
如何解析游标ANSI转义代码?
我正在编写用于处理jQuery终端光标的ANSI转义代码的代码。但有问题,不知道该怎么做,我得到了奇怪的结果。
我在用艾维图书馆做测试。
并使用以下代码:
function scatter_plot() {
const scatterData = [];
for (let i = 1; i < 17; i++) {
i < 6 ? scatterData.push({ key: 'A', value: [i, i], style: ervy.fg('red', '*') })
: scatterData.push({ key: 'A', value: [i, 6], style: ervy.fg('red', '*') });
}
scatterData.push({ key: 'B', value: [2, 6], style: ervy.fg('blue', '# '), side: 2 });
scatterData.push({ key: 'C', value: [0, 0], style: ervy.bg('cyan', 2) });
var plot = ervy.scatter(scatterData, { legendGap: 18, width: 15 });
// same as Linux XTERM where 0 code is interpreted as 1.
var formatting = $.terminal.from_ansi(plot.replace(/\x1b\[0([A-D])/g, '\x1b[1$1'));
return formatting;
}
$.terminal.defaults.formatters = [];
var term = $('body').terminal();
term.echo(scatter_plot());在Linux中应该是这样的:
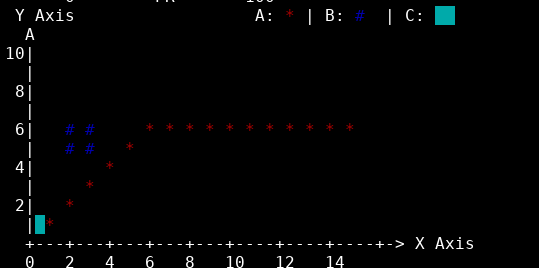
但是看起来是这样的,参见代码演示

当我写这个问题时,更改了几个+1和-1 (请参阅代码中的ANSI转义),移动光标时给出这个结果(代码片段有最新的代码)。
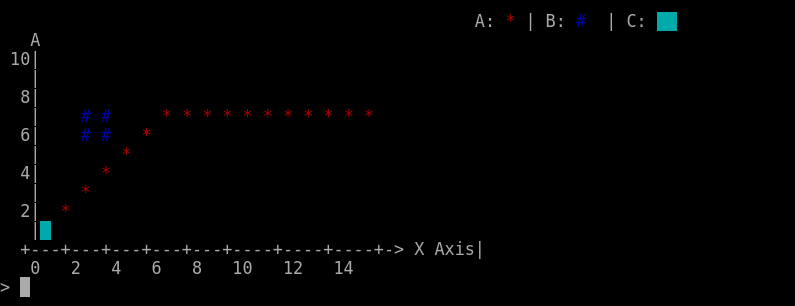
第一行被空格覆盖,整个情节是从上到右各一行(除了0,0个青色点,应该在“x”下面,宽2个字符,所以你应该看到右边的一半,这个是正确的,但其余的不是)。
这是我用来处理光标的新代码,我在处理颜色之前就这样做了,所以代码没有那么复杂。
// -------------------------------------------------------------------------------
var ansi_re = /(\x1B\[[0-9;]*[A-Za-z])/g;
var cursor_re = /(.*)\r?\n\x1b\[1A\x1b\[([0-9]+)C/;
var move_cursor_split = /(\x1b\[[0-9]+[A-G])/g;
var move_cursor_match = /^\x1b\[([0-9]+)([A-G])/;
// -------------------------------------------------------------------------------
function parse_ansi_cursor(input) {
/*
(function(log) {
console.log = function(...args) {
if (true || cursor.y === 11) {
return log.apply(console, args);
}
};
})(console.log);
*/
function length(text) {
return text.replace(ansi_re, '').length;
}
function get_index(text, x) {
var splitted = text.split(ansi_re);
var format = 0;
var count = 0;
var prev_count = 0;
for (var i = 0; i < splitted.length; i++) {
var string = splitted[i];
if (string) {
if (string.match(ansi_re)) {
format += string.length;
} else {
count += string.length;
if (count >= x) {
var rest = x - prev_count;
return format + rest;
}
prev_count = count;
}
}
}
return i;
}
// ansi aware substring, it just and add removed ansi escapes
// at the beginning we don't care if the were disabled with 0m
function substring(text, start, end) {
var result = text.substring(start, end);
