
我可以用标记化输入文件和高棉语的自定义词汇表文件从头开始对BERT模型进行预培训吗?
我想知道是否可以使用我自己的标记/分段文档(还有我自己的词汇表文件)作为create_pretraining_data.py脚本的输入文件(git源:https://github.com/google-research/bert)。
造成这一问题的主要原因是高棉语的切分/标记化与英语不同。
Original:
វាមានមកជាមួយនូវ
Segmented/Tokenized:
វា មាន មក ជាមួយ នូវ我自己尝试了一些东西,并在运行create_pretraining_data.py和run_pretraining.py脚本之后获得了一些结果。然而,我不确定我所做的是否可以被认为是正确的。
我也想知道我应该用什么方法来验证我的模型。
任何帮助都是非常感谢的!
脚本修改
我所做的修改是:
- 以列表格式制作输入文件
我的输入文件不是普通的纯文本,而是来自我的自定义高棉标记化输出,然后我将它变成一个列表格式,模仿我在运行示例英语文本时得到的输出。
[[['ដំណាំ', 'សាវម៉ាវ', 'ជា', 'ប្រភេទ', 'ឈើ', 'ហូប', 'ផ្លែ'],
['វា', 'ផ្តល់', 'ផប្រយោជន៍', 'យ៉ាង', 'ច្រើន', 'ដល់', 'សុខភាព']],
[['cmt', '$', '270', 'នាំ', 'លាភ', 'នាំ', 'សំណាង', 'ហេង', 'ហេង']]]*外括号表示源文件,第一个嵌套括号表示文档,第二个嵌套括号表示句子。与all_documents函数中的变量create_training_instances()完全相同的结构
- 从唯一分段词中提取的语音文件
这是我真的很怀疑的部分。为了创建我的vocab文件,我所做的就是从整个文档中找到唯一的令牌。然后添加核心令牌需求[CLS], [SEP], [UNK] and [MASK]。我不确定这样做是否正确。
对此部分的反馈非常感谢!
- 在create_training_instances()函数中跳过标记化步骤
由于我的输入文件已经与变量all_documents匹配,所以我跳过了第183行到第207行。我把它替换为阅读我的输入内容如下:
for input_file in input_files:
with tf.gfile.GFile(input_file, "r") as reader:
lines = reader.read()
all_documents = ast.literal_eval(lines)成果/产出
原始输入文件(在自定义标记化之前)来自随机web抓取。
关于原始和调用文件的一些信息:
Number of documents/articles: 5
Number of sentences: 78
Number of vocabs: 649 (including [CLS], [SEP] etc.)下面是运行create_pretraining_data.py后的输出(其尾部)
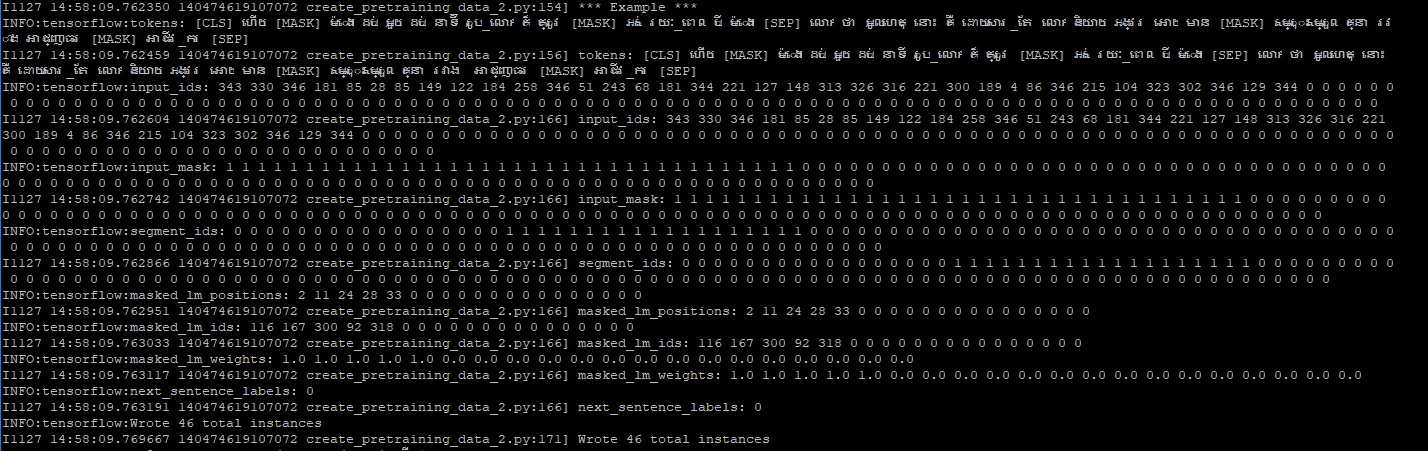
这就是我在运行run_pretraining.py之后得到的
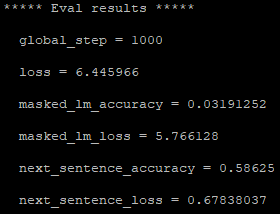
正如上面的图表所示,我从这得到一个非常低的精度,因此我担心如果我做得正确。
回答 1
Stack Overflow用户
发布于 2019-11-27 14:12:59
首先,你似乎没有什么训练数据(你提到的词汇量是649)。伯特是一个庞大的模型,需要大量的培训数据。谷歌出版的英语模型至少对整个维基百科进行了培训。想想看!
伯特使用了一种叫做WordPiece的东西,它保证了固定的词汇量。罕见的单词是这样分割的:Jet makers feud over seat width with big orders at stake翻译成wordPiece为:_J et _makers _fe ud _over _seat _width _with _big _orders _at _stake。
WordPieceTokenizer.tokenize(text)采用由空格进行标记化的文本预处理,因此您应该更改BasicTokenizer,它由特定的标记器在WordPieceTokenizer之前运行,该标记程序应该用空格分隔令牌。为了训练您自己的恶sentenePiece,请看一看sentenePiece,它在bpe模式下基本上与WordPiece相同。然后可以从WordPiece模型导出词汇表。
我本人并没有对BERT模型进行预培训,所以我无法帮助您准确地更改代码中的某些内容。
https://stackoverflow.com/questions/59066593
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号