
用OpenCV + Python拼接四幅图像
目标:
在过去的两周里,我一直在试图找出如何转换以下图像:

对于一个看起来像这样的人(可能不完全匹配,因为这个图像是在不同的时间拍摄的):

镜片矫正(必要?):
我注意到的第一件事是,简单地切片图像和覆盖这四个部分并不完美,因为某些线条的曲率不匹配。例如,中场线在第二层向左弯曲,在第三层向右弯曲.这个弯曲看起来像一个桶形畸变,所以我尝试使用参数化的透镜校正函数(将k1、k2和k3传递给OpenCV)和使用伦斯芬。由于伦斯芬数据库不包括我的相机制作或型号(这是一个轴向相机),而且我也不知道镜头的制作或模型(它是作为相机的一部分制造的),所以我编写了一个小脚本,使用各种参数的镜头来转储测试图像,然后浏览数千的输出图像,直到我找到一个看起来相对直线的图像:

这一校正是使用"Samyang 12 in f/2.8鱼眼ED作为NCS“镜头与”佳能EOS 10D“相机在透镜。它可能不是完美的,但我想它已经足够接近第二步了。
一旦镜头畸变被纠正,第二个问题是两片中的同一行指向不同的方向,这应该用一个简单的透视变换来校正。因此,我开始了一个长期的探索,为这个透视图转换找出合适的参数。
失败的尝试:
1.使用SciPy
首先,我编写了一个成本函数来判断给定参数集的“质量”(重叠像素应该匹配),并应用SciPy的求解器来计算它。我对我的代价函数做了几次调整(应用高斯模糊、缩小图像、灰度缩放图像、使用Sobel算子获取梯度、只查看重叠后"seam“两侧的像素,而不是整个重叠区域等等),但始终找不到一个好的解决方案。大多数情况下,结果看起来比原来的相机图像更糟糕:

2.使用数学
失败时,我尝试将数学应用于,计算,进行正确的透视图转换。我知道相机的视场(从规格表),我知道图像的宽度和高度,我知道传感器的大小(从规格表),我用量角器测量镜头之间的角度。然后使用针孔模型计算图像平面上点的期望(x,y)值,以及纠正这些值所需的转换。结果看起来比SciPy好,但仍然令人沮丧。

3.使用OpenCV的Stitcher
之后,我尝试使用OpenCV的内置Stitcher类。然而,由于图像之间没有足够的重叠(大约10%的时间它甚至没有将切片1和2缝合在一起,大概是因为RANSAC的不确定性质),它无法将切片2和3缝合在一起。即使它成功了,它的缝纫也没那么好:

4.使用ORB和OpenCV的findHomography
最近,我尝试使用带有掩码的ORB (仅查找重叠区域中的特性)和OpenCV的findHomography函数来创建自定义版本的Stitcher。虽然匹配看起来很有希望,但由此产生的针法仍然不太理想:

我开始怀疑我的方法(切片->镜头,正确的->透视图,转换->覆盖)是有缺陷的,有更好的方法来做到这一点。
5.更新ORB / findHomography
我更新了我的特征检测,以消除任何匹配的Y坐标有很大差异(例如,匹配白色的表和白色的灯光)。在此基础上,我的匹配特征从110下降到55,但同源性有了明显的提高。下面是对切片1/2和2/3进行更新的结果:


