
带有流水线hgetall的Redis慢速查询
所以我有一个小而简单的Redis数据库。它包含136689个键,其值是包含27个字段的散列映射。我正在通过服务器节点上的Python接口访问表,每次调用需要加载大约1000-1500个值(最终我将看到每秒大约10个请求)。一个简单的呼叫看起来如下所示:
# below keys is a list of approximately 1000 integers,
# not all of which are in the table
import redis
db = redis.StrictRedis(
host='127.0.0.1',
port=6379,
db=0,
socket_timeout=1,
socket_connection_timeout=1,
decode_responses=True
)
with db.pipeline() as pipe:
for key in keys:
pipe.hgetall(key)
results = zip(keys,pipe.execute())总的时间为328 is,每次请求的平均时间为0.25ms。
问题:对于一个小型数据库来说非常慢,而且每秒的查询相对较少。我的配置或调用服务器的方式有问题吗?能做点什么让这件事更快吗?我不认为这张桌子会变大,所以我很高兴为了速度而牺牲磁盘空间。
更多信息
在每个键上调用hget (没有管道)要慢(正如预期的那样),并且显示时间分布是双峰的。较小的峰值对应于不在表中的键,较大的对应于表中的键。
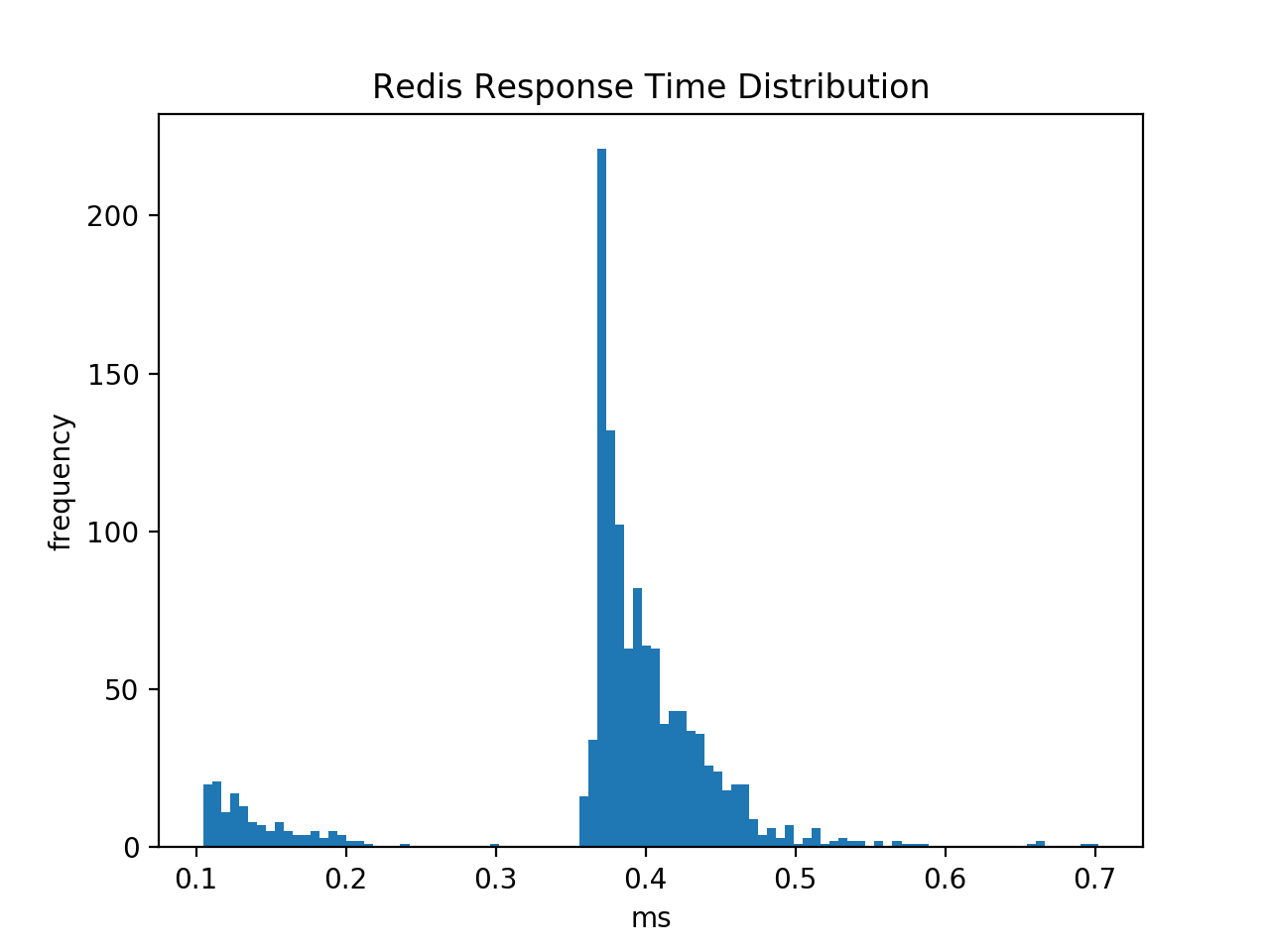
我的conf文件如下:
port 6379
daemonize yes
save ""
bind 127.0.0.1
tcp-keepalive 300
dbfilename mytable.rdb
dir .