if (start === 0 || !text.match(ansi_re)) {
return result;
}
var before = text.substring(0, start);
var match = before.match(ansi_re);
if (match) {
return before.match(ansi_re).join('') + result;
}
return result;
}
// insert text at cursor position
// result is array of splitted arrays that form single line
function insert(text) {
if (!text) {
return;
}
if (!result[cursor.y]) {
result[cursor.y] = [];
}
var index = 0;
var sum = 0;
var len, after;
function inject() {
index++;
if (result[cursor.y][index]) {
result[cursor.y].splice(index, 0, null);
}
}
if (cursor.y === 11) {
//debugger;
}
if (text == "[46m [0m") {
//debugger;
}
console.log({...cursor, text});
if (cursor.x === 0 && result[cursor.y][index]) {
source = result[cursor.y][0];
len = length(text);
var i = get_index(source, len);
if (length(source) < len) {
after = result[cursor.y][index + 1];
if (after) {
i = get_index(after, len - length(source));
after = substring(after, i);
result[cursor.y].splice(index, 2, null, after);
} else {
result[cursor.y].splice(index, 1, null);
}
} else {
after = substring(source, i);
result[cursor.y].splice(index, 1, null, after);
}
} else {
var limit = 100000; // infite loop guard
var prev_sum = 0;
// find in which substring to insert the text
while (index < cursor.x) {
if (!limit--) {
warn('[WARN] To many loops');
break;
}
var source = result[cursor.y][index];
if (!source) {
result[cursor.y].push(new Array(cursor.x - prev_sum).join(' '));
index++;
break;
}
if (sum === cursor.x) {
inject();
break;
}
len = length(source);
prev_sum = sum;
sum += len;
if (sum === cursor.x) {
inject();
break;
}
if (sum > cursor.x) {
var pivot = get_index(source, cursor.x - prev_sum);
var before = substring(source, 0, pivot);
var end = get_index(source, length(text));
after = substring(source, pivot + end);
if (!after.length) {
result[cursor.y].splice(index, 1, before);
} else {
result[cursor.y].splice(index, 1, before, null, after);
}
index++;
break;
} else {
index++;
}
}
}
cursor.x += length(text);
result[cursor.y][index] = text;
}
if (input.match(move_cursor_split)) {
var lines = input.split('\n').filter(Boolean);
var cursor = {x: 0, y: -1};
var result = [];
for (var i = 0; i < lines.length; ++i) {
console.log('-------------------------------------------------');
var string = lines[i];
cursor.x = 0;
cursor.y++;