在有人告诉我我做错了之前,我会继续执行这个策略,并增加以下步骤:
- 切片图像
- 镜头校正每一片
- 透视转换切片2或3,使边线是水平的,中场线是垂直的。
- 使用ORB +匹配滤波+ findHomography迭代排列,然后缝合相邻的切片
最终,当所有这些都说了,做了,我想尝试计算一个从输入像素到输出像素的映射,这样我们就不会在每帧中做所有的复杂工作(镜头校正,ORB,findHomography等)。我们将在每台摄像机上完成一次,将映射保存到某个文件中,然后我们可以使用cv2.remap实时地将输入视频映射到输出视频帧。
注意:
我贴出的第二张照片显示了“预期的输出”,它直接来自被质疑的摄像机。它可以配置为在30 fps时返回第一映像,或在10 fps返回第二映像。我们希望在一台功能更强大的计算机上执行非摄像机拼接,这样我们可以得到30 fps,但仍然有一个图像。
AXIS提供了一个用于非摄像机拼接的SDK,但是这个SDK是Windows专用的,我们的大部分技术栈都是Linux,我们的大多数开发机器都是Mac。我使用了Windows计算机来尝试查看他们提供的缝纫SDK,但是我没有运气让它编译和运行。他们的示例代码不断地抛出错误,我从来没有运气让Visual或C++为我弹得很好。
回答 1
Stack Overflow用户
发布于 2019-11-14 18:29:38
我的建议是训练一台自动编码器。使用第一幅图像作为输入,第二幅图像作为输出,如在去噪自动编码器中:
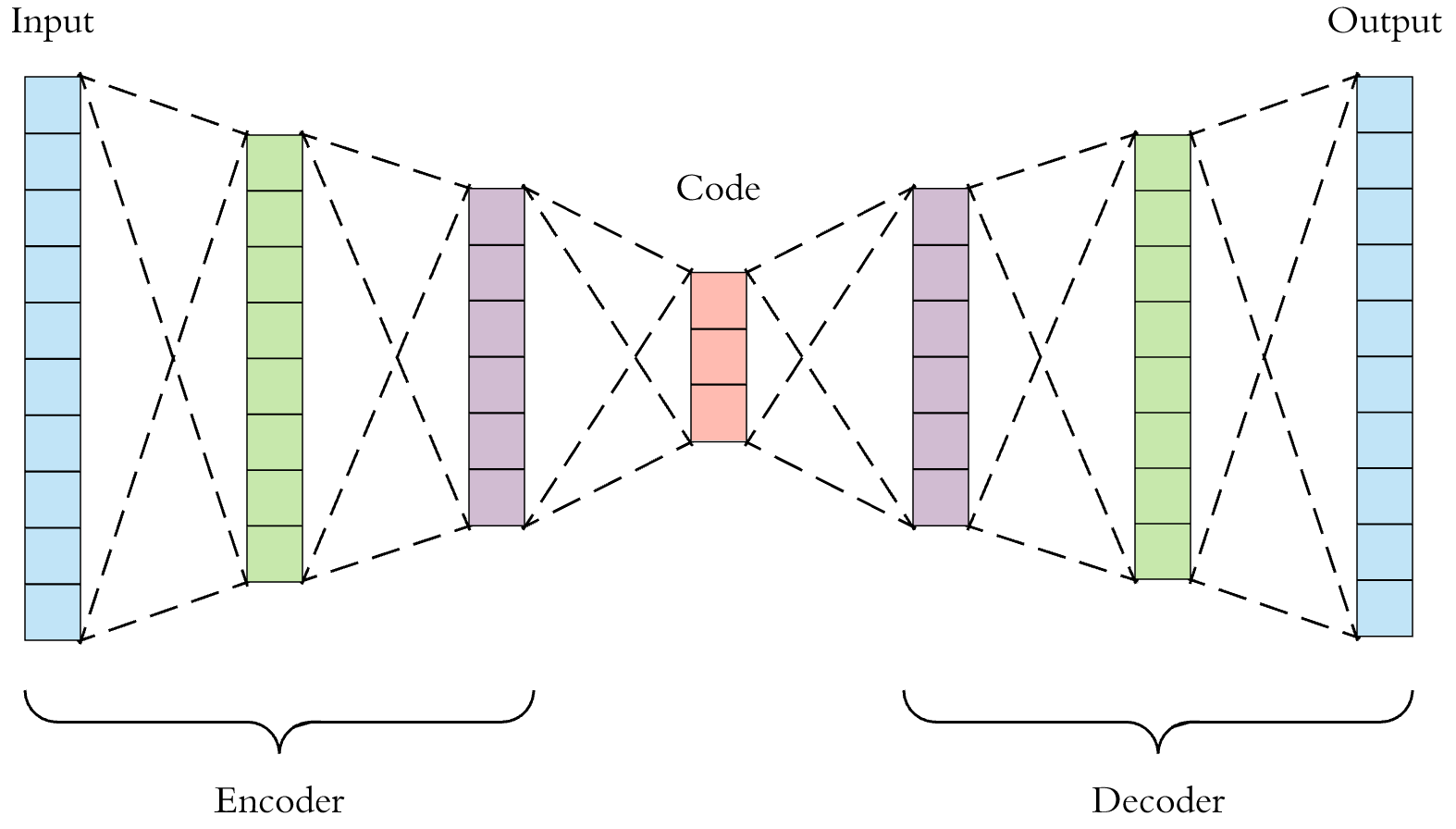
注意,如果在中间层创建一个太小的botteleneck,则可能会丢失分辨率。

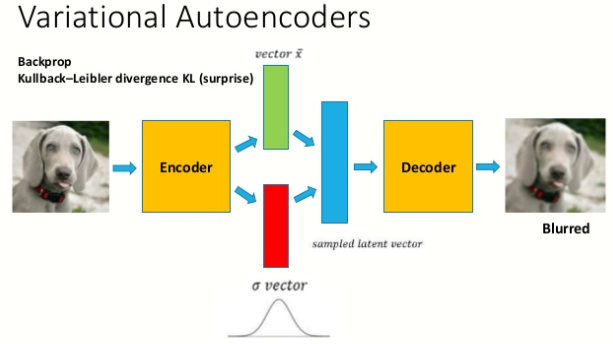
此外,变分自动编码器呈现一个潜在的向量,但工作遵循相同的原则。
您可以修改以下代码:
denoise = Sequential()
denoise.add(Convolution2D(20, 3,3,
border_mode='valid',
input_shape=input_shape))
denoise.add(BatchNormalization(mode=2))
denoise.add(Activation('relu'))
denoise.add(UpSampling2D(size=(2, 2)))
denoise.add(Convolution2D(20, 3, 3,
init='glorot_uniform'))
denoise.add(BatchNormalization(mode=2))
denoise.add(Activation('relu'))
denoise.add(Convolution2D(20, 3, 3,init='glorot_uniform'))
denoise.add(BatchNormalization(mode=2))
denoise.add(Activation('relu'))
denoise.add(MaxPooling2D(pool_size=(3,3)))
denoise.add(Convolution2D(4, 3, 3,init='glorot_uniform'))
denoise.add(BatchNormalization(mode=2))
denoise.add(Activation('relu'))
denoise.add(Reshape((28,28,1)))
sgd = SGD(lr=learning_rate,momentum=momentum, decay=decay_rate, nesterov=False)
denoise.compile(loss='mean_squared_error', optimizer=sgd,metrics = ['accuracy'])
denoise.summary()
denoise.fit(x_train_noisy, x_train,
nb_epoch=50,
batch_size=30,verbose=1)https://stackoverflow.com/questions/58861285
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号