
如何提取特定类名和特定文本的文本?
如何提取特定类名和特定文本的文本?
提问于 2019-10-26 11:58:38
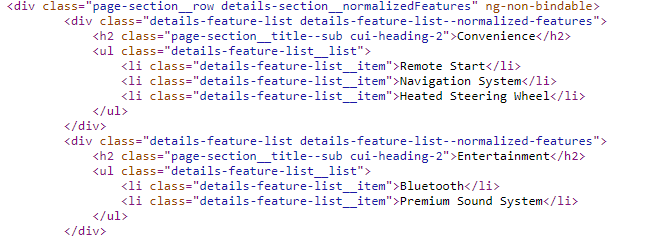
我试图使用Python中的BeautifulSoup收集webdata数据。我正专门尝试提取不同类型的汽车特征。例如,在下面粘贴的html代码中,我试图提取“远程启动”、“导航系统”和“加热方向盘”作为“方便”功能。有谁能告诉我如何提取和存储每个这类类别的特征吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-10-26 12:14:46
以下是一种方法:
import bs4
your_source_code = "<html>..."
soup = bs4.BeautifulSoup(your_source_code, "html.parser")
result = {}
for group in soup.find_all("div", {"class": "details-feature-list--normalized-features"}):
result[group.find("h2", {"class": "cui-heading-2"}).text] = [itm.text for itm in group.find_all("li", {"class": "details-feature-list__item"})]结果是这样的:
{"Convenience": ["Remote Start", "Navigation System", "Heated Steering Wheel"]}
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58570551
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号