
如何在熊猫的多栏中求取逐行求和的百分比?
如何在熊猫的多栏中求取逐行求和的百分比?
提问于 2020-01-29 21:03:51
我试图获得百分比表格数据,在那里我尝试使用交叉表函数从熊猫,但行wises和为每一列是不正确的(我用Excel和双倍检查这一点)。基本上,在我的进出口贸易数据中,我试图得到每个国家的期限百分比。
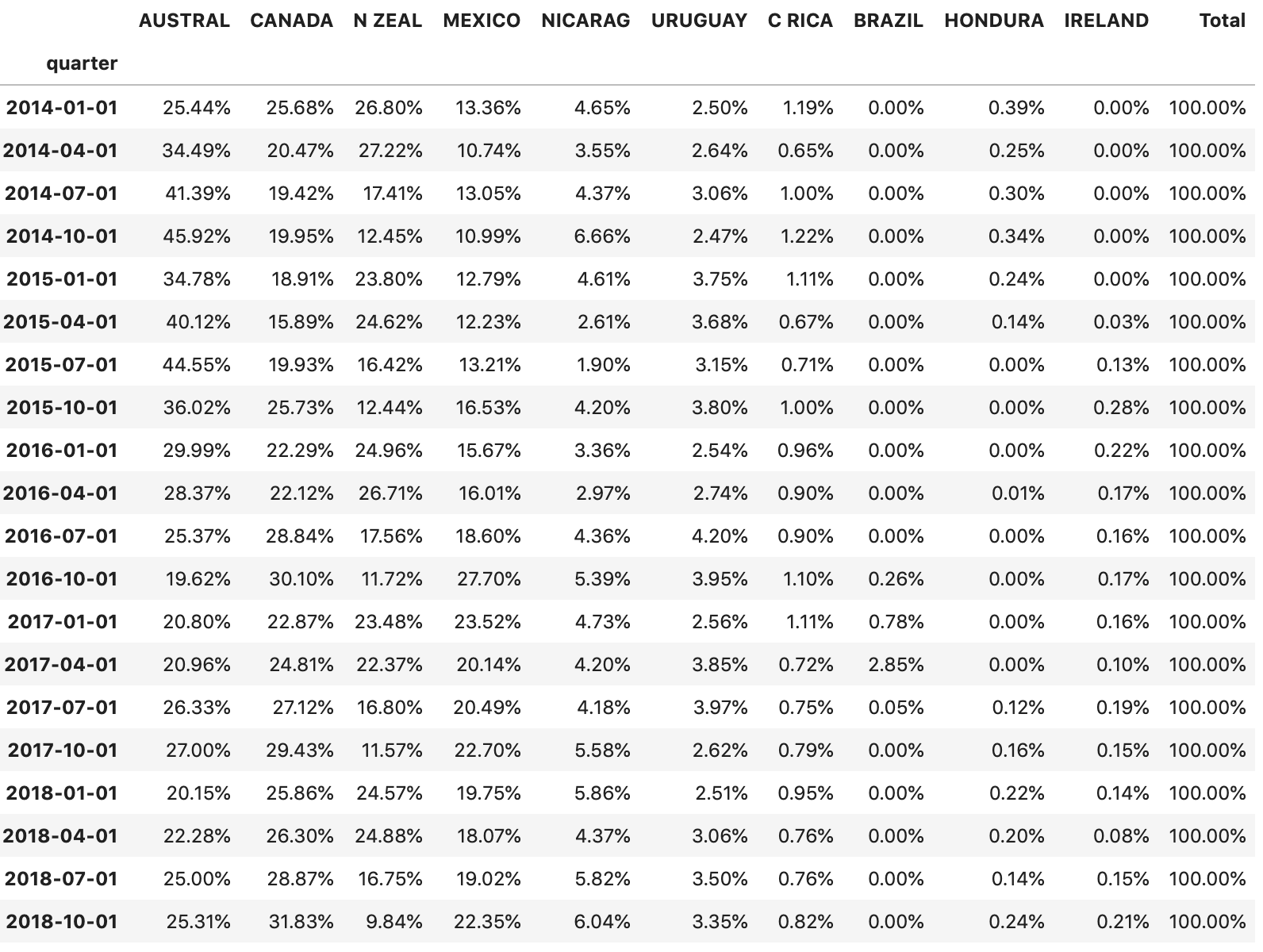
表格数据
这是公共要点表格数据,我想得到每个国家的百分比,按时期计算。
为了得到列的之和,我做了这样的事情:
import pandas as pd
df=pd.read_csv('minimal_data.csv', encoding='utf-8')
df.loc[:,'Total'] = df.sum(axis=1)但是这个和用excel求和的方法是不一样的。我也不知道原因。
然后,我试图通过以下方法获得百分比表数据:
pd.crosstab(index=df.index,
columns=df.columns,
values=df.columns.value,
aggfunc='sum',
normalize='index').applymap('{:.2f}%'.format)我期待着表格数据的百分比,其中每个国家的百分比按时期分列。我不知道为什么,在我的尝试,我没有得到正确的总和和预期百分比表。有人能指点我吗?有什么快速的解决办法吗?
