
单通计算与多通计算的区别
回答 2
Stack Overflow用户
发布于 2019-10-16 08:23:46
地图缩减
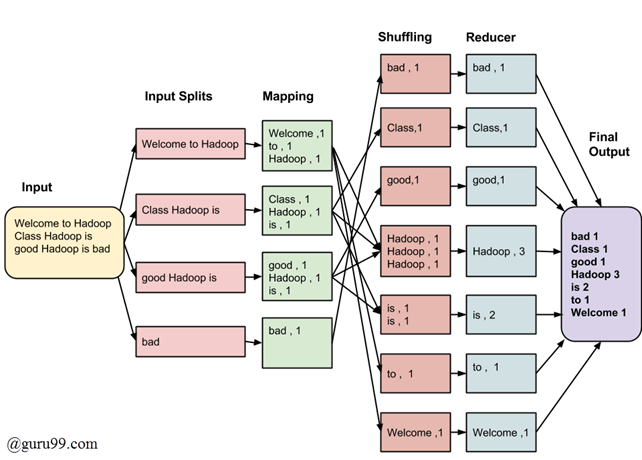
来源:https://www.guru99.com/introduction-to-mapreduce.html
在这里您可以看到,输入文件按以下方式处理。
- 首次分裂
- 进入映射阶段
- 洗牌
- 减速器
在Map-约简范式中,在每个阶段之后,中间结果被写入磁盘。另外,Mapper和Reducer是两个不同的过程。也就是说,首先,mapper作业运行,然后释放映射文件,然后启动还原作业。在每个阶段,作业都需要资源分配。因此,一个单一的映射-减少作业需要多次迭代。如果您有多个映射阶段,则在每个映射之后,需要在其他映射任务开始之前将数据吐出磁盘。这是多步过程.
数据处理工作流中的每一步都有一个Map阶段和一个缩减阶段,您需要将任何用例转换为MapReduce模式以利用此解决方案。
火花
另一方面,星火只进行一次资源协商。一旦谈判完成,它就会产生所有的执行者,并在整个任期内保留下来。在执行过程中,spark不会将Map阶段的中间输出写入磁盘,而是保存在内存中。因此,所有映射操作都可以在不写入磁盘或生成新的执行程序的情况下背靠背进行。这是一个步骤过程。
星火允许程序员使用有向无环图(DAG)模式开发复杂的多步骤数据管道.它还支持跨DAG之间的内存中数据共享,以便不同的作业可以处理相同的数据。
Stack Overflow用户
发布于 2019-10-16 08:11:39
一次传递计算是当您读取数据集一次时,而多通计算是指从磁盘读取一次数据集,并且在同一数据集上进行多次计算或操作。Apache处理框架允许您读取数据一次,然后将其缓存到内存中,然后我们可以对数据执行多次传递计算。这些计算可以在dataset上快速完成,因为数据被显示在机器的内存中,而且apache不需要再次从磁盘读取数据,这有助于我们节省大量的输入输出操作时间。根据apache的定义,它是一个内存处理框架,这意味着计算所用的数据和转换在内存本身中。
https://stackoverflow.com/questions/58407978
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号