
SQL数据库中去规范化的一个实用示例?
在过去的20分钟里,我一直在阅读关于反规范化的文章,但是没有一个简洁的代码示例。
这就是非正规化吗?
- 我们有一个规范化的数据库:
Table_1:
customer_id (主键)
国家/地区
城市
街道
house_number
Table_2:
product_id (主键)
customer_id (外键)
product_storage_building
Table_3:
product_id (外键)
product_name
product_color
product_origin
- 然而,连接这三个表要花费的时间太长了,比如说 从TABLE_1中选择a.*,b.*,c.*作为左联接,TABLE_2作为a.customer_id上的b= b.customer_id,左加入TABLE_3,c上b.product_id = c.product_id
所以我用Table_1和Table_2创建了一个新的表
CREATE OR REPLACE TABLE Denormalized_Data AS
(
SELECT customer_id,
country,
city,
street,
house_number,
product_id,
product_storage_building
FROM Table_1
LEFT JOIN Table_2
ON Table_1.cusomter_id = Table_2.customer_id
)- 然后加入到Table_3,如下所示 选择customer_id、country、city、street、house_number、product_storage_building、Denormalized_Data.product_id product_name、product_color,从Denormalized_Data左加入Table_3 ON Denormalized_Data.product_id = Table_3.product_id
现在,这将使我的查询运行得更快--可以将上面的整个过程描述为去规范化吗?
谢谢
回答 4
Stack Overflow用户
发布于 2019-11-26 21:32:46
是的,你展示的是一种非正规化。
有三种类型的非正规化:
- 连接不同表中的行,这样您就不必在
JOIN中使用查询了。 - 执行聚合计算,如
SUM()、COUNT()或MAX()或其他,这样您就不必在GROUP BY中使用查询。 - 预先计算昂贵的计算,因此您不必在选择列表中使用带有复杂表达式的查询。
你展示了第一种类型的例子。至少你可以避免你打算做的两个连接中的一个。
为什么不将非规范化表存储作为连接所有三个表的结果?
使用去正规化有什么坏处?现在您正在冗余地存储数据:一次是在规范化表中,另一次是在非规范化表中。假设您明天开始工作,发现这些不同表中的数据不完全匹配。发生了什么?
- 可能有人在未将相应数据添加到非规范化表的情况下将一行插入到规范化表中。
- 也许有人从法线化的表中删除了一行,而没有从非规范化表中删除相应的行。
- 可能有人在非规范化表中插入或删除了一行,而没有对规范化表进行相应的更改。
你怎么知道发生了什么?哪张桌子是“对的”?这就是去正规化的风险。
Stack Overflow用户
发布于 2019-11-26 21:57:21
请考虑下面的图像。顶部包含几个不同的表,这些表封装了逻辑上分开的信息位。底部显示了这些表连接在一起的结果。这是去正规化。
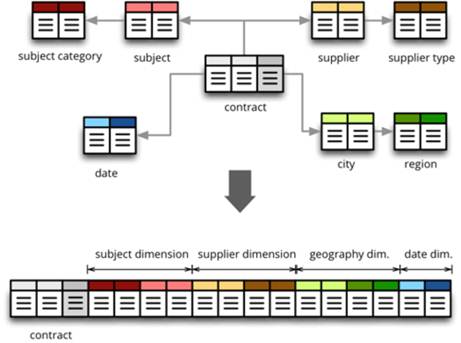
在BigQuery的情况下,尤其是使用BQ作为BI平台的后端,非规范化数据提供了更快的用户体验,因为当用户点击“run”时,它不需要进行连接。
如果将表保留为原样,如果用户需要几个字段,则最终可能会执行多达7个联接,然后进行聚合(和、计数等)。但是,如果您完成了所有7个联接并将其存储在一个表中,那么用户将只查询一个表而只执行聚合。这是BigQuery的力量。它是可扩展的,因此与联接相比,对海量数据进行分组和聚合相对“容易”,从而使最终用户体验更快。
向这个方向发展的人/公司通常在ETL过程中这样做(通常是在一夜之间),因此连接只需发生一次(当用户通常不使用数据库时),然后在白天,用户和BI工具只是在没有联接的情况下聚合和切片数据!这确实会导致“冗余”数据,并导致额外的存储成本,但对于下游用户体验来说,这通常是值得的。
Stack Overflow用户
发布于 2019-11-26 22:23:35
下面是BigQuery的具体答案!
