
“美丽的汤”查找()并不能找到类的所有结果
我有代码试图在tracklist容器中提取所有html内容,它应该有88首歌曲。信息肯定在那里(我打印了汤以检查),所以我不知道为什么前30 react-contextmenu-wrapper之后的所有东西都丢失了。
from bs4 import BeautifulSoup
from urllib.request import urlopen
import re
spotify = 'https://open.spotify.com/playlist/3vSFv2hZICtgyBYYK6zqrP'
html = urlopen(spotify)
soup = BeautifulSoup(html, "html5lib")
main = soup.find(class_ = 'tracklist-container')
print(main)谢谢你的帮助。目前印刷的输出如下:
1.
</div></div><div class="tracklist-col name"><div class="top-align track-name-wrapper"><span class="track-name" dir="auto">Move On - Teen Daze Remix</span><span class="artists-albums"><a href="/artist/3HrczLBDJXJu6dJWEMbKHa" tabindex="-1"><span dir="auto">Garden City Movement</span></a> • <a href="/album/4p8FxnuYzykCcN7xbjA9jq" tabindex="-1"><span dir="auto">Entertainment</span></a></span></div></div><div class="tracklist-col explicit"></div><div class="tracklist-col duration"><div class="top-align"><span class="total-duration">5:11</span><span class="preview-duration">0:30</span></div></div><div class="progress-bar-outer"><div class="progress-bar"></div></div></li><li class="tracklist-row js-track-row tracklist-row--track track-has-preview" data-position="2" role="button" tabindex="0"><div class="tracklist-col position-outer"><div class="play-pause top-align"><svg aria-label="Play" class="svg-play" role="button"><use xlink:href="#icon-play" xmlns:xlink="http://www.w3.org/1999/xlink"></use></svg><svg aria-label="Pause" class="svg-pause" role="button"><use xlink:href="#icon-pause" xmlns:xlink="http://www.w3.org/1999/xlink"></use></svg></div><div class="tracklist-col__track-number position top-align">
2.
</div></div><div class="tracklist-col name"><div class="top-align track-name-wrapper"><span class="track-name" dir="auto">Flicker</span><span class="artists-albums"><a href="/artist/4qpWUfUAeI34HzvCORn1ze" tabindex="-1"><span dir="auto">Forhill</span></a> • <a href="/album/0gfz1Tbst40swwL357cRqG" tabindex="-1"><span dir="auto">Flicker</span></a></span></div></div><div class="tracklist-col explicit"></div><div class="tracklist-col duration"><div class="top-align"><span class="total-duration">3:45</span><span class="preview-duration">0:30</span></div></div><div class="progress-bar-outer"><div class="progress-bar"></div></div></li><li class="tracklist-row js-track-row tracklist-row--track track-has-preview" data-position="3" role="button" tabindex="0"><div class="tracklist-col position-outer"><div class="play-pause top-align"><svg aria-label="Play" class="svg-play" role="button"><use xlink:href="#icon-play" xmlns:xlink="http://www.w3.org/1999/xlink"></use></svg><svg aria-label="Pause" class="svg-pause" role="button"><use xlink:href="#icon-pause" xmlns:xlink="http://www.w3.org/1999/xlink"></use></svg></div><div class="tracklist-col__track-number position top-align">..。
30.
