
预测未来几周的产品需求
我想要建立一个模型,在每一步的几周内预测每种产品的未来需求(预测明年每种产品的每周需求)
我有几个小尺寸(大约100到200张唱片) csv。
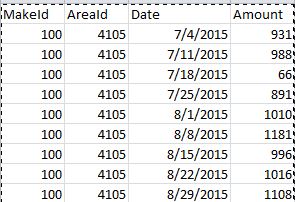
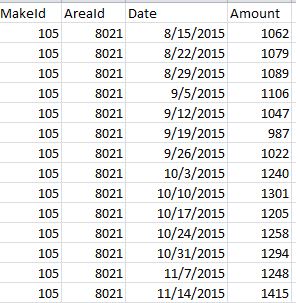
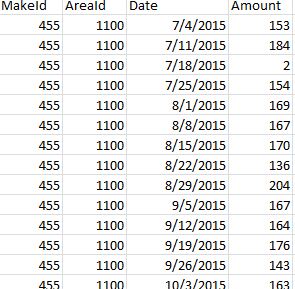
在这里,有关CSV列的信息:-第一列makeId表示产品的id。第二列areaId表示产品销售位置的内部id。第三列日期以mm/dd/yyyy格式表示 date 。第四列a表示给定区域在给定周内对给定产品的需求。
样本文件1-
样本文件2-
样本文件3-
我考虑使用Arima模型,但对于如何将数据转换为每周格式并使用它来预测每个make id,我感到有点困惑。
任何建议都是有帮助的,因为我是时间序列问题的新手。
回答 1
Stack Overflow用户
发布于 2019-12-16 19:22:24
注意:从您的示例中可以快速看出,您似乎已经有了每周的数据。如果这不是真的,或者您只是想将数据设置为能够使用ARIMA模型,下面的答案将有所帮助。
对您问题的快速回答是:使用pandas包将数据读入/操作到dataframe对象中,然后使用每周频率的.resample()方法,例如:.resample('W')。
更多详细信息:
对于时间序列分析,大多数应用程序将从将数据索引设置为时间变量中获益。在您的示例中,您可以在使用pandas读取数据时做到这一点:
import pandas as pd df = pd.read_csv('/path/to/your_data.csv', parse_dates=['date'], index_col='date')
如果您无法读取它,并且需要在适当的位置更改dataframe,您可以这样做:
df = df.set_index('date')
这假定date列被正确地设置为datetime对象。
下一步是重采样数据,以便您有一个新的值来捕获数据中的每周活动。这需要选择一个方法来组合Amount字段中的数据,因为您希望显示一个可以组合多天值的值。在这里,我将选择mean(),以便新的值是那个星期内那些天的数据的平均值。
df['Amount_weekly'] = df['Amount'].resample('W', how='mean')
由于您正在聚合数据,该函数将返回一个新系列,因此这里我将这个新系列放入df中的一个新列,即df['Amount_weekly']。
因此,您将有一个时间序列索引数据,列显示每周重放数据。这将是像statsmodels.这样的软件包中在ARIMA模型中使用的适当格式。
https://stackoverflow.com/questions/59353983
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号