当您的数据被非规范化时,BigQuery表现最好。与保留关系模式(如星型或雪花模式)不同,您可以通过去角色化数据和利用嵌套和重复字段来提高性能。嵌套和重复字段可以维护关系,而不会影响保持关系(规范化)模式的性能。
在现代系统中,标准化数据所节省的存储费用就不那么重要了。存储成本的增加值得从去磁数据中获得性能收益。联接需要数据协调(通信带宽)。去正规化将数据本地化到单独的插槽中,这样就可以并行执行。
如果您需要在数据反错的同时维护关系,请使用嵌套的和重复的字段,而不是完全扁平数据。当关系数据完全扁平时,网络通信(改组)会对查询性能产生负面影响。
例如,在不使用嵌套字段和重复字段的情况下对orders模式进行去可能要求您按像order_id这样的字段进行分组(当存在一对多的关系时)。由于所涉及的改组,分组数据的性能不如使用嵌套和重复字段对数据进行反规范化。
注意:在某些情况下,去角色化数据和使用嵌套字段和重复字段可能不会提高性能。
您可以在尽可能对数据进行去Denormalize处理文档的BigQuery部分看到更多信息。
最后: BigQuery不需要完全平坦的去正规化。可以使用嵌套字段和重复字段来维护关系。
下面是从问题中的三个初始规范化表中生成非规范化表的示例
#standardSQL
SELECT ANY_VALUE(c).*,
ARRAY_AGG((SELECT AS STRUCT p.*, s.product_storage_building)) products
FROM `project.dataset.customers` c
LEFT JOIN `project.dataset.storage` s USING (customer_id)
LEFT JOIN `project.dataset.products` p USING (product_id)
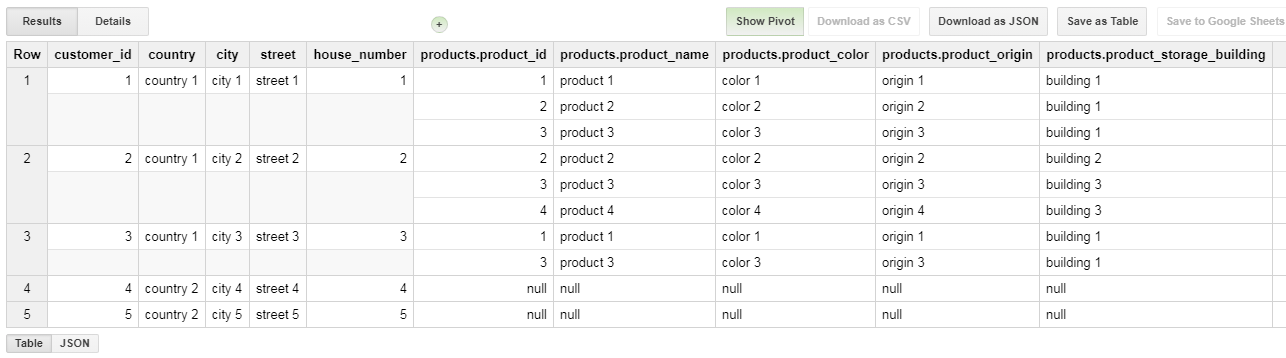
GROUP BY FORMAT('%t', c)这将生成具有以下模式的表
显然,这是一个更注重客户的模式。取决于您的需求,您也可以创建以产品为中心的产品。或者实际上两者都使用,并根据用例使用适当的

您可以使用虚拟数据进行测试,如下面的示例所示
#standardSQL
WITH `project.dataset.customers` AS (
SELECT 1 customer_id, 'country 1' country, 'city 1' city, 'street 1' street, 1 house_number UNION ALL
SELECT 2, 'country 1', 'city 2', 'street 2', 2 UNION ALL
SELECT 3, 'country 1', 'city 3', 'street 3', 3 UNION ALL
SELECT 4, 'country 2', 'city 4', 'street 4', 4 UNION ALL
SELECT 5, 'country 2', 'city 5', 'street 5', 5
), `project.dataset.products` AS (
SELECT 1 product_id, 'product 1' product_name, 'color 1' product_color, 'origin 1' product_origin UNION ALL
SELECT 2, 'product 2', 'color 2', 'origin 2' UNION ALL
SELECT 3, 'product 3', 'color 3', 'origin 3' UNION ALL
SELECT 4, 'product 4', 'color 4', 'origin 4'
), `project.dataset.storage` AS (
SELECT 1 product_id, 1 customer_id, 'building 1' product_storage_building UNION ALL
SELECT 2, 1, 'building 1' UNION ALL
SELECT 3, 1, 'building 1' UNION ALL
SELECT 2, 2, 'building 2' UNION ALL
SELECT 3, 2, 'building 3' UNION ALL
SELECT 4, 2, 'building 3' UNION ALL
SELECT 1, 3, 'building 1' UNION ALL
SELECT 3, 3, 'building 1'
)
SELECT ANY_VALUE(c).*,
ARRAY_AGG((SELECT AS STRUCT p.*, s.product_storage_building)) products
FROM `project.dataset.customers` c
LEFT JOIN `project.dataset.storage` s USING (customer_id)
LEFT JOIN `project.dataset.products` p USING (product_id)
GROUP BY FORMAT('%t', c) 带输出
https://stackoverflow.com/questions/59059327
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号