
反向传播异或门
反向传播异或门
提问于 2019-12-18 20:53:52
我试图了解反向传播是如何工作的。因此,在编写通用算法之前,我编写了一个直接的脚本来尝试理解它。
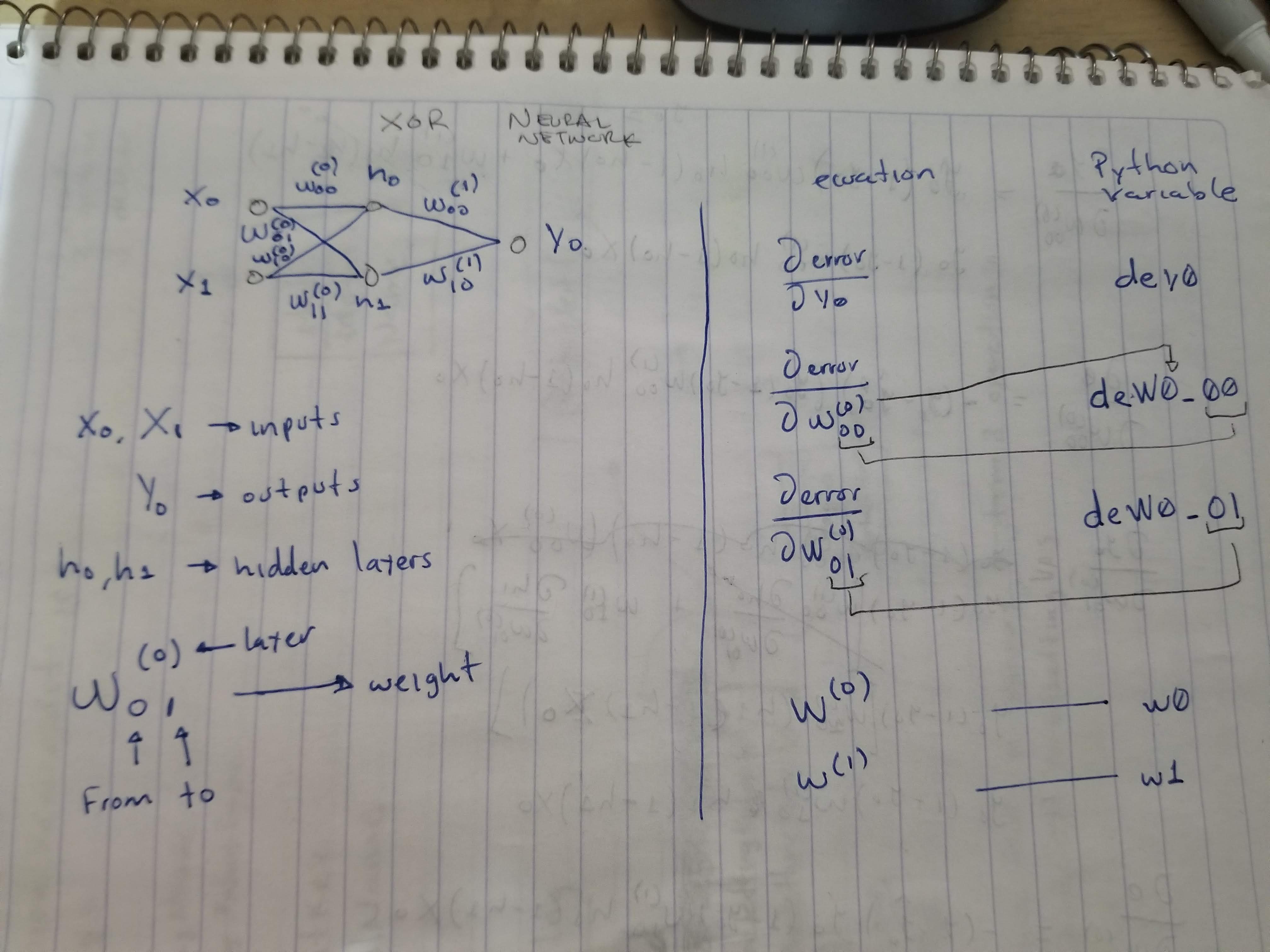
脚本试图做的是训练一个异或门。我的神经网络很简单。输入2个,隐神经元2个,输出1个。(注意,为了简单起见,省略了偏倚)
(有关更多信息,请参见后面所附的图像)
问题是,在训练了感知器之后,它不起作用了,我不知道问题在哪里。它可以在我的方程中,也可以在我的实现中。
代码:
def xor(self):
print('xor')
X = np.array([[1,1],[1,0],[0,1],[0,0]]) #X.shape = (4,2)
y = np.array([0,1,1,0])
w0 = np.array([[.9,.1],[.3,.5]]) #random weights layer0
w1 = np.array([.8,.7]) #random wights layer1
#forward pass
youtput=[]
for i in range(X.shape[0]):#X.shape = (4,2)
#print('x0', X[i][0])
#print('x1', X[i][1])
h0 = self.sig(w0[0,0]*X[i][0] + w0[1,0]*X[i][1])
h1 = self.sig(w0[0,1]*X[i][0] + w0[1,1]* X[i][1])
y0 = self.sig(w1[0]* h0 + w1[1] * h1) # shape = (4,)
youtput.append(y0)
print('y0',y0)
#backpropagation
dey0 = -(y[i]-y0) # y[i] -> desired output | y0 -> output
deW0_00 = dey0 * y0 * (1 - y0) * w1[0] * h0 * (1 - h0) * X[i][0]
deW0_01 = dey0 * y0 * (1 - y0) * w1[1] * h1 * (1 - h1) * X[i][0]
deW0_10 = dey0 * y0 * (1 - y0) * w1[0] * h0 * (1 - h0) * X[i][1]
deW0_11 = dey0 * y0 * (1 - y0) * w1[1] * h1 * (1 - h1) * X[i][1]
deW1_00 = dey0 * h0
deW1_10 = dey0 * h1
w0[0,0] = self.gradient(w0[0,0], deW0_00)
w0[0,1] = self.gradient(w0[0,1], deW0_01)
