
共享的检查点非常大。
共享的检查点非常大。
提问于 2019-10-14 08:16:08
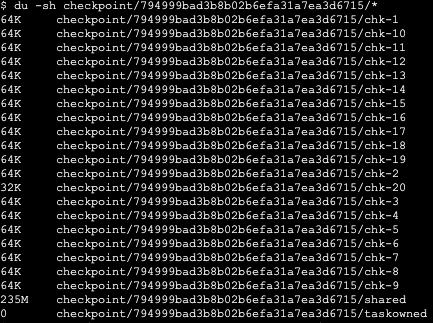
我运行我的flink应用程序与16并行。20分钟后,共享检查点增加到235 to。我该怎么处理呢。很长一段时间都很大。
每个任务管理器都是一个Openshift Pod
- 任务管理器:每个任务管理器4个
- 任务:每个任务管理器4个
- CPU:每个任务管理器4个Core
<代码>H19内存:6GBH 210H 111使用的manager(Pod)状态manager(Pod)图像。
回答 1
Stack Overflow用户
发布于 2019-10-14 12:59:15
Flink将只使用所需的状态空间来完成您要求它做的事情。如果你对结果不满意,你需要让它少做一些。
在这里,你可能会做一些事情:
- 确保您的应用程序没有泄漏状态。例如,如果您使用键控状态和无界密钥空间,并且没有清除状态保留间隔(对于表/SQL),则可能发生这种情况。
- 使用状态TTL释放不需要的状态。
有些反模式需要在状态下进行大量缓冲。你应该避免那样做。:)
您可以限制用于存储状态的可用资源,但这将导致作业在耗尽这些资源时失败。
而且,对于RocksDB来说,跨越16个时隙的235 16并不是很大。使用增量检查点,RocksDB存储状态的多个(未压缩)副本。您使用的实际活动状态可能要少得多。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58372636
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号