
在目标检测中,过度拟合如何导致误报?
我正在做tensorflow object detection,我发现有很多false positives。我看到的主要原因之一是overfitting。但我怀疑false positive是如何成为overfitting的结果的?当它在数据中学习一个复杂的模式,或者简单地说,它导致对数据的记忆时,过度拟合就会发生。
如果是记忆,它会不会显示更多的假阴性,因为它只有memorised the training data,无法发现新的病例。它如何才能真正将其他对象归类为属于经过训练的类is it not counter intuitive?的对象?
回答 1
Stack Overflow用户
发布于 2019-12-02 14:06:10
我可以想到的一个原因是培训数据中的离群值:
假设你在A类的训练数据中有一些强异常值,结果可能会更多地分布在另一类B的某个维度上,然后过度拟合会导致类边界向这个离群点的方向移动。这实际上会导致大量的假阳性,因为A类移动的边界现在部分地位于一个应该属于B类的区域内。
在一个极端的例子中,过高的边界可能如下所示:
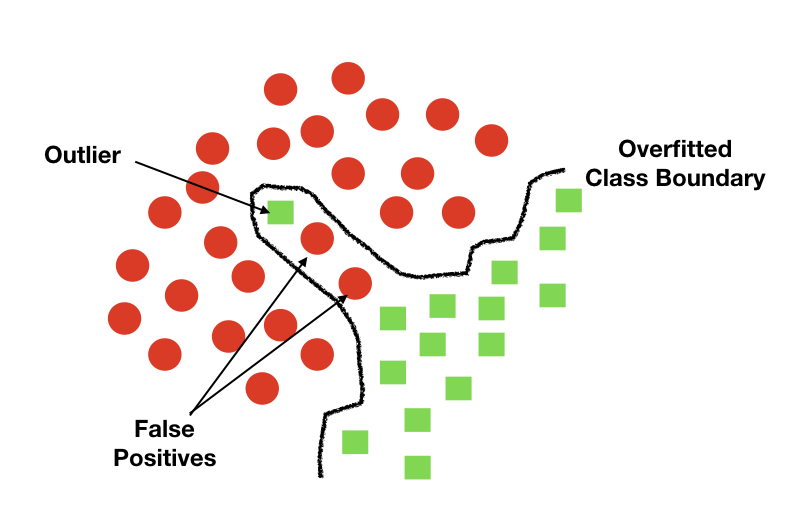
在这里,由于过度拟合,我们将异常值保留在正类中,而代价是取两个假负数。在这两个类别之间的一个广义的好边界将放弃异常值作为假负,但由于不包括这两个假阳性,仍然有一个更高的准确性。
顺便说一句,由于异常值而导致的假阳性也可能发生,这就是为什么过度拟合通常被认为是不好的原因。
https://stackoverflow.com/questions/59133201
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号