</div></div><div class="tracklist-col name"><div class="top-align track-name-wrapper"><span class="track-name" dir="auto">Trapdoor</span><span class="artists-albums"><a href="/artist/3nqTFzjmi1LLM6pn0TRMv8" tabindex="-1"><span dir="auto">Eagle Eyed Tiger</span></a> • <a href="/album/48Q8Jgk1x4wiHWecV4nlz6" tabindex="-1"><span dir="auto">Future or Past</span></a></span></div></div><div class="tracklist-col explicit"></div><div class="tracklist-col duration"><div class="top-align"><span class="total-duration">4:14</span><span class="preview-duration">0:30</span></div></div><div class="progress-bar-outer"><div class="progress-bar"></div></div></li></ol><button class="link js-action-button" data-track-type="view-all-button">View all on Spotify</button></div>最后一项应该是88。感觉我的搜索结果被截断了。
回答 3
Stack Overflow用户
发布于 2019-10-06 05:10:36
所有这些都在响应中,就在脚本标记中。
您可以在这里看到相关javascript对象的开始:
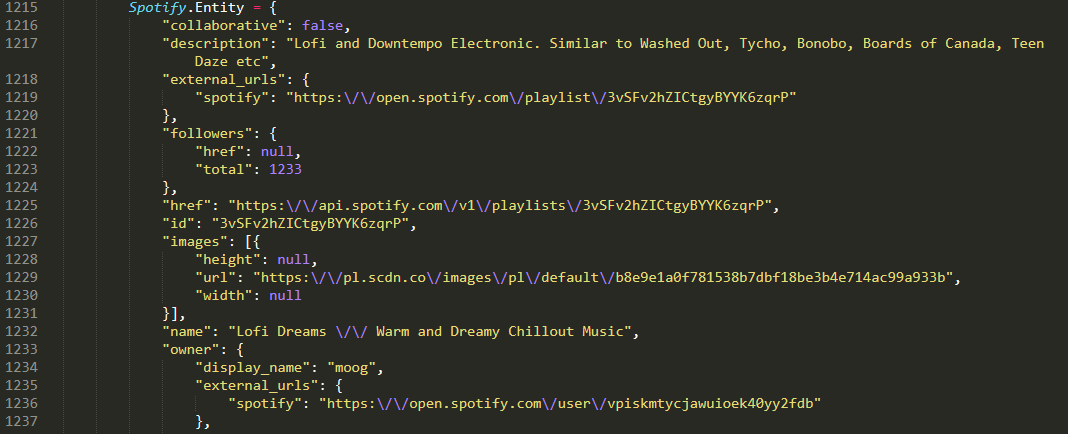
我将正则化所需的字符串,并使用json库进行解析。
Py:
import requests, re, json
r = s.get('https://open.spotify.com/playlist/3vSFv2hZICtgyBYYK6zqrP')
p = re.compile(r'Spotify\.Entity = (.*?);')
data = json.loads(p.findall(r.text)[0])
print(len(data['tracks']['items']))Stack Overflow用户
发布于 2019-10-05 22:44:22
因为你似乎是在正确的轨道上,我并没有试图解决整个问题,而是试图给你一个提示,这可能是有帮助的:做动态网络抓取。
“为什么是硒?漂亮的汤还不够吗?
使用Python进行Web抓取通常只需要使用“美丽汤”来达到目标。美丽的Soup是一个非常强大的库,它通过遍历DOM ()使web抓取更容易实现。但它只做静态刮擦。静态抓取忽略JavaScript。它在不需要浏览器帮助的情况下从服务器获取网页。您得到了在“查看页面源”中所看到的内容,然后对其进行切片和剪裁。如果您正在寻找的数据仅在“查看页面源”中可用,则不需要进一步研究。但是,如果您需要在单击JavaScript链接时呈现的组件中存在的数据,动态抓取就可以拯救您了。“美汤”与“硒”的结合,将成为一项动态刮刮的工作。Selenium使网页浏览器与python的交互自动化。因此,JavaScript链接呈现的数据可以通过使用Selenium自动单击按钮来获得,然后可以由Beautiful提取。
下面是我在DOM中的30首歌曲的末尾所看到的,它指的是一个按钮:
</li>
</ol>
<button class="link js-action-button" data-track-type="view-all-button">
View all on Spotify
</button>
</div>Stack Overflow用户
发布于 2019-10-05 21:24:21
是因为你在做
main = soup.find(class_ = 'tracklist-container')类“tracklist-容器”只包含这30项,我不确定您想要完成什么,但是如果您想要后面的内容,请尝试在以后解析类。
换句话说,这个课程包含30首歌曲,我访问了这个网站,找到了30首歌曲,所以它可能只适用于登录用户。
https://stackoverflow.com/questions/58252389
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号