w0[1,0] = self.gradient(w0[1,0], deW0_10)
w0[1,1] = self.gradient(w0[1,1], deW0_11)
w1[0] = self.gradient(w1[0], deW1_00)
w1[1] = self.gradient(w1[1], deW1_10)
#print('print W0, ', w0)
#print('print W1, ', w1)
print('error -> ', self.error(y,youtput ))
#forward pass
youtput2= []
for i in range(X.shape[0]):#X.shape = (4,2)
print('x0 =', X[i][0], ', x1 =', X[i][1])
h0 = self.sig(w0[0,0]*X[i][0] + w0[1,0]*X[i][1])
h1 = self.sig(w0[0,1]*X[i][0] + w0[1,1]* X[i][1])
y0 = self.sig(w1[0]* h0 + w1[1] * h1)
youtput2.append(y0)
print('y0----->',y0)
print('error -> ', self.error(y,youtput2 ))
def gradient(self, w, w_derivative):
alpha = .001
for i in range(1000000):
w = w - alpha * w_derivative
return w
def error(self, y, yhat):
e = 0
for i in range (y.shape[0]):
e = e + .5 * (y[i]- yhat[i])**2
return e
def sig(self,x):
return 1 / (1 + math.exp(-x)) 结果
PS C:\gitProjects\perceptron> python .\perceptron.py
xor
y0 0.7439839341840395
y0 0.49999936933995615
y0 0.4999996364775347
y0 7.228146514841657e-229
error -> 0.5267565442535
x0 = 1 , x1 = 1
y0-----> 0.49999999999999856
x0 = 1 , x1 = 0
y0-----> 0.4999993695274945
x0 = 0 , x1 = 1
y0-----> 0.49999963653435153
x0 = 0 , x1 = 0
y0-----> 7.228146514841657e-229
error -> 0.3750004969693411方程式。

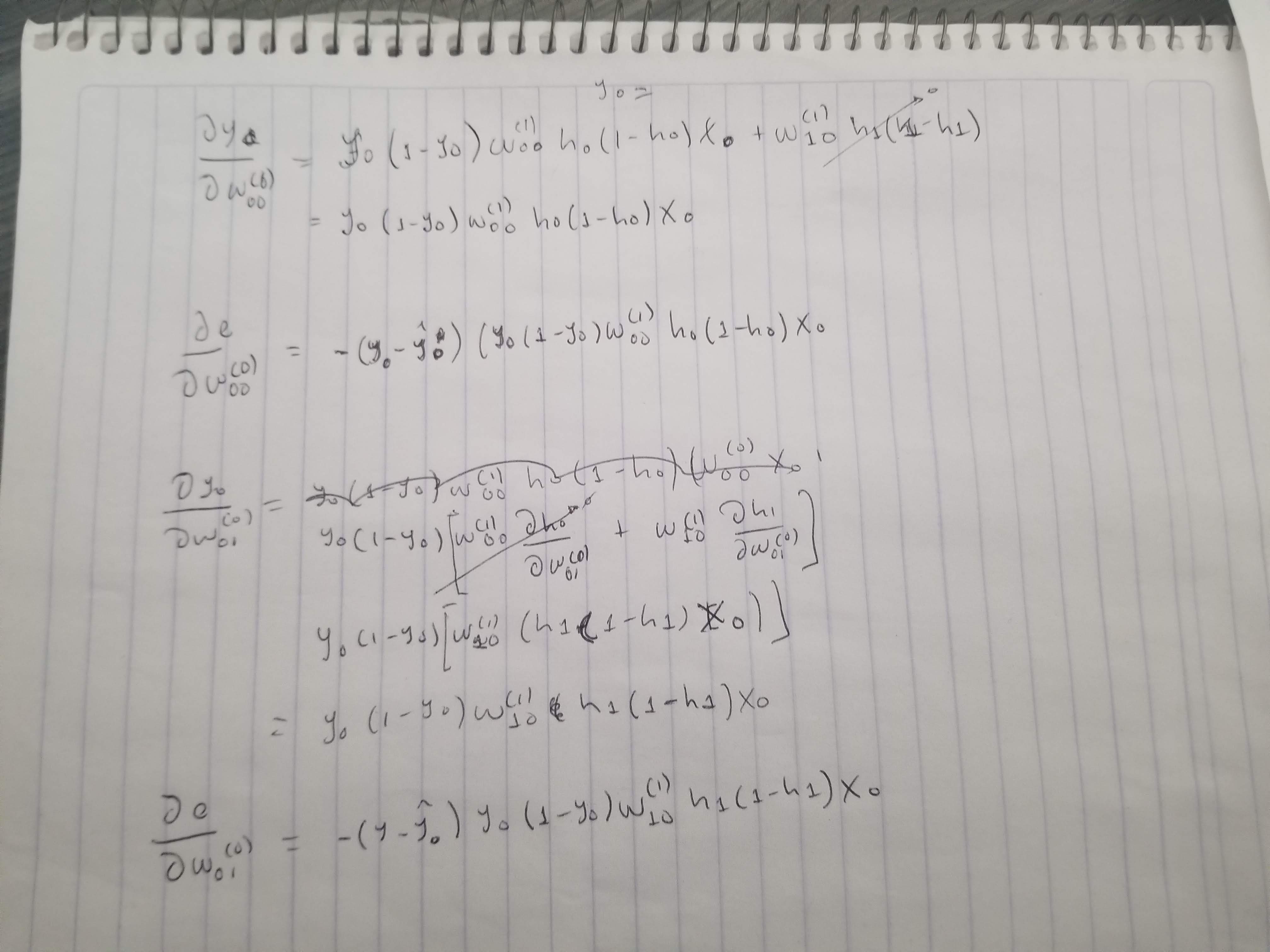
