
AWS Neptune DB对Dynamo DB的实体血统
我试图评估对以下用例最有效的方法:
存在一组可以表示为图的实体。图中的每个顶点代表一个实体,每个顶点(单向边)表示子-父关系。一个实体可能有多个父实体,而父实体可能有多个子实体。通常,有一个“主”实体,所有实体都可以追溯到该实体。任何实体都不能移除。要求应该很容易地跟踪任何实体的所有祖先。以下是我要根据的一些条件来评价:
- 深树(最高祖先可以是很远的)与浅树(最高祖先通常并不遥远)
- 宽遍历路径(顶点可以有多个父)与窄遍历路径(顶点通常没有很多父母)
- 还有其他一些我忽略了
的重要条件
以此图为例:
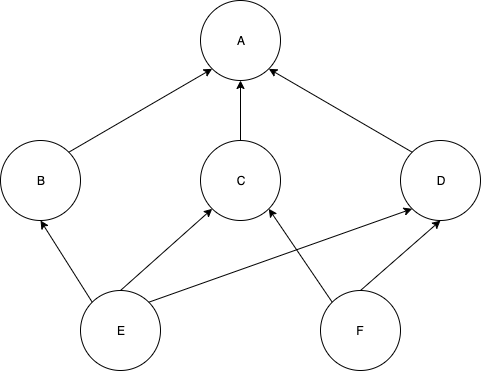
在类似于DynamoDB的常规数据库中,这将表示为:
-------------------
entity | parents |
-------------------
A | [] |
-------------------
B | [A] |
-------------------
C | [A] |
-------------------
D | [A] |
-------------------
E | [B, C, D]|
-------------------
F | [C, D] |
-------------------已存在的一种情况是:
我对DynamoDB要熟悉得多,但对NeptuneDB或任何图形数据库只有非常基本的熟悉,因此DynamoDB需要较少的前期投资。另一方面,NeptuneDB当然更适合关系图存储,但是在什么条件下值得技术开销?
回答 1
Stack Overflow用户
发布于 2020-01-05 17:42:39
当然,有许多方法来建模和存储连接的数据。正如您所观察到的,您可以使用邻接列表存储图,如您的示例所示。在处理高度连接的数据时,图数据库(如Amazon )确实可以帮助创建和执行查询。例如,使用Gremlin查询语言(Neptune同时支持TinkerPop/Gremlin和RDF/SPARQL),查找顶点'E“的最远祖先可能非常简单:
g.V('E').repeat(out()).until(__.not(out()))不管树有多深,查询都保持不变。如果要使用邻接列表对数据建模,则必须编写代码亲自遍历“图”。像Amazon这样的图形数据库引擎被优化以有效地执行这些类型的查询。
总之,您可以使用Dynamo或Neptune来完成这个任务,但是如果图形变得复杂,那么使用带有内置图形查询功能的graph应该可以使您在编写查询以遍历图形时更加轻松。正如您注意到的,这个决定将取决于重用您已经知道的知识与学习一些新的东西以获得轻松编写和执行查询的能力之间的权衡,而不管连接的数据变得多么复杂。我希望这能帮你做出决定。
您将在这里找到一个使用Gremlin建模和遍历树的简单示例:
http://www.kelvinlawrence.net/book/PracticalGremlin.html#btree
https://stackoverflow.com/questions/59594628
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号