
基于Tesseract python的数字识别
基于Tesseract python的数字识别
提问于 2019-10-08 07:10:08
对于我正在进行的一个项目,我试图使用OCR检测食品托盘图像上的数字。为此,我在python中使用了Tesseract 4。但它无法正确地检测到我所拥有的大多数图像的数字。利用OpenCV对图像进行模糊、阈值、锐化、冲蚀、膨胀等多种图像预处理,提高了图像的处理精度。但似乎什么都起不到作用。我是计算机视觉新手,所以任何建议或替代的解决方案都会有很大的帮助。我已经在下面的链接中附加了这些图片。提前谢谢。
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-10-10 04:09:51
您需要一个更强的文本检测,这将裁剪文本候选区域为您。
处理过程将更加复杂,如下所示:
- 运行文本检测,获取文本候选区域。
- 提取那个区域
- 使用tesseract阅读文本
在OpenCV的DNN模块中,有一个很好的文本检测脚本,称为:detection.py,它使用的是EAST文本检测。使用您的示例图像,我可以提取以下绿色矩形文本候选区域。接下来的步骤是上面的步骤2和3。

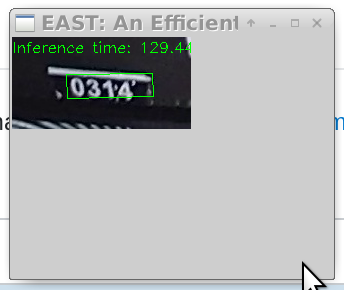
当然,东方没有为你的场景训练,所以100%的准确性是不可能的。您可以尝试收集数据并为您的场景向东进行培训。但我认为,默认的一个会给你90%以上的准确性。
希望能帮上忙。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58281656
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号