我认为使用crosstab是正确的,但通过保留相同的行名和列名约定,我没有得到正确的百分比表。有什么办法让这件事成功吗?
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-01-29 21:16:45
你所说的“和”是错误的还是与Excel不同的,目前还不清楚。如果您想要计算出的总数的百分比,只需这样做就可以了(如果您已经将日期作为索引读取csv,那么这样做会更容易一些,即不需要设置索引):
df = df.set_index('quarter')
df.div(df.Total, axis=0).applymap(lambda x: f'{x * 100:.2f}%')
Stack Overflow用户
发布于 2020-01-29 21:33:12
为了得到百分比,
df.set_index('quarter').apply(lambda x: (x / x.sum())*100, axis=1)输出
AUSTRAL CANADA N ZEAL MEXICO NICARAG URUGUAY C RICA BRAZIL HONDURA IRELAND
quarter
2014-01-01 25.440018 25.682501 26.799560 13.356812 4.645008 2.502126 1.185601 0.000000 0.388373 0.000000
2014-04-01 34.489028 20.473965 27.223601 10.739338 3.545756 2.637722 0.645318 0.000000 0.245270 0.000000
2014-07-01 41.388462 19.418827 17.413776 13.046643 4.365293 3.062794 1.000460 0.000000 0.303746 0.000000
2014-10-01 45.921175 19.947340 12.453399 10.987784 6.659666 2.472346 1.220976 0.000000 0.337314 0.000000
2015-01-01 34.779864 18.914200 23.802183 12.789158 4.607413 3.750432 1.113557 0.000000 0.242027 0.001166
2015-04-01 40.115581 15.889617 24.620569 12.233570 2.614697 3.684628 0.669135 0.000000 0.140994 0.031210
2015-07-01 44.545033 19.933480 16.419047 13.207045 1.903940 3.151725 0.706372 0.000000 0.000000 0.133357
2015-10-01 36.019231 25.727244 12.442655 16.527229 4.201449 3.803939 0.998293 0.000000 0.000000 0.279961
2016-01-01 29.991387 22.293687 24.963800 15.665886 3.364758 2.537703 0.964889 0.000000 0.000000 0.217890
2016-04-01 28.368131 22.124064 26.707744 16.011170 2.974021 2.736466 0.902486 0.000000 0.008214 0.167704
2016-07-01 25.368992 28.843584 17.562638 18.601159 4.361163 4.197427 0.900461 0.001082 0.000000 0.163494
2016-10-01 19.623932 30.095599 11.720699 27.695783 5.386881 3.950341 1.098037 0.262948 0.000000 0.165780
2017-01-01 20.799706 22.871970 23.475104 23.519770 4.726189 2.564349 1.105563 0.777981 0.000000 0.159366
2017-04-01 20.961391 24.807151 22.372555 20.141108 4.201882 3.848614 0.717434 2.847786 0.000000 0.102079
2017-07-01 26.326774 27.124571 16.796464 20.485338 4.180663 3.973982 0.748360 0.050250 0.122305 0.191292
2017-10-01 26.996354 29.432880 11.569669 22.702213 5.579304 2.623607 0.794317 0.000000 0.156468 0.145188
2018-01-01 20.148823 25.861165 24.566617 19.748647 5.864245 2.507594 0.946862 0.000000 0.218396 0.137650
2018-04-01 22.281189 26.300865 24.879217 18.074004 4.368848 3.058836 0.757353 0.000000 0.196459 0.083229
2018-07-01 24.996713 28.873588 16.749910 19.016680 5.816461 3.499820 0.757308 0.000000 0.140196 0.149324
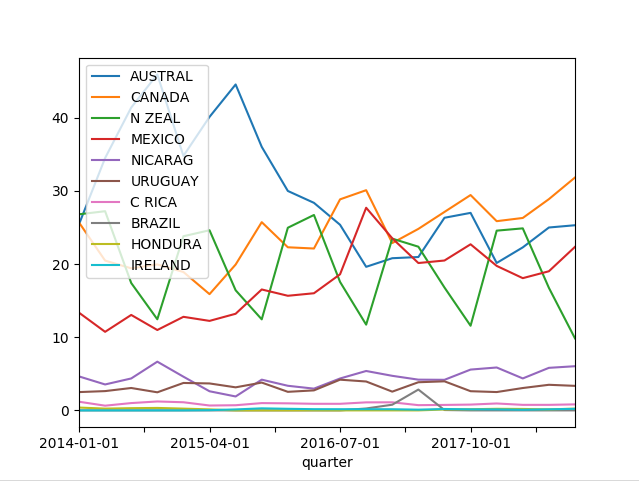
2018-10-01 25.305780 31.831372 9.842619 22.351502 6.039240 3.353802 0.824540 0.000000 0.236478 0.214668在线状图中绘制
>>> df.plot(kind='line')
<matplotlib.axes._subplots.AxesSubplot object at 0x7f418a3710b8>
>>> from matplotlib import pyplot as plt
>>> plt.show()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59975545
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号