
在Python中迭代页面和爬虫HTML表
在Python中迭代页面和爬虫HTML表
提问于 2020-01-23 02:09:50
我尝试从这个链接爬行表,通过使用F12 F12获取表内容的位置。
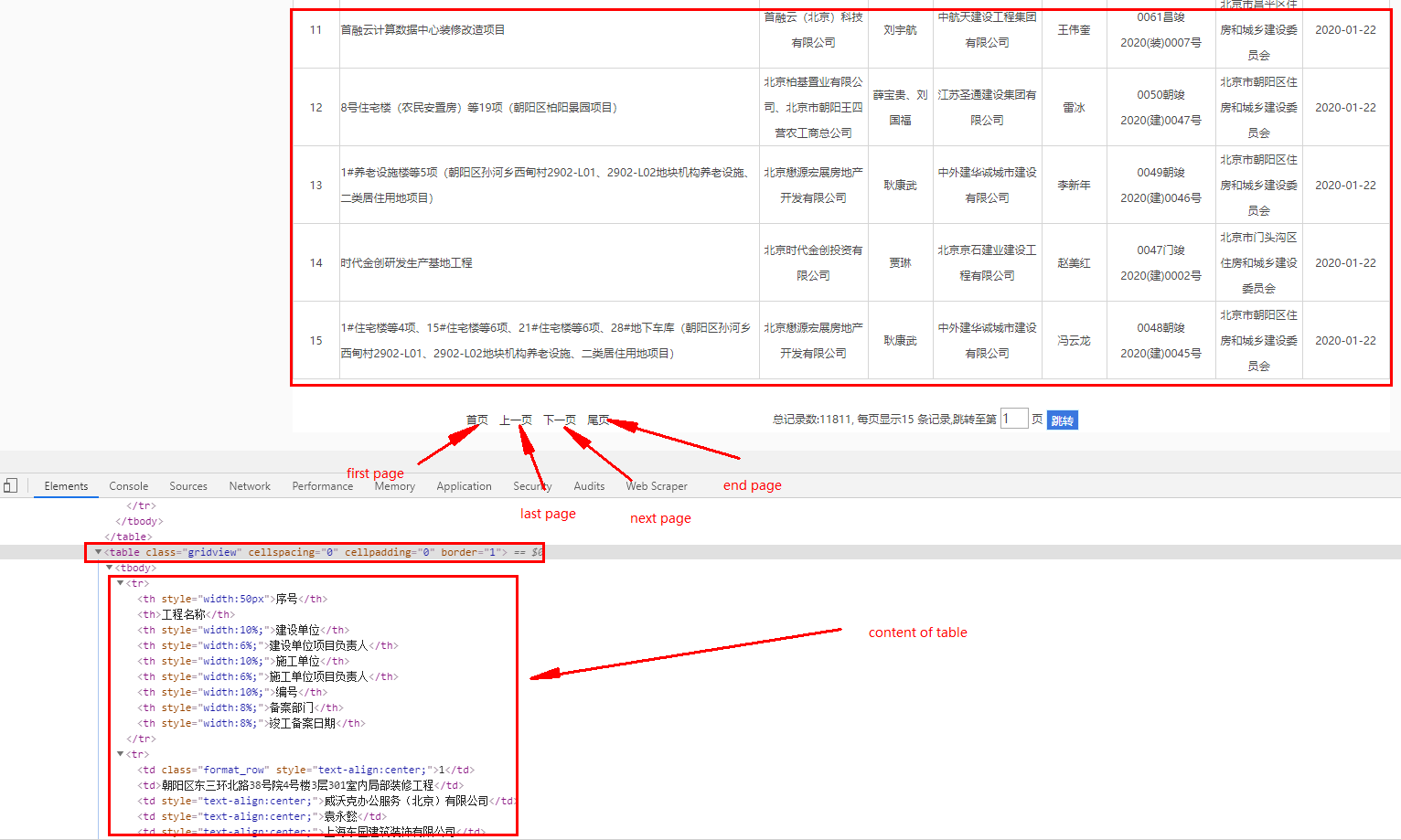
我用了下面的代码,但是我得到了None的结果,有人能帮忙吗?谢谢。
import requests
import json
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
url = 'http://bjjs.zjw.beijing.gov.cn/eportal/ui?pageId=308894'
website_url = requests.get(url).text
soup = BeautifulSoup(website_url, 'lxml')
table = soup.find('table', {'class': 'gridview'})
#table = soup.find('table', {'class': 'criteria'})
print(table)请也检查这个参考文献,事实上,我想在这里做类似的事情,但网页结构似乎不同。
更新的:下面的代码适用于一个页面,但我也需要循环其他页面。
import requests
import json
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
url = 'http://bjjs.zjw.beijing.gov.cn/eportal/ui?pageId=308894'
website_url = requests.get(url).text
soup = BeautifulSoup(website_url, 'lxml')
table = soup.find('table', {'class': 'gridview'})
#https://stackoverflow.com/questions/51090632/python-excel-export
df = pd.read_html(str(table))[0]
df.to_excel('test.xlsx', index = False)输出:
序号 ... 竣工备案日期
0 1 ... 2020-01-22
1 2 ... 2020-01-22
2 3 ... 2020-01-22
3 4 ... 2020-01-22
4 5 ... 2020-01-22
[5 rows x 9 columns]相关参考资料:
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-01-23 03:22:41
您可以在<tr>... </tr>标记中获得以下元素:
table = soup.find_all('table', {'class': 'gridview'})
for elements in table:
inner_elements = elements.findAll('tr')[1:]
for text_for_elements in inner_elements:
print(text_for_elements.text)产出:
1
朝阳区东三环北路38号院4号楼3层301室内局部装修工程
威沃克办公服务(北京)有限公司
袁永懿
上海东园建筑装饰有限公司
陈振华
0065朝竣2020(装)0053号
北京市朝阳区住房和城乡建设委员会
2020-01-22
2
北京市朝阳区新源南路3号14层04单元A1704室内装修工程
重庆金融资产交易所有限责任公司
罗珊珊
深圳安星建设集团有限公司
张惠富
0066朝竣2020(装)0054号
北京市朝阳区住房和城乡建设委员会
2020-01-22
......页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59870738
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号