
何谓聚类的最佳k?(肘点图)
我正在设法找到在首尔地铁站附近开咖啡店的最佳地点。
包括的特点如下:
- 某一车站的每月总发车量
- 靠近某一车站的租金
- 某一车站附近现有咖啡店的数目
我决定用肘尖来找出最好的k,在跑kmeans之前,我把所有的功能都标准化了。
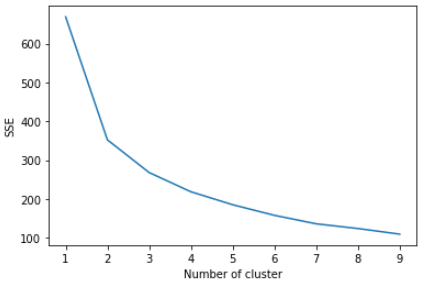
现在弯头点似乎是k=3(或者可能是k=2),但是我认为对于弯头点来说,SSE太高了。
此外,使用k=3时,很难从集群中获得洞察力,因为只有三个集群。
使用k=5是获得洞察力的最佳地点。
即使不是肘部点,使用k=5也是合理的吗?
或者一开始就不是一个好的选择?
回答 3
Stack Overflow用户
发布于 2019-11-29 14:46:09
肘点不是一个确定的规则,但更像是一种启发式方法,(它大部分时间起作用,但并不总是起作用,所以我认为它更像是一个很好的经验法则,可以从多个集群开始选择)。最重要的是,肘点不能总是被明确地识别出来,所以你不应该太担心它。
因此,在这种情况下,如果您在如何使用k=5理解数据方面获得了更好的结果/增益,那么我强烈建议您使用k=5而不是k=3!
现在,对于您的另一个问题,可能有更适合您的数据的方法,但这并不意味着k-方法不是一个好的方式开始。如果您想尝试其他的东西,scikit-learn库文档可以很好地洞察在进行集群时使用哪种算法或方法。
Stack Overflow用户
发布于 2019-11-29 19:31:14
我不认为k-意在这些特性上解决了你的问题。你可能需要重新考虑你的方法。特别是,请注意您优化的功能( SSE对您的任务意味着什么?)-在错误的特性上使用错误的函数可能意味着您得到了另一个问题的答案。
他的肘法是可怕的不可靠,我希望人们最终会停下来,甚至提到它。如果你使用itz,你应该问的第一个问题是:在没有k的随机数据上,曲线看起来像一个典型的曲线吗?如果是这样的话,完全停止,重新做您的方法,因为它看起来您的数据是坏的-或至少,k-意味着不工作。您正是处于这样的情况:(图中的图)表明k-方法不适用于您的数据.
Stack Overflow用户
发布于 2019-11-29 15:08:29
选择簇数的一种方法是“弯头法”。正如机器学习专家Andrew所解释的那样,通过计算每个k个集群的失真值,您可以根据集群的数量绘制这个值。在失真值开始以较低的速率下降的情况下,可以识别适当的k值,在下面的图中,在k=3 (Ng,无日期a)中对此进行了描述。当失真值以稳定的速度下降时,问题就出现了,产生了一条平滑的曲线,在图中的右边就是个例子。没有明确的‘关节’来识别‘肘部’。
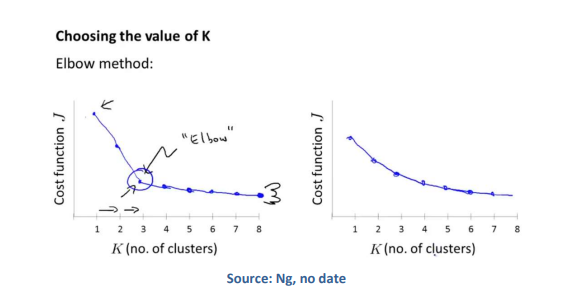
在我写论文的时候,我的数据落在了后者(见下文-我应该为K选择什么?
这意味着我需要另一种方法。另一种方法是通过剪影分析。正如在Scikit-学习文档中所解释的,为了了解团簇的分离,对剪影分析进行了探索。
聚类的轮廓系数从-1得分到+1。接近+1的分数表示样本与相邻簇之间的距离,因此表示样本与集群不同。分数为零意味着样本位于聚类的边界或接近簇的决策边界。剪影得分为-1表示样本被分配到错误的聚类中(在KMeans聚类上使用剪影分析选择聚类的数量- scikitlearn 0.19.1文档,2017)。当可视化观测在簇中的分布和剪影系数值相对于其他簇,如‘肘法’,人们可以直观地识别一个适当的k值。其目的是选择一个k值,其中每个聚类中的样本数相对相同,而大多数样本保持在平均轮廓分数之上。
我建议试一试(即使有一个清晰的“肘”)来验证您是否选择了一个合适的k值,以及( b)练习和查看/理解其他方法是很好的。
https://stackoverflow.com/questions/59106417
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号