
Java集群流WithKmeans:微集群和宏集群的零中心和(半径,权重= 0)
Java集群流WithKmeans:微集群和宏集群的零中心和(半径,权重= 0)
提问于 2019-11-17 18:22:29
,首先是:我在java项目中使用moa-release-2019.05.0-bin/moa-release-2019.05.0/lib/moa.jar。
现在,让我们谈谈重点:我正在尝试使用moa.clusterers.clustream.WithKmeans流聚类算法,我不知道为什么会发生这种情况…
我刚开始使用moa,我很难理解如何使用聚类算法。文档缺乏用于常见用法的示例代码,而且实现也没有得到很好的解释。也没有找到任何教程。
- 我的代码:
import com.yahoo.labs.samoa.instances.DenseInstance;
import moa.cluster.Clustering;
import moa.clusterers.clustream.WithKmeans;
public class TestingClustream {
static DenseInstance randomInstance(int size) {
DenseInstance instance = new DenseInstance(size);
for (int idx = 0; idx < size; idx++) {
instance.setValue(idx, Math.random());
}
return instance;
}
public static void main(String[] args) {
WithKmeans wkm = new WithKmeans();
wkm.kOption.setValue(5);
wkm.maxNumKernelsOption.setValue(300);
wkm.resetLearningImpl();
for (int i = 0; i < 10000; i++) {
wkm.trainOnInstanceImpl(randomInstance(2));
}
Clustering clusteringResult = wkm.getClusteringResult();
Clustering microClusteringResult = wkm.getMicroClusteringResult();
}
}- 调试器提供的信息:
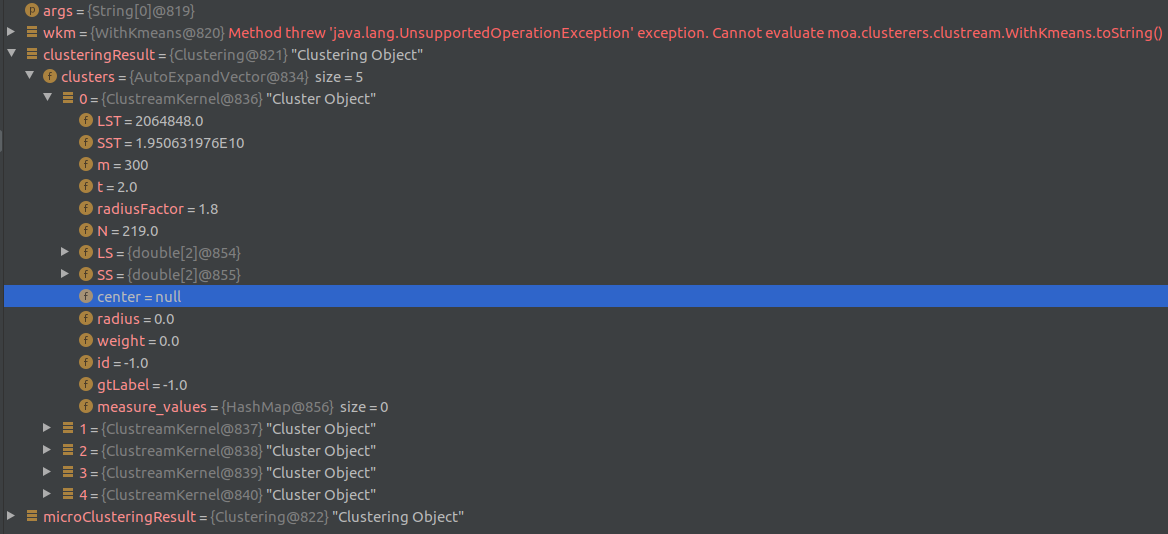
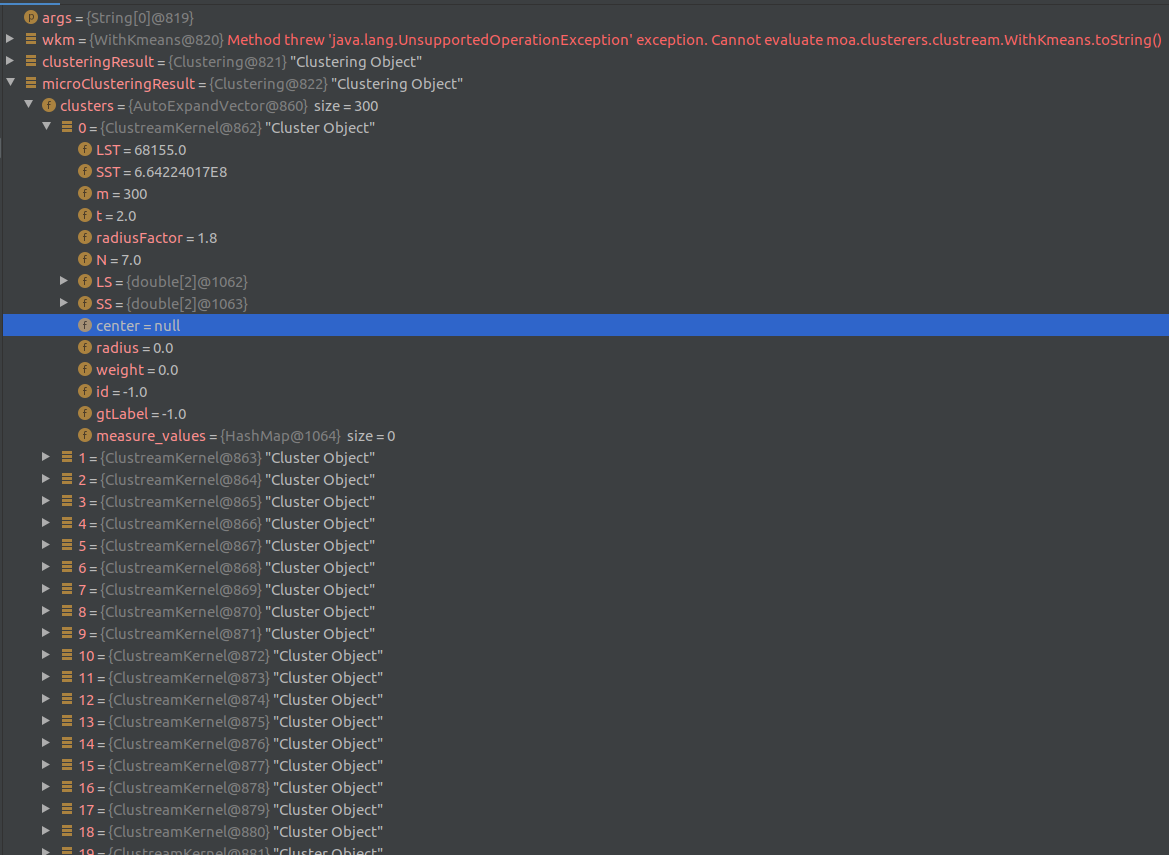
我已经读过源代码很多次了,在我看来,我使用的是正确的函数,按照正确的顺序.我不知道我错过了什么。欢迎任何反馈!
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-11-17 21:16:07
确保您已经给算法提供了足够的数据,它将分批处理数据。
字段未使用,可能来自具有不同用途的父类。
使用getter方法,例如getCenter(),它将从运行的和计算当前中心。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58903721
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号