
OpenMP加速损耗
我使用OpenMP来加速我的程序,它正在寻找文本中的模式。
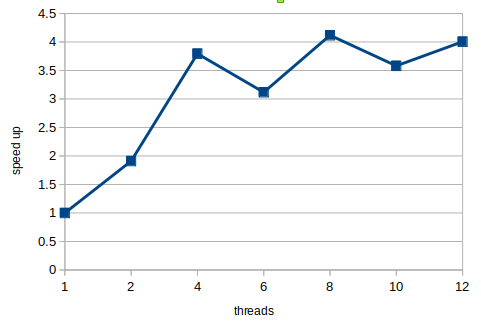
问题:为什么会在6个线程和10个线程上加速丢失,然后在8个线程和12个线程上增加(图表如下)?我认为提速线应该更直(更多的线程=加速增长)。我尝试使用不同的文本大小,算法和块的数目,但图表没有改变。
程序/设备信息
blocks
- omp_max_threads()
- 文本除以10000
返回8
- 文本大小为有4核
码
double start = omp_get_wtime();
#pragma omp parallel for shared(pat, blockTxt, numOfBlocks,patSize) private (i) reduction(+:result)
for (i = 0; i < numOfBlocks; i++) {
result += Alghorithm().naive(pat, blockTxt[i], patSize, blockTxt[i].size());
}
double end = omp_get_wtime();图
回答 1
Stack Overflow用户
发布于 2020-01-14 07:12:37
你似乎认为“更多的线程=加速增长”的想法从根本上讲是错误的。您应该争取的是尽可能充分和有效地使用您拥有的硬件能力,以减少解决问题所需的时间。
有时(通常),这会转化为并行化问题,并在计算机提供的各种处理单元之间分配工作。但大多数情况下(并不总是,但反例是非常罕见的),超载您的处理单元(基本上)与多个线程或处理每个进程,只会减慢整体计算。因此,对于高效的并行处理,您的目标如下:
them
- Distribute
- 将工作/问题分解成可以彼此独立解决的小块,同时增加尽可能少的额外工作,以便将这些较小的任务重新组合到您可以访问的各个处理单元:
- --所有这些任务都是繁忙的
- --它们都需要在尽可能多的时间内完成--即使在它们之间,分发工作并将其重新组合起来的开销越小,
H 111也越小,最重要的是,以确保尚未并行化的工作部分与possible
一样小
在你的例子中,由于你有4个核心可用,你想要的是让他们4个繁忙,与大约相同的工作量为每个。
我不知道对搜索算法的每个小调用是否具有相同的大小,但它们是否相同,那么有4个线程的最优总体加速比的可能性是最高的。
现在,由于每个内核实际上有两个硬件线程,所以每个线程都有可能允许更好地使用手头的硬件。对于计算量大的问题,通常不是这样的,但是您的问题显然不是很好,因为实际上,当使用8个线程时,加速效果会稍微好一些:它达到了4,这基本上是您不应该超过的绝对限制(因为您有4个内核)。
为什么6会让你慢下来?如果你看看你的目标是什么,你应该意识到,如果有6个OpenMP线程在4个内核之间划分,你会在这些内核之间造成负载不平衡,并且,由于并行化的终结导致同步,一些核心将不得不等待其他内核完成他们在结束时的额外工作。这样的等待就足以削弱你的整体效率。10个线程的调制解调器。
最后,正如我所说的,您足够幸运的是,您的并行开销足够小,以至于8个线程给了您一个完美的加速比,甚至12 (它被4核平均除以).但是,这只会给你一个4的加速比,从根本上说,这是你的硬件能力的上限。
https://stackoverflow.com/questions/59723732
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号