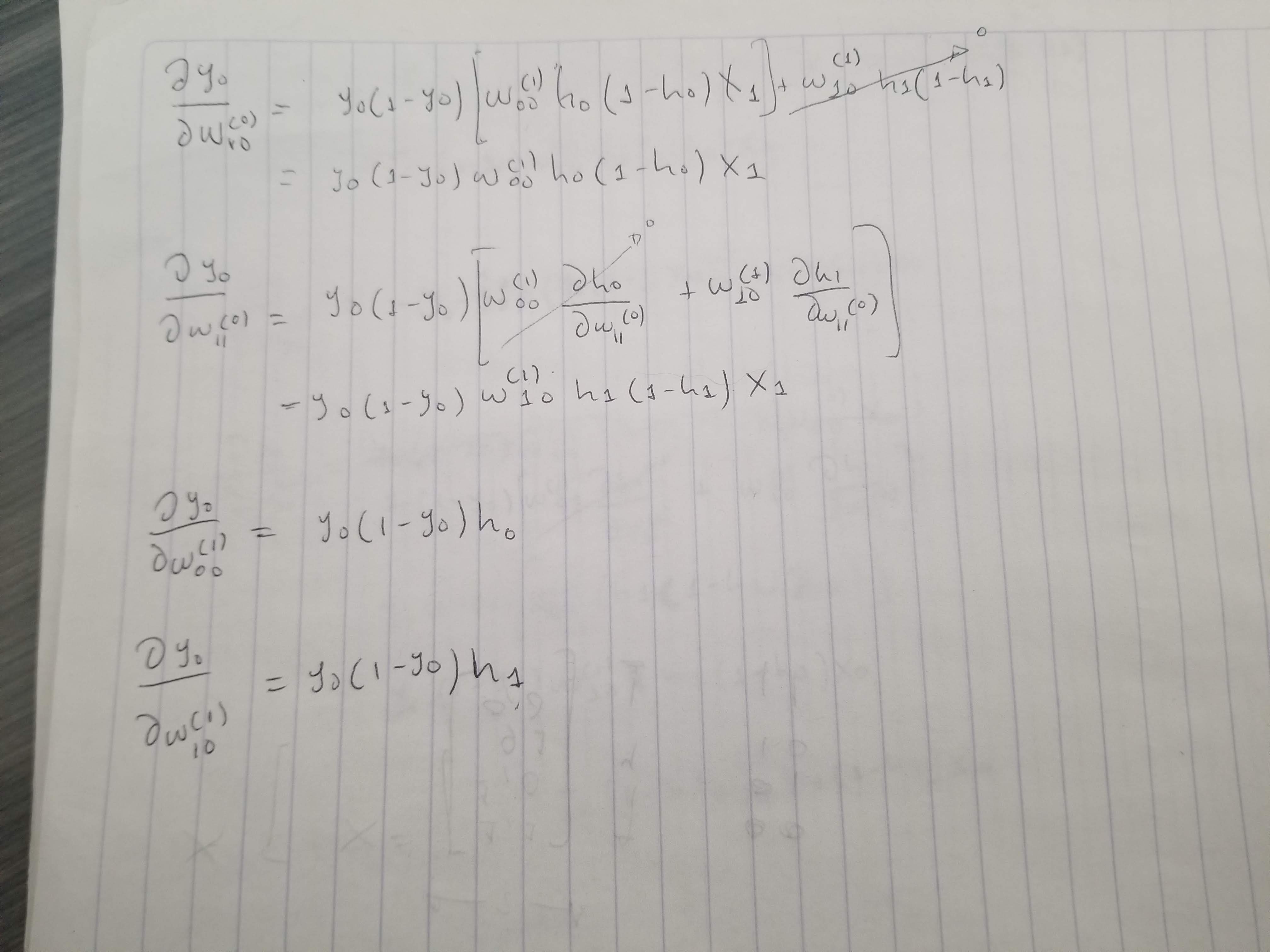
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-12-19 22:25:51
刚刚改变了你的“循环”方式,它现在似乎工作正常(下面修改的代码)。
我可能漏掉了什么,但,你的后盾看起来不错,。
import numpy as np
import math
class perceptronmonocouche(object):
def xor(self):
print('xor')
X = np.array([[1,1],[1,0],[0,1],[0,0]]) #X.shape = (4,2)
y = np.array([0,1,1,0])
w0 = np.array([[.9,.1],[.3,.5]]) #random weights layer0
w1 = np.array([.8,.7]) #random wights layer1
max_epochs = 10000
epochs = 0
agreed_convergence_error = 0.001
error = 1
decision_threshold = 0.5
while epochs <= max_epochs and error > agreed_convergence_error:
#forward pass
epochs += 1
youtput=[]
for i in range(X.shape[0]):#X.shape = (4,2)
#print('x0', X[i][0])
#print('x1', X[i][1])
h0 = self.sig(w0[0,0]*X[i][0] + w0[1,0]*X[i][1])
h1 = self.sig(w0[0,1]*X[i][0] + w0[1,1]* X[i][1])
y0 = self.sig(w1[0]* h0 + w1[1] * h1) # shape = (4,)
youtput.append(y0)
if epochs%1000 ==0:
print('y0',y0)
if y0 > decision_threshold:
prediction = 1
else:
prediction = 0
print('real value', y[i])
print('predicted value', prediction)
#backpropagation
dey0 = -(y[i]-y0) # y[i] -> desired output | y0 -> output
dew0_00 = dey0 * y0 * (1 - y0) * w1[0] * h0 * (1 - h0) * X[i][0]