rdbcompression yes
appendfsync no
no-appendfsync-on-rewrite yes
loglevel notice我启动服务器时:
> echo never > /sys/kernel/mm/transparent_hugepage/enabled
> redis-server myconf.conf我还使用redis-cli --intrinsic-latency 100度量了内部延迟,它提供:
Max latency so far: 1 microseconds.
Max latency so far: 10 microseconds.
Max latency so far: 11 microseconds.
Max latency so far: 12 microseconds.
Max latency so far: 18 microseconds.
Max latency so far: 32 microseconds.
Max latency so far: 34 microseconds.
Max latency so far: 38 microseconds.
Max latency so far: 48 microseconds.
Max latency so far: 52 microseconds.
Max latency so far: 60 microseconds.
Max latency so far: 75 microseconds.
Max latency so far: 94 microseconds.
Max latency so far: 120 microseconds.
Max latency so far: 281 microseconds.
Max latency so far: 413 microseconds.
Max latency so far: 618 microseconds.
1719069639 total runs (avg latency: 0.0582 microseconds / 58.17 nanoseconds per run).
Worst run took 10624x longer than the average latency.这表明我应该能够获得更好的延迟。但是,当我使用:> redis-cli --latency -h 127.0.0.1 -p 6379检查服务器延迟时,我得到了min: 0, max: 2, avg: 0.26 (2475 samples)
这似乎表明,~0.25ms是我的服务器的延迟,但这似乎表明,我从Python看到的每个请求的延迟与CLI相同,但似乎都非常慢。
与每个键相关联的哈希映射(解码后)的大小为1200字节。所以我运行了下面的基准测试
redis-benchmark -h 127.0.0.1 -p 6379 -d 1500 hmset hgetall myhash rand_int rand_string
====== hmset hgetall myhash rand_int rand_string ======
100000 requests completed in 1.45 seconds
50 parallel clients
1500 bytes payload
keep alive: 1
100.00% <= 1 milliseconds
100.00% <= 1 milliseconds
69060.77 requests per second这似乎支持我的延迟非常高,但并没有真正告诉我为什么。
回答 1
Stack Overflow用户
发布于 2020-04-23 21:55:55
我从使用Redis的方式中得出的一个结论是,我们不应该将每个事务存储在一个散列中。就像在一个事务中一样,一个散列。
对于每个hget请求,我们都有一个网络连接,它正在减缓查询速度。
我认为Redis的设计方式将更快地将所有内容存储在一个散列中,就像在同一哈希下的所有事务中一样。
此外,粒度数据可以存储在每个键中:值作为JSON。
检索所有散列的时间与检索存储在一个散列中的所有值的时间相比,对于140 of值的数据而言:
迭代每个散列并获取其键的
- 3秒:值vs
- 0,008秒,用于获取一个散列,然后搜索一个键:该哈希内的值: vs
- 0,008秒,以获取存储在一个散列下的所有数据。
与其在for迭代中有1000 000 000次迭代(如果您有1 000 000次散列),在这里,在建议的解决方案中,您只有1次(如果可以根据内在值分隔数据的话,则更多),因此大大减少了查询时间。
https://stackoverflow.com/questions/58651785
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号