var splitted = string.split(move_cursor_split).filter(Boolean);
for (var j = 0; j < splitted.length; ++j) {
var part = splitted[j];
console.log(part);
var match = part.match(move_cursor_match);
if (match) {
var ansi_code = match[2];
var value = +match[1];
console.log({code: ansi_code, value, ...cursor});
if (value === 0) {
continue;
}
switch (ansi_code) {
case 'A': // UP
cursor.y -= value;
break;
case 'B': // Down
cursor.y += value - 1;
break;
case 'C': // forward
cursor.x += value + 1;
break;
case 'D': // Back
cursor.x -= value + 1;
break;
case 'E': // Cursor Next Line
cursor.x = 0;
cursor.y += value - 1;
break;
case 'F': // Cursor Previous Line
cursor.x = 0;
cursor.y -= value + 1;
break;
}
if (cursor.x < 0) {
cursor.x = 0;
}
if (cursor.y < 0) {
cursor.y = 0;
}
} else {
insert(part);
}
}
}
return result.map(function(line) {
return line.join('');
}).join('\n');
}
return input;
}代码中的result = [];是一行的数组,当在游标处插入文本时,单行可能被分割成多个子字符串,如果它们是字符串数组,代码可能会更简单。现在我只想修复光标的位置。
下面是嵌入了代码演示函数的from_ansi (在里面有问题的parse_ansi_cursor )。很抱歉有很多代码,但是解析ANSI转义代码并不简单。
我不知道该如何工作的是移动光标(现在它有+1或- 1,我不确定这一点),我也不确定是否应该在每一行之前增加cursor.y。我不能百分之百确定该怎么做。我研究过Linux代码,但没有发现任何线索。看看Xterm.js,但是对于那些散点图,常春藤图完全被打破了。
我的from_ansi函数的原始代码正在处理一些ANSI游标代码,如下所示:
input = input.replace(/\x1b\[([0-9]+)C/g, function(_, num) {
return new Array(+num + 1).join(' ');
});只有C,向前只是添加空白,它是为ANSI艺术工作,但不工作与常春藤散点图。
我认为它不太广泛,这只是关于移动光标和使用ANSI转义代码处理换行符的问题。此外,应该是简单的情况,光标应该只在单个字符串中移动,而不是像在实际终端中那样在外部移动(像这样的ervy绘图输出ANSI转义代码)。
我对解释如何处理字符串以及如何移动将工作的游标的答案都很满意,但是如果您能够为代码提供修复,我将是很棒的。与现在的代码相比,我更喜欢修复,除非是一个简单得多的新实现,它是一个函数parse_ansi_cursor(input),与代码的其余部分一样工作,但使用的是固定的光标移动。
编辑:--我发现我的input.split('\n').filter(Boolean)错了--应该是:
var lines = input.split('\n');
if (input.match(/^\n/)) {
lines.shift();
}
if (input.match(/\n$/)) {
lines.pop();
}似乎有些ANSI转义的旧规范说0不是零,而是默认的占位符,即1。这已经从规范中删除了,但是Xterm仍然在使用它。所以我增加了这一行来解析代码,如果有0A或A值为1。
var value = match[1].match(/^0?$/) ? 1 : +match[1];情节看起来更好,但光标仍然存在问题。(我认为是光标--我不是百分之百确定)。
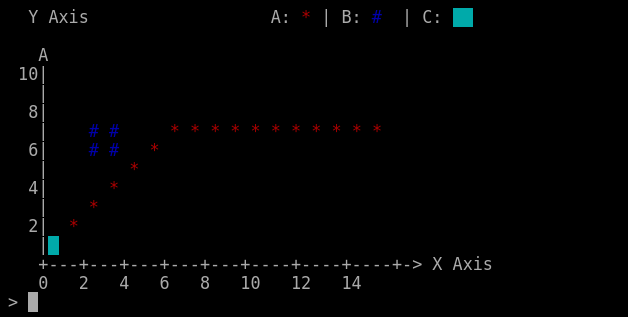
我再次更改了+1/-1,现在它更接近了(几乎与XTerm中的相同)。巴斯仍然需要在我的代码中出现bug。
编辑
在回答@jerch之后,我尝试使用节点ansi解析器,有同样的问题不知道如何处理游标:
var cursor = {x:0,y:0};
result = [];
var terminal = {
inst_p: function(s) {
var line = result[cursor.y];
if (!line) {
result[cursor.y] = s;
} else if (cursor.x === 0) {
result[cursor.y] = s + line.substring(s.length);
} else if (line.length < cursor.x) {
