
如何评价xgboost分类模型的稳定性
我有:
- Python分类模型
- Weekly数据集(分类的基础)自2018年开始。每个数据集都有大约10万行和70列,(features).
- weekly预测结果通过xgboost模型(使用逻辑回归)以
格式在数据集上进行。
- date of modelling
- items
- test_auc_mean for each item (in percentage).自2018年1月以来,总共有100个数据集和100个prediction_results。
为了评估模型,我使用了以下度量标准:
-auc
-confusion矩阵
-accuracy
param = {
'num_parallel_tree':num_parallel_tree,
'subsample':subsample,
'colsample_bytree':colsample_bytree,
'objective':objective,
'learning_rate':learning_rate,
'eval_metric':eval_metric,
'max_depth':max_depth,
'scale_pos_weight':scale_pos_weight,
'min_child_weight':min_child_weight,
'nthread':nthread,
'seed':seed
}
bst_cv = xgb.cv(
param,
dtrain,
num_boost_round=n_estimators,
nfold = nfold,
early_stopping_rounds=early_stopping_rounds,
verbose_eval=verbose,
stratified = stratified
)
test_auc_mean = bst_cv['test-auc-mean']
best_iteration = test_auc_mean[test_auc_mean == max(test_auc_mean)].index[0]
bst = xgb.train(param,
dtrain,
num_boost_round = best_iteration)
best_train_auc_mean = bst_cv['train-auc-mean'][best_iteration]
best_train_auc_mean_std = bst_cv['train-auc-std'][best_iteration]
best_test_auc_mean = bst_cv['test-auc-mean'][best_iteration]
best_test_auc_mean_std = bst_cv['test-auc-std'][best_iteration]
print('''XGB CV model report
Best train-auc-mean {}% (std: {}%)
Best test-auc-mean {}% (std: {}%)'''.format(round(best_train_auc_mean * 100, 2),
round(best_train_auc_mean_std * 100, 2),
round(best_test_auc_mean * 100, 2),
round(best_test_auc_mean_std * 100, 2)))
y_pred = bst.predict(dtest)
tn, fp, fn, tp = confusion_matrix(y_test, y_pred>0.9).ravel()
print('''
| neg | pos |
__________________
true_| {} | {} |
false| {} | {} |
__________________
'''.format(tn, tp, fn, fp))
predict_accuracy_on_test_set = (tn + tp)/(tn + fp + fn + tp)
print('Test Accuracy: {}%'.format(round(predict_accuracy_on_test_set * 100, 2)))该模型给我提供了总体情况(通常情况下,auc介于.94和.96之间),问题是某些特定项目预测的变异性很高(今天一个项目是正的,明天一个项目是负的,后天是正的)。
我想要评估模型的稳定性。换句话说,我想知道,它产生了多少个具有可变结果的项目。最后,我想要确保,该模型将产生稳定的结果,最小的波动。你有什么想法怎么做吗?
回答 2
Stack Overflow用户
发布于 2019-10-08 14:56:16
这正是交叉验证的目标。既然您已经这样做了,您只能评估您的评估指标的标准差,您已经这样做了。
- --您可以尝试一些新的度量标准,如精确性、召回性、f1评分或fn评分,以不同的方式衡量成功和失败,但看起来您的解决方案几乎已经用完了。您依赖于这里的数据输入:s
- 您可以花一些时间来培训人口分布,并尝试确定人口的哪一部分随着时间的推移而波动。
- 您也可以尝试预测proba,而不是分类,以评估模型是否远远超过其阈值。
最后两种解决方案更像是边解。:(
Stack Overflow用户
发布于 2019-10-09 06:53:58
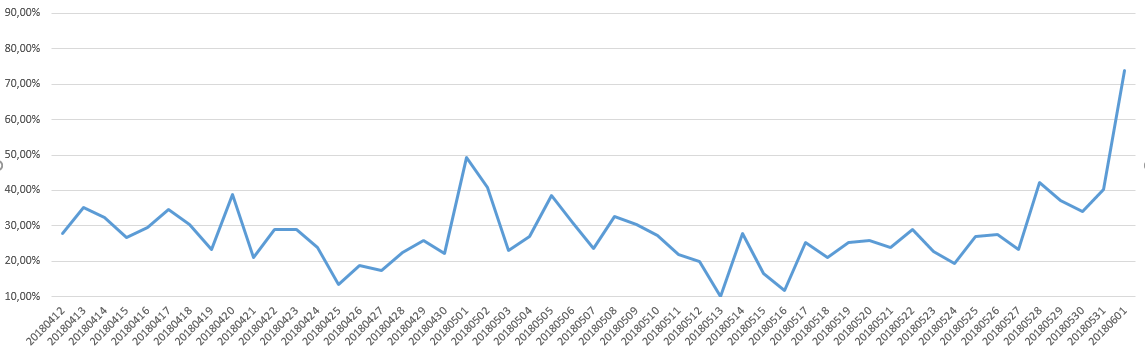
格温德尔谢谢你。你能说明你提到的两种方法吗?( 1)如何训练人口分布?通过K-聚类或其他无监督学习的方法? 2)例如I predicted_proba (一个特定项目的图表-在攻击中)。如何评估该模型是否远远超过其阈值?通过比较每个项目的predicted_proba与它的真标号(例如predict_proba = 0.5和label = 1)?
https://stackoverflow.com/questions/58288868
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号