
Databricks只打印280行数据。
我在Databricks中运行一些大型作业,目前包括对数据湖进行清点。我试图在一个前缀(子文件夹)中打印所有的blob名称。在这些子文件夹中有很多文件,我得到了大约280行的文件名,但是我看到了这个:*** WARNING: skipped 494256 bytes of output ***,然后,我又打印了280行。
我猜是有一个控制装置来改变这个的,对吧。我当然希望如此。这是设计用来处理大数据,而不是280条记录。我知道巨大的数据集很容易使浏览器崩溃,但是很常见,这基本上是没有意义的。
回答 2
Stack Overflow用户
发布于 2019-10-30 11:18:12
注意:使用,您可以下载完整的结果(最多100万行)。
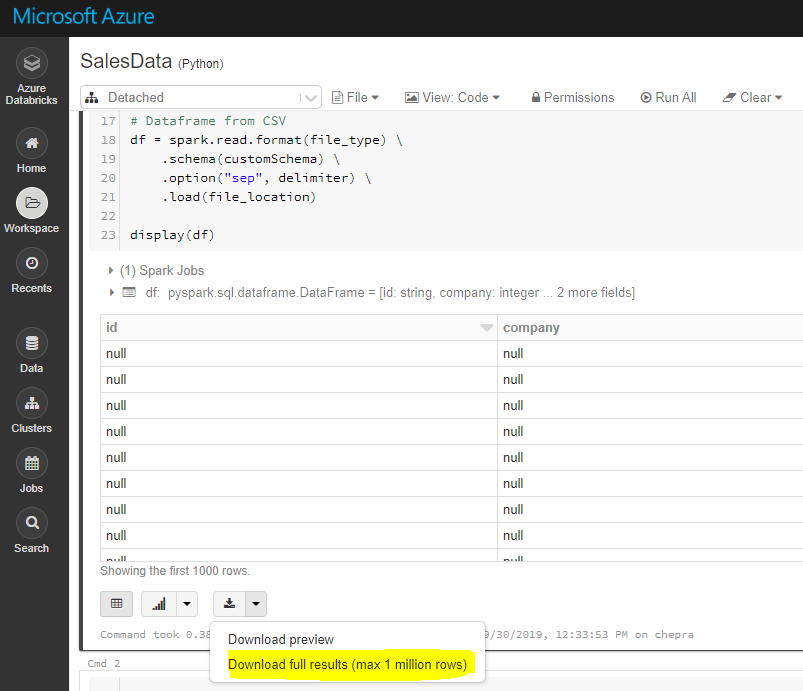
要下载完整的结果(超过100万),首先将文件保存到dbfs,然后使用Databricks cli将文件复制到本地机器,如下所示。
dbfs cp“dbfs:/FileStore/table/AA.csv”"A:\AzureAnalytics“
参考: 数据库文件系统
DBFS命令行接口(CLI)使用DBFS向DBFS公开一个易于使用的命令行接口。使用此客户端,您可以使用类似于Unix命令行中使用的命令与DBFS交互。例如:
# List files in DBFS
dbfs ls
# Put local file ./apple.txt to dbfs:/apple.txt
dbfs cp ./apple.txt dbfs:/apple.txt
# Get dbfs:/apple.txt and save to local file ./apple.txt
dbfs cp dbfs:/apple.txt ./apple.txt
# Recursively put local dir ./banana to dbfs:/banana
dbfs cp -r ./banana dbfs:/banana参考: 安装和配置Azure数据库CLI
希望这能有所帮助。
Stack Overflow用户
发布于 2019-10-15 13:15:04
经过进一步的研究,我偶然发现了一些对我有用的东西。
而且,这将显示数据格式的内容,
display(df)因此,这将生成您在上面看到的视图。
https://stackoverflow.com/questions/58386830
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号