
量子标记的时间序列分析
我遇到了一些问题,想出一种将时间信息与quanteda中的每个令牌配对的方法。我想对25个不同标记的列表进行时间序列分析。我知道我可以找到每个令牌的索引,但是我想知道是否有任何方法直接将日期信息附加到每个单个令牌。
回答 1
Stack Overflow用户
发布于 2019-11-19 15:55:06
就我理解您的问题而言,您希望将日期信息保存在时间序列分析的文本旁边。以下是一些提示:
创建语料库
首先我们创建一个语料库。由于您没有提供示例数据,所以我将只使用用stringi包创建的一些随机文本:
library(quanteda)
set.seed(1)
text <- stringi::stri_rand_lipsum(nparagraphs = 30)
length(text)
#> [1] 30我创建了一个随机日期向量来跟随它:
date <- sample(seq(as.Date("1999/01/01"), as.Date("1999/02/01"), by = "day"), 30)现在我们可以创建语料库对象了。如果您检查了语料库函数(?corpus)的帮助,您可以看到对于不同的输入对象有不同的方法。对于字符对象,我们可以提供额外的文档级变量作为data.frame。
corp <- corpus(x = text,
docnames = NULL,
docvars = data.frame(date = date))
corp
#> Corpus consisting of 30 documents and 1 docvar.创建和设置dfm
quanteda中的大多数分析都是在document-feature matrix对象的帮助下完成的。在这里,我们把我们的语料库转换成一个dfm,然后只保留我们想要分析的特征。在这个例子中,我选择了随机文本中最常见的单词:
dfm <- dfm(corp)
dfm_sub <- dfm_keep(dfm,
pattern = c("sed", "in"),
valuetype = "fixed",
case_insensitive = TRUE)现在,dfm有许多优点,但是与其他工具一起使用它通常意味着我们需要首先将它转换为其他对象。这似乎松散了日期信息,但我们可以简单地在矩阵转换为data.frame之后重新附加它。
df <- convert(dfm_sub, "data.frame")
df$date <- dfm@docvars$date
head(df)
#> document in sed date
#> 1 text1 4 4 1999-01-31
#> 2 text2 6 8 1999-01-04
#> 3 text3 1 3 1999-01-30
#> 4 text4 1 6 1999-02-01
#> 5 text5 3 5 1999-01-17
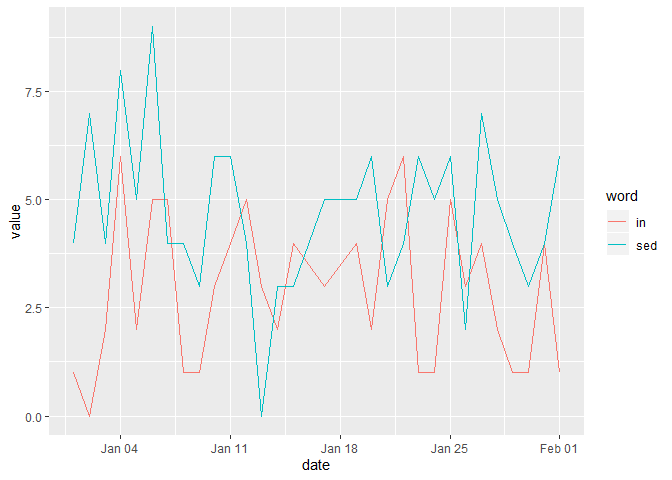
#> 6 text6 2 5 1999-01-28时间序列
你不太清楚你想做什么样的分析。在谈到时间序列时,我通常把第一步描绘成一个线条图。所以这就是我要做的
library(tidyr)
library(dplyr)
library(ggplot2)
df %>%
pivot_longer("in":sed, names_to = "word") %>%
ggplot(aes(x = date, y = value, color = word)) +
geom_line()
https://stackoverflow.com/questions/58918872
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号