
有没有办法得到条形图(颠倒)与百分之巨蟒的变化?
有没有办法得到条形图(颠倒)与百分之巨蟒的变化?
提问于 2020-01-21 22:15:53
我有贸易数据(按世界范围进口杂货产品的/export ),我打算绘制一些显示全球进出口贸易流量的地块。为此,我使用group_by,pivot_table来操作我的数据,这将用作绘图函数的输入。似乎我没有得到正确的操作我的数据,结果,我没有得到正确的阴谋,我期待的。有人能告诉我怎么做吗?谢谢
根据这些原始数据,我想向美国出口牛肉的前十名国家展示一下。我怎么能拿到呢?
极小示例
import numpy as np
import pandas as pd
df = pd.DataFrame(data=[list('EEEIEEIIEI'),
['AR', 'AUC', 'CA', 'CN', 'MX', 'MX', 'AR', 'IT', 'UK', 'RU'],
['ALBANIA', 'PAKISTN', 'UGANDA', 'FRANCE', 'USA', 'RUSSIA', 'COLOMBIA', 'KAZAK', 'KOREA', 'JAPAN'],
[20230, 20220, 20120, 20230, 20230, 20220, 20230, 20120, 20130, 20329],
list(np.random.randint(10, 100000, 10)),
list(np.random.randint(10, 100, 10)),
list(np.random.randint(10, 100, 10)),
np.random.choice(pd.date_range('1/1/2014', periods=365, freq='D'), 10, replace=False)]
).T
df.columns =['ID', 'cty', 'cty_ptn', 'prod_code', 'value','Quantity1', 'Quantity2', 'date']
my_dict={'20230':'Gas',
'20220':'Water',
'20210': 'Refined',
'20120':'Oil',
'20239':'Other'}
df['prod_label']=df['prod_code'].astype(str).map(my_dict)我的尝试
我尝试了以下创建条形图的操作:
import matplotlib.pyplot.plt
%matplotlib inline
mydf= mydf[(mydf['prod_label']=='Gas') & (mydf['ID']=='E')]更新尝试
mydf=mydf.groupby('cty_ptn')['value','Quantity1'].sum().reset_index()
mydf=mydf.nlargest(20, 'Quantity1')
## EDA
fig=plt.figure()
ax=fig.add_axes([0,0,1,1])
ax.scatter(mydf['Quantity1'].values, mydf['value'].values)我的当前输出
我得到了一个与我所期望的相去甚远的虚拟情节:
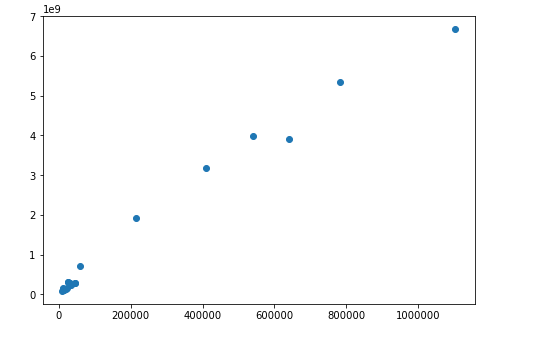
但我没有得到正确的情节(它是空的,我不知道为什么)。原因很可能是我错误地操作了数据,这些数据与matplotlib绘图函数的输入不匹配。有什么快速纠正的吗?
想要的地块
我正努力达到以下目的(受贸易数据报告的启发):
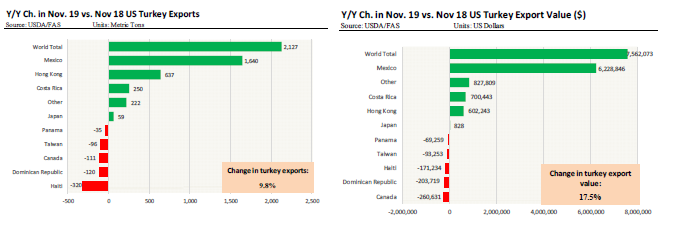
我怎样才能超越情节?在实现绘图函数之前,需要进行什么样的操作?谢谢
回答 1
Stack Overflow用户
发布于 2020-01-22 10:15:07
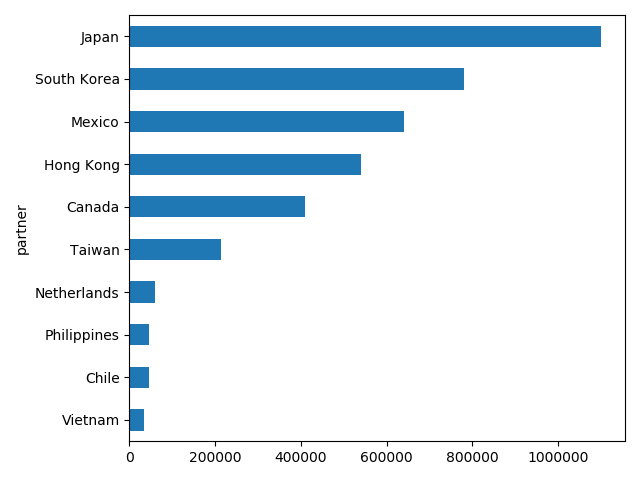
df = pd.read_csv('https://gist.githubusercontent.com/julaiti/cb2341b98110db8a82651c72e0ad57d5/raw/5ab24d37619adb720118d8d7742fa8c52d799492/minimal_dataset')
df.groupby(['partner'])['qty1'].sum().nlargest(10).plot(kind='barh')
plt.tight_layout()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59849985
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号