dew0_01 = dey0 * y0 * (1 - y0) * w1[1] * h1 * (1 - h1) * X[i][0]
dew0_10 = dey0 * y0 * (1 - y0) * w1[0] * h0 * (1 - h0) * X[i][1]
dew0_11 = dey0 * y0 * (1 - y0) * w1[1] * h1 * (1 - h1) * X[i][1]
dew1_0 = dey0 * h0
dew1_1 = dey0 * h1
w0[0,0] = self.gradient(w0[0,0], dew0_00)
w0[0,1] = self.gradient(w0[0,1], dew0_01)
w0[1,0] = self.gradient(w0[1,0], dew0_10)
w0[1,1] = self.gradient(w0[1,1], dew0_11)
w1[0] = self.gradient(w1[0], dew1_0)
w1[1] = self.gradient(w1[1], dew1_1)
#print('print W0, ', w0)
#print('print W1, ', w1)
error = self.error(y,youtput )
if epochs%1000 ==0:
print('error -> ', error)
def gradient(self, w, w_derivative):
alpha = .2
w = w - alpha * w_derivative
return w
def error(self, y, yhat):
e = 0
for i in range (y.shape[0]):
e = e + .5 * (y[i]- yhat[i])**2
return e
def sig(self,x):
return 1 / (1 + math.exp(-x))
p = perceptronmonocouche()
p.xor()结果
y0 0.05892656406522486
real value 0
predicted value 0
y0 0.9593864604895951
real value 1
predicted value 1
y0 0.9593585562506973
real value 1
predicted value 1
y0 0.03119936553811551
real value 0
predicted value 0
error -> 0.003873463452052477备注:在这里,它工作良好,没有偏倚,但是我建议您可以在任何时候允许偏差进行传播。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59399842
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号