
MOA CluStream:在计算k均值之后,我们应该如何“命名”不位于任何宏簇内的微集群?
我目前正在学习CluStream,我对结果有些怀疑。我会继续解释:
如果用K均值聚类,我们都知道每个微簇都属于最近的宏簇(计算中心之间的欧几里德距离)。
现在,查看以下示例结果:
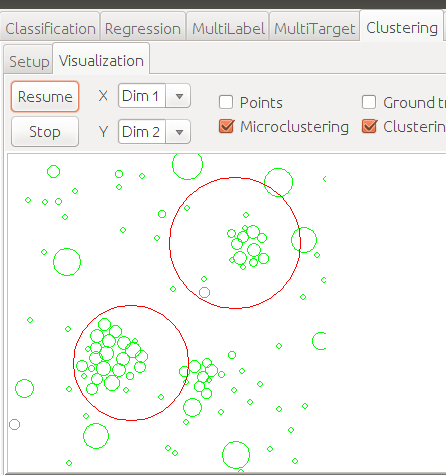
我们可以看到,宏观集群并没有对所有的微集群…进行分组。
,这是什么意思?我们应该如何考虑不存在于某些宏观集群中的微观集群?我应该找到每一个最接近宏的微集群来标记它们吗?
编辑:
检查MOA源代码 论吉乌布,发现宏团簇半径是计算的偏差乘以所谓的“半径因子”(其值固定在1.8)。然而,当我询问宏簇的权重时,如果使用了一个很大的时间窗口,并且没有衰落分量,我可以看到宏集群恢复了所有点的信息.考虑了当前所有的微集群!所以,即使我们看到一些远离宏观星系团球体的微团簇,我们也知道它们属于最接近的星团--毕竟是K均值!
所以,我还有一个问题:为什么要用这种方法计算宏观星团半径呢?我的意思是,它代表什么?算法不应该返回标记的微集群吗?
欢迎任何反馈意见。蒂娅!
回答 1
Stack Overflow用户
发布于 2019-12-13 06:54:00
关键问题是:用户需要什么?
标记微型集群是可以的,但是用户在哪里使用呢?
在大多数情况下,人们使用的k-均值结果都是聚类中心.因为k-均值的整个目标本质上是“寻找数据的最佳k点近似”。
因此,CluStream的所有信息用户都可能使用k当前的集群中心。也许每个人的体重,以及他们的年龄。
https://stackoverflow.com/questions/59290841
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号