
CDAP源插件从Sftp服务器读取数据
CDAP源插件从Sftp服务器读取数据
提问于 2019-11-04 06:30:55
我想通过使用cdap源代码插件来读取Sftp服务器可用的csv文件。
我偶然发现FTP批处理源插件也是如此。但是,在运行这个程序时,我会遇到异常。
Caused by: java.io.IOException: No FileSystem for scheme: sftp
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2798) ~[org.apache.hadoop.hadoop-common-2.8.0.jar:na]
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2809) ~[org.apache.hadoop.hadoop-common-2.8.0.jar:na]
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:100) ~[org.apache.hadoop.hadoop-common-2.8.0.jar:na]
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2848) ~[org.apache.hadoop.hadoop-common-2.8.0.jar:na]
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2830) ~[org.apache.hadoop.hadoop-common-2.8.0.jar:na]
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:389) ~[org.apache.hadoop.hadoop-common-2.8.0.jar:na]
at co.cask.hydrator.format.plugin.AbstractFileSource.prepareRun(AbstractFileSource.java:129) ~[na:na]
at co.cask.hydrator.format.plugin.AbstractFileSource.prepareRun(AbstractFileSource.java:63) ~[na:na]
at co.cask.cdap.etl.common.plugin.WrappedBatchSource$1.call(WrappedBatchSource.java:53) ~[na:na]
at co.cask.cdap.etl.common.plugin.WrappedBatchSource$1.call(WrappedBatchSource.java:50) ~[na:na]
at co.cask.cdap.etl.common.plugin.Caller$1.call(Caller.java:30) ~[na:na]
at co.cask.cdap.etl.common.plugin.StageLoggingCaller.call(StageLoggingCaller.java:40) ~[na:na]
at co.cask.cdap.etl.common.plugin.WrappedBatchSource.prepareRun(WrappedBatchSource.java:50) ~[na:na]
at co.cask.cdap.etl.common.plugin.WrappedBatchSource.prepareRun(WrappedBatchSource.java:36) ~[na:na]
at co.cask.cdap.etl.common.plugin.WrappedBatchSource$1.call(WrappedBatchSource.java:53) ~[na:na]
at co.cask.cdap.etl.common.plugin.WrappedBatchSource$1.call(WrappedBatchSource.java:50) ~[na:na]
at co.cask.cdap.etl.common.plugin.Caller$1.call(Caller.java:30) ~[na:na]
at co.cask.cdap.etl.common.plugin.StageLoggingCaller.call(StageLoggingCaller.java:40) ~[na:na]
at co.cask.cdap.etl.common.plugin.WrappedBatchSource.prepareRun(WrappedBatchSource.java:50) ~[na:na]
at co.cask.cdap.etl.common.plugin.WrappedBatchSource.prepareRun(WrappedBatchSource.java:36) ~[na:na]
at co.cask.cdap.etl.common.submit.SubmitterPlugin$3.run(SubmitterPlugin.java:83) ~[na:na]
at co.cask.cdap.internal.app.runtime.AbstractContext$2.run(AbstractContext.java:534) ~[na:na]
at co.cask.cdap.data2.transaction.Transactions$CacheBasedTransactional.finishExecute(Transactions.java:224) ~[na:na]
... 18 common frames omitted我正在使用以下版本的图书馆,这也是一个限制。
Hadoop - 2.7.3Spark - 2.3.0
我还遇到了这问题,它建议使用这并将proeprty fs.sftp.impl设置为org.apache.hadoop.fs.sftp.SFTPFileSystem将解决这个问题,但不确定如何使用上述代码并设置这个proeprty。
回答 2
Stack Overflow用户
发布于 2019-11-05 23:48:29
使用SFTP作为协议时,需要在Advanced部分下设置文件系统属性:
{
"fs.sftp.impl": "org.apache.hadoop.fs.sftp.SFTPFileSystem"
}Stack Overflow用户
发布于 2022-04-11 10:15:09
对于我的理解,FTP插件是不可取的。改用SFTP动作插件,并构建如下管道:
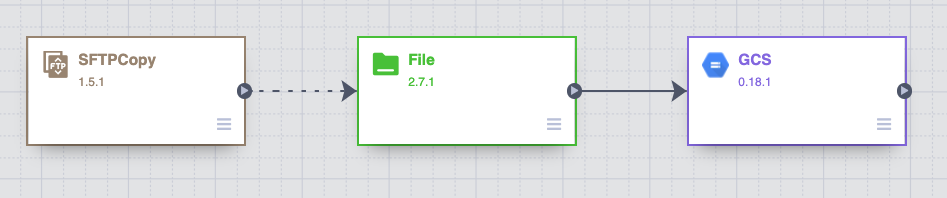
其想法是首先将文件复制到运行时环境的本地文件系统,然后在您想要的地方接收该文件(在我的例子中是GCS)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58688246
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号