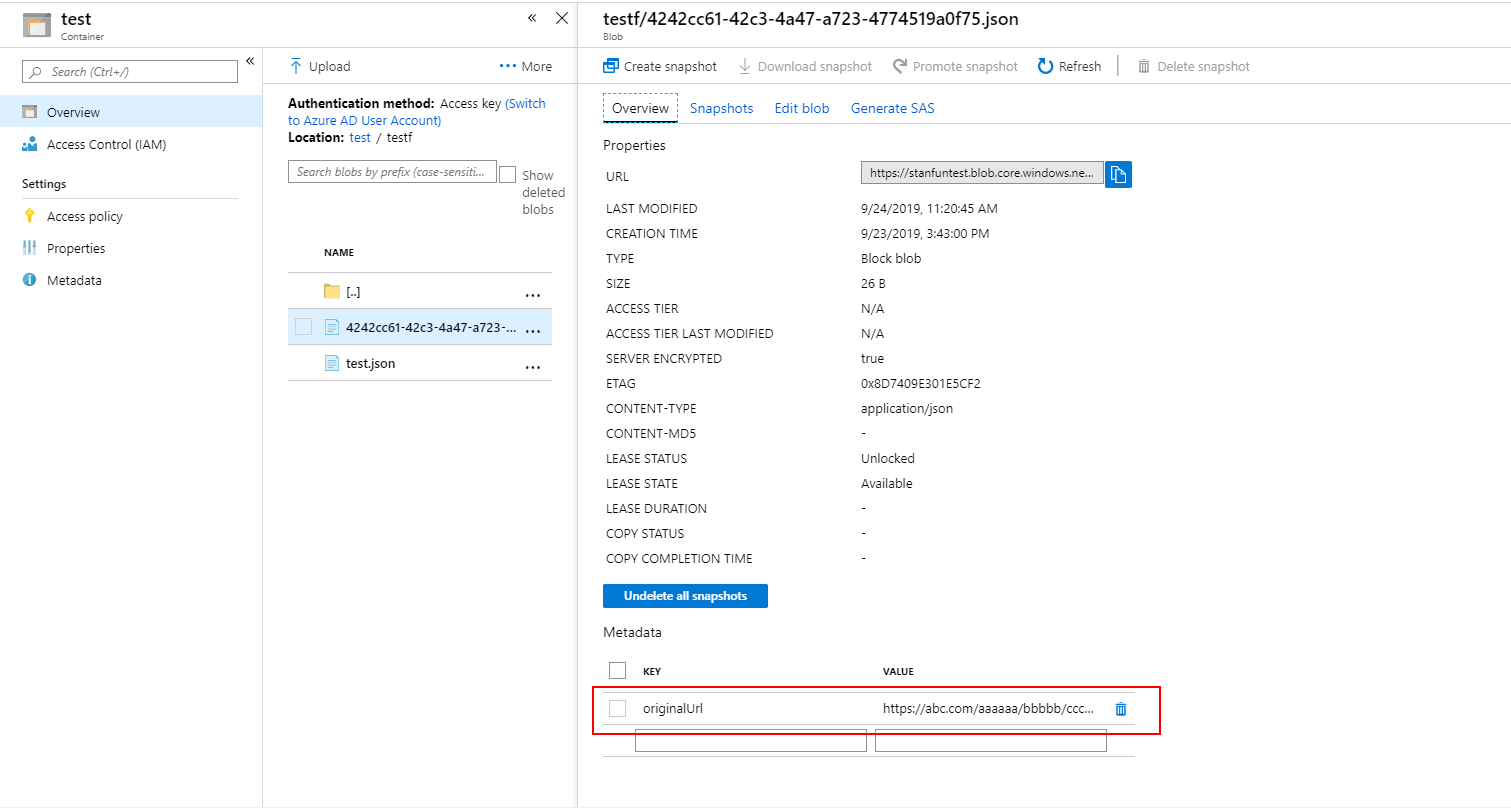
因此它将被Azure搜索索引:
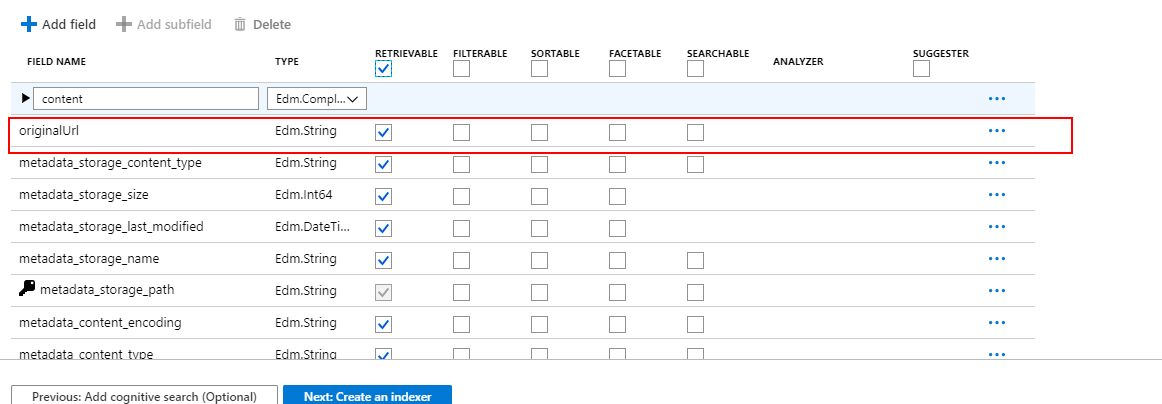
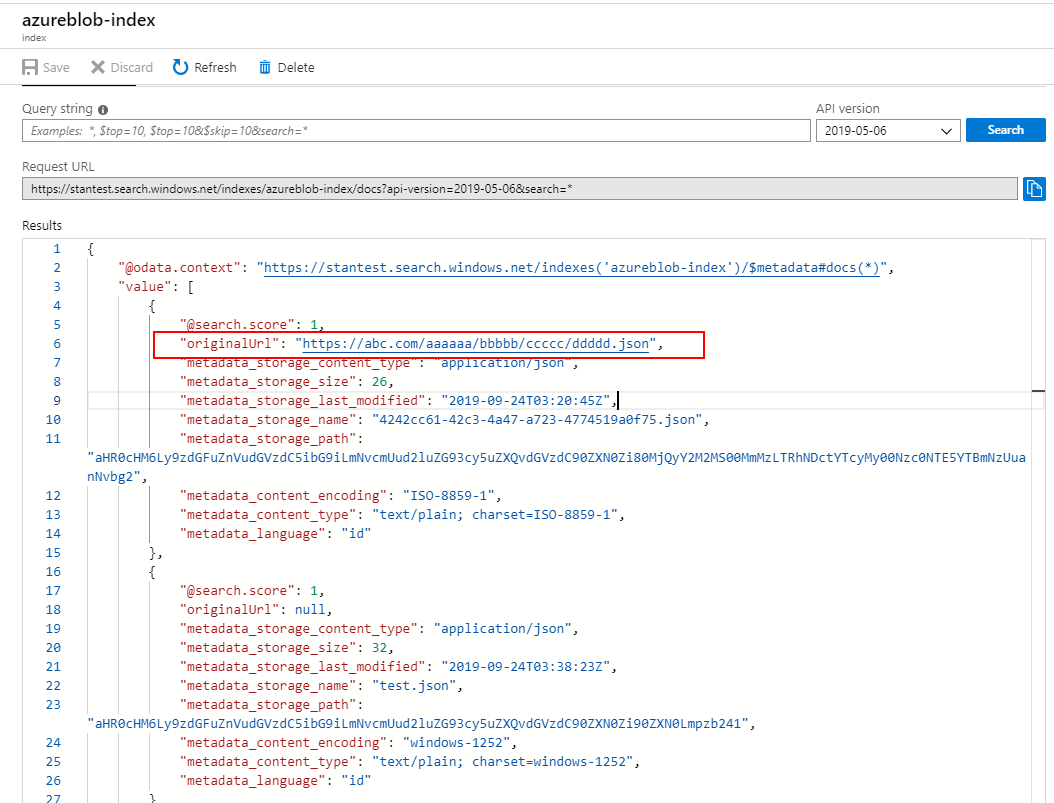
希望能帮上忙。
https://stackoverflow.com/questions/58069234
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号