
利用DirectQuery过滤重发值Power
利用DirectQuery过滤重发值Power
提问于 2019-11-25 13:41:21
我有一张表,里面有机器的时间戳和错误代码。
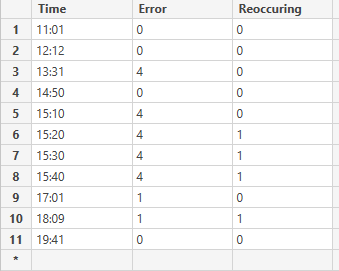
机器有时会连续重复几次相同的错误,但我只想将这些错误计算为一个错误。因此,我正在寻找一种方法来计算这些错误是否再次发生,并使用某种过滤器过滤掉这些错误。
我使用的是DirectQuery,所以使用前面的()获取最后一个错误似乎不起作用。
我应该如何过滤这些重复出现的错误?
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-11-26 10:08:03
正如Andrey所设想的那样,我需要使用分区BY子句,使用机器的序列号。
SELECT TOP 100 PERCENT *,
(CASE WHEN error = 0 OR error = LAG(error, 1, 0) OVER (PARTITION BY serial_nr ORDER BY event_time DESC)
THEN 0
ELSE 1
END) AS error_is_new
FROM MyTable我在表中添加了一个新列,其中包含错误是否是新的。
我使用error_is_new只显示新的错误。
Stack Overflow用户
发布于 2019-11-25 15:08:01
如果要在数据库中执行此操作,Azure支持滞后函数,因此将数据加载到Power的查询可能如下所示:
declare @t table([Time] time, [Error] int)
insert into @t([Time], [Error]) values
('11:01', 0),
('12:12', 0),
('13:31', 4),
('14:50', 0),
('15:10', 4),
('15:20', 4),
('15:30', 4),
('15:40', 4),
('17:01', 1),
('18:09', 1),
('19:41', 0)
select
t.[Time]
, t.[Error]
, IIF(t.[Error] <> 0 and LAG(t.[Error], 1) OVER(ORDER BY t.[Time]) = t.[Error], 1, 0) as Reoccuring
from @t t
order by t.[Time]
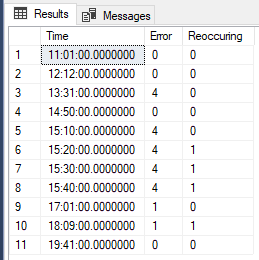
请注意,该示例没有显示对数据进行分区,例如按机器或其他方式进行分区,因为您的示例数据不包括这些数据。如果需要这样做,就必须将分划分句添加到延迟函数中。如果你用精确的数据库模式更新你的问题,我也会更新我的答案。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59033194
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号