
如何仅用TfidfVectorizer获得TF?
我有一个类似的密码:
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'This document is the fourth document.',
'And this is the fifth one.',
'This document is the sixth.',
'And this is the seventh one document.',
'This document is the eighth.',
'And this is the nineth one document.',
'This document is the second.',
'And this is the tenth one document.',
]
vectorizer = skln.TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
tfidf_matrix = X.toarray()
accumulated = [0] * len(vectorizer.get_feature_names())
for i in range(tfidf_matrix.shape[0]):
for j in range(len(vectorizer.get_feature_names())):
accumulated[j] += tfidf_matrix[i][j]
accumulated = sorted(accumulated)[-CENTRAL_TERMS:]
print(accumulated)在这里,我打印的CENTRAL_TERMS单词,获得最高的tf-以色列国防军的分数高于所有文件的语料库。
但是,我也想在语料库的所有文档上得到MOST_REPEATED_TERMS单词。这些词的tf分数最高。我知道我可以通过简单地使用CountVectorizer获得,但是我只想使用TfidfVectorizer (为了不首先为TfidfVectorizer执行vectorizer.fit_transform(corpus),然后为CountVectorizer执行vectorizer.fit_transform(corpus) )。我还知道,我可以使用第一个CountVectorizer (获得tf分数),然后使用TfidfTransformer (获得tf-国防军分数)。但是,我认为只有使用TfidfVectorizer才能做到这一点。
如果有办法,请告诉我(欢迎提供任何信息)。
回答 2
Stack Overflow用户
发布于 2019-10-06 13:08:44
默认情况下,TfidfVectorizer在将tf和idf相乘之后执行l2规范化。因此,我们不能得到术语频率,当你有norm='l2'。参考这里和这里
如果你可以没有规范地工作,那么就有一个解决办法。
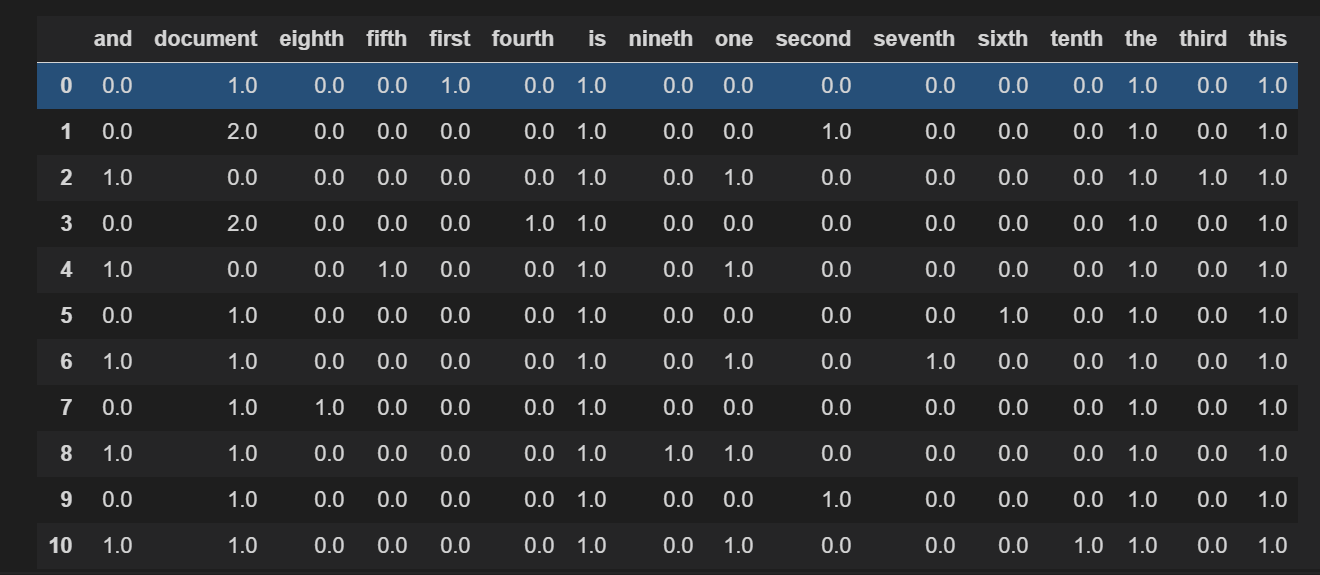
import scipy.sparse as sp
import pandas as pd
vectorizer = TfidfVectorizer(norm=None)
X = vectorizer.fit_transform(corpus)
features = vectorizer.get_feature_names()
n = len(features)
inverse_idf = sp.diags(1/vectorizer.idf_,
offsets=0,
shape=(n, n),
format='csr',
dtype=np.float64).toarray()
pd.DataFrame(X*inverse_idf,
columns=features)
Stack Overflow用户
发布于 2019-10-05 13:39:57
你可以这样做你的工作
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'This document is the fourth document.',
'And this is the fifth one.',
'This document is the sixth.',
'And this is the seventh one document.',
'This document is the eighth.',
'And this is the nineth one document.',
'This document is the second.',
'And this is the tenth one document.',
]
#define the vectorization model
vectorize = TfidfVectorizer (max_features=2500, min_df=0.1, max_df=0.8)
#pass the corpus into the defined vectorizer
vector_texts = vectorize.fit_transform(corpus).toarray()
vector_texts- 您必须更改
max_features, min_df, max_df值,以便最适合您的model.In情况。
out[1]:
array([[0. , 0. , 0. ],
[0. , 0. , 1. ],
[0.70710678, 0.70710678, 0. ],
[0. , 0. , 0. ],
[0.70710678, 0.70710678, 0. ],
[0. , 0. , 0. ],
[0.70710678, 0.70710678, 0. ],
[0. , 0. , 0. ],
[0.70710678, 0.70710678, 0. ],
[0. , 0. , 1. ],
[0.70710678, 0.70710678, 0. ]])https://stackoverflow.com/questions/58248692
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号