
如何提高tesseract.js的精度?
如何提高tesseract.js的精度?
提问于 2019-12-01 13:51:09
我使用了这段来自网站的代码,但不够精确
const worker1 = createWorker();
const worker2 = createWorker();
await worker1.load();
await worker2.load();
await worker1.loadLanguage("eng");
await worker2.loadLanguage("eng");
await worker1.initialize("eng");
await worker2.initialize("eng");
scheduler.addWorker(worker1);
scheduler.addWorker(worker2);
/** Add 10 recognition jobs */
const {
data: { text }
} = await scheduler.addJob("recognize", image);这就是我试图读到的图片的类型:

你看上去既简单又容易,有时却看不懂。是否有任何更好的替代tesseract.js或任何提高准确性的方法?
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-12-03 02:15:52
在使用Tesseract进行OCR时,必须对图像进行预处理,以便要检测的文本为黑色,背景为白色。为此,您可以应用一个简单的阈值来获得二进制图像。以下是预处理后的图像:
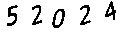
结果来自Tesseract
52024我在Python中实现了这种方法,但是您可以将类似的策略应用于OpenCV!
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
# Load image and Otsu's Threshold to get a binary image
image = cv2.imread('1.png', 0)
thresh = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
# Perform OCR
data = pytesseract.image_to_string(thresh, lang='eng', config='--psm 6')
print(data)
cv2.imshow('thresh', thresh)
cv2.waitKey()页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59126144
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号