var len = cursor.x - (line.length - 1);
result[cursor.y] += new Array(len).join(' ') + s;
} else if (line.length === cursor.x) {
result[cursor.y] += s;
} else {
var before = line.substring(0, cursor.x);
var after = line.substring(cursor.x + s.length);
result[cursor.y] = before + s + after;
}
cursor.x += s.length;
console.log({s, ...cursor, line: result[cursor.y]});
},
inst_o: function(s) {console.log('osc', s);},
inst_x: function(flag) {
var code = flag.charCodeAt(0);
if (code === 10) {
cursor.y++;
cursor.x = 0;
}
},
inst_c: function(collected, params, flag) {
console.log({collected, params, flag});
var value = params[0] === 0 ? 1 : params[0];
switch(flag) {
case 'A': // UP
cursor.y -= value;
break;
case 'B': // Down
cursor.y += value - 1;
break;
case 'C': // forward
cursor.x += value;
break;
case 'D': // Back
cursor.x -= value;
break;
case 'E': // Cursor Next Line
cursor.x = 0;
cursor.y += value;
break;
case 'F': // Cursor Previous Line
cursor.x = 0;
cursor.y -= value;
break;
}
},
inst_e: function(collected, flag) {console.log('esc', collected, flag);},
inst_H: function(collected, params, flag) {console.log('dcs-Hook', collected, params, flag);},
inst_P: function(dcs) {console.log('dcs-Put', dcs);},
inst_U: function() {console.log('dcs-Unhook');}
};
var parser = new AnsiParser(terminal);
parser.parse(input);
return result.join('\n');这只是一个简单的例子,它忽略了除了换行符和光标移动之外的所有内容。
这是输出:
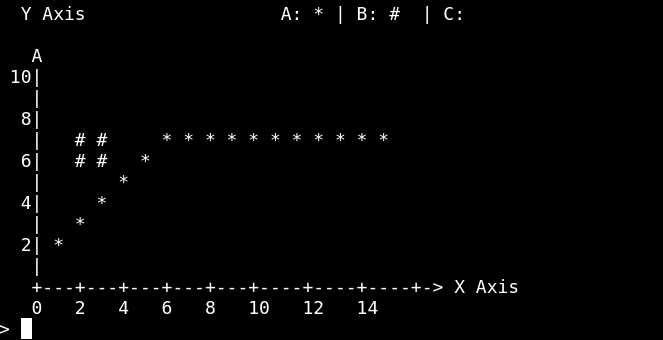
更新
似乎每一个游标的移动都应该是+= value或-= value,而我的value - 1;只是在纠正未在清晰终端上工作的ervy库中的错误。
回答 1
Stack Overflow用户
发布于 2019-12-29 16:18:49
首先,基于Regexp的方法不适合处理转义序列。造成这种情况的原因是各种终端序列之间复杂的交互作用,因为有些中断了一个尚未关闭的序列,而另一些则继续在另一个中间工作(比如一些控制代码),而“外部”序列仍将正确完成。您将不得不将所有这些边缘情况引入到每个regexp中(参见https://github.com/xtermjs/xterm.js/issues/2607#issuecomment-562648768中的示例)。
一般来说,解析转义序列是相当棘手的,我们甚至在终端-wg中也有一个问题。希望将来我们能从这方面得到一些最小的解析需求。当然,它不是基于regexp的;)
尽管如此,使用一个真正的解析器来处理所有的边缘情况要容易得多。DEC兼容解析器的一个很好的起点是解析器。对于游标处理,至少必须使用所有操作来处理这些状态:
- 接地
- 转义
- csi_entry
- csi_ignore
- csi_param
- csi_intermediate
加上所有其他状态作为虚拟条目。此外,控制代码需要特别小心(动作execute),因为它们可能在任何时候与任何其他具有不同结果的序列进行交互。
更糟糕的是,官方ECMA-48规范在某些方面与DEC解析器略有不同。尽管如此,现在使用的大多数仿真器都试图实现DEC VT100+的兼容性。
如果您不想自己编写解析器,您可以使用/修改我的旧解析器,也可以使用我们在xterm.js中拥有的解析器(后者可能更难集成,因为它在UTF32代码点上运行)。
https://stackoverflow.com/questions/59519577
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号