
相当于google中包含的字符串
相当于google中包含的字符串
提问于 2019-10-02 08:23:56
我有一张桌子,如下所示
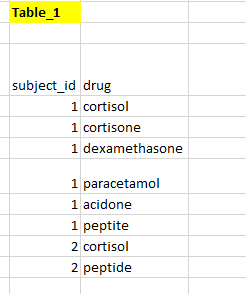
我想要创建two new binary columns,以指示主题是否具有steroids和aspirin。我希望在Postgresql and google bigquery中实现这一点。
我试过下面的方法,但不起作用
select subject_id
case when lower(drug) like ('%cortisol%','%cortisone%','%dexamethasone%')
then 1 else 0 end as steroids,
case when lower(drug) like ('%peptide%','%paracetamol%')
then 1 else 0 end as aspirin,
from db.Team01.Table_1
SELECT
db.Team01.Table_1.drug
FROM `table_1`,
UNNEST(table_1.drug) drug
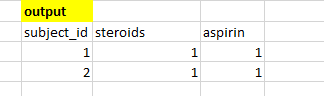
WHERE REGEXP_CONTAINS( db.Team01.Table_1.drug,r'%cortisol%','%cortisone%','%dexamethasone%')我希望我的输出如下所示
回答 5
Stack Overflow用户
回答已采纳
发布于 2019-10-02 13:04:59
下面是用于BigQuery标准SQL的
#standardSQL
SELECT
subject_id,
SUM(CASE WHEN REGEXP_CONTAINS(LOWER(drug), r'cortisol|cortisone|dexamethasone') THEN 1 ELSE 0 END) AS steroids,
SUM(CASE WHEN REGEXP_CONTAINS(LOWER(drug), r'peptide|paracetamol') THEN 1 ELSE 0 END) AS aspirin
FROM `db.Team01.Table_1`
GROUP BY subject_id 如果要应用于您的问题中的数据样本-结果是
Row subject_id steroids aspirin
1 1 3 1
2 2 1 1 注意:我使用的不是简单的(如以冗长和冗余的文本结尾),而是使用LIKE on steroids (即包含 )。
Stack Overflow用户
发布于 2019-10-02 11:34:22
在Postgres中,我建议使用filter子句:
select subject_id,
count(*) filter (where lower(drug) ~ 'cortisol|cortisone|dexamethasone') as steroids,
count(*) filter (where lower(drug) ~ 'peptide|paracetamol') as aspirin,
from db.Team01.Table_1
group by subject_id;在BigQuery中,我推荐countif()
select subject_id,
countif(regexp_contains(drug, 'cortisol|cortisone|dexamethasone') as steroids,
countif(drug ~ ' 'peptide|paracetamol') as aspirin,
from db.Team01.Table_1
group by subject_id;您可以使用sum(case when . . . end)作为一种更通用的方法。但是,每个数据库都有一种更“本地”的方式来表达这种逻辑。顺便说一句,FILTER子句是标准的SQL,只是没有被广泛采用。
Stack Overflow用户
发布于 2019-10-02 08:29:14
使用条件聚合。这是一个适用于大多数(如果不是全部)RDBMS的解决方案:
SELECT
subject_id,
MAX(CASE WHEN drug IN ('cortisol', 'cortisone', 'dexamethasone') THEN 1 END) steroids,
MAX(CASE WHEN drug IN ('peptide', 'paracetamol') THEN 1 END) aspirin
FROM db.Team01.Table_1.drug
GROUP BY subject_id注意:还不清楚为什么要使用LIKE,因为似乎您有精确的匹配;我将LIKE条件转换为相等。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58197814
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号