
库存数据下载python无库
库存数据下载python无库
提问于 2019-12-23 14:35:18
我正在为学校编写一个项目(A级),并需要能够下载库存数据并绘制图表。我能够使用matplotlib绘制数据图表。然而,我只能使用一定数量的库。
我需要在不导入库的情况下获取数据,但无法做到。我尝试过从下载,但是crumb不断变化,所以我总是从错误的cookie中获得错误。
我怎么才能解决这个问题?还是有一个更容易获得数据的网站?
我的代码:
import requests
r = requests.get("query1.finance.yahoo.com/v7/finance/download/…)
file = open(r"MSFT.csv", 'w')
file.write(r.text) file.close()回答 2
Stack Overflow用户
发布于 2019-12-23 14:52:47
从https://datahub.io下载数据,否则您可以订阅来自不同交易所的第三方供应商的实时数据提要。
Stack Overflow用户
发布于 2020-03-10 14:30:07
你说:“我只能使用一定数量的图书馆。”那是什么意思?你应该可以使用任何你需要使用的库,对吧。运行下面的脚本。它将从雅虎下载股票数据并绘制时间序列。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.optimize as sco
import datetime as dt
import math
from datetime import datetime, timedelta
from pandas_datareader import data as wb
from sklearn.cluster import KMeans
np.random.seed(777)
start = '2019-4-30'
end = '2019-10-31'
# N = 90
# start = datetime.now() - timedelta(days=N)
# end = dt.datetime.today()
tickers = ['MMM',
'ABT',
'ABBV',
'ABMD',
'AAPL',
'XEL',
'XRX',
'XLNX',
'XYL',
'YUM',
'ZBH',
'ZION',
'ZTS']
thelen = len(tickers)
price_data = []
for ticker in tickers:
prices = wb.DataReader(ticker, start = start, end = end, data_source='yahoo')[['Adj Close']]
price_data.append(prices.assign(ticker=ticker)[['ticker', 'Adj Close']])
df = pd.concat(price_data)
df.dtypes
df.head()
df.shape
pd.set_option('display.max_columns', 500)
df = df.reset_index()
df = df.set_index('Date')
table = df.pivot(columns='ticker')
# By specifying col[1] in below list comprehension
# You can select the stock names under multi-level column
table.columns = [col[1] for col in table.columns]
table.head()
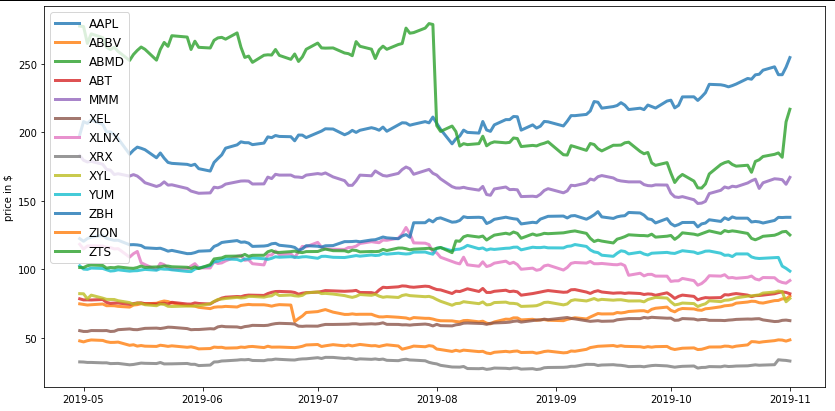
plt.figure(figsize=(14, 7))
for c in table.columns.values:
plt.plot(table.index, table[c], lw=3, alpha=0.8,label=c)
plt.legend(loc='upper left', fontsize=12)
plt.ylabel('price in $')
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59457048
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号