
用Python绘制的美国地质调查局水文数据甘特图?
我有一个编译好的数据文件,其中包含了几个不同流量表上的USGS流数据。现在,我想创建一个类似于这的甘特图。目前,我的数据有列作为站点名,日期索引作为行。
这是我的数据的一个例子。
我所链接的甘特图示例的问题是,我的数据在开始日期和结束日期之间存在差距,这通常会定义水平时间线。我发现的许多示例只说明了开始日期和结束日期,但没有遗漏可能介于两者之间的值。对于某些站点,如果没有数据(在这些值槽中没有空白或nan ),我该如何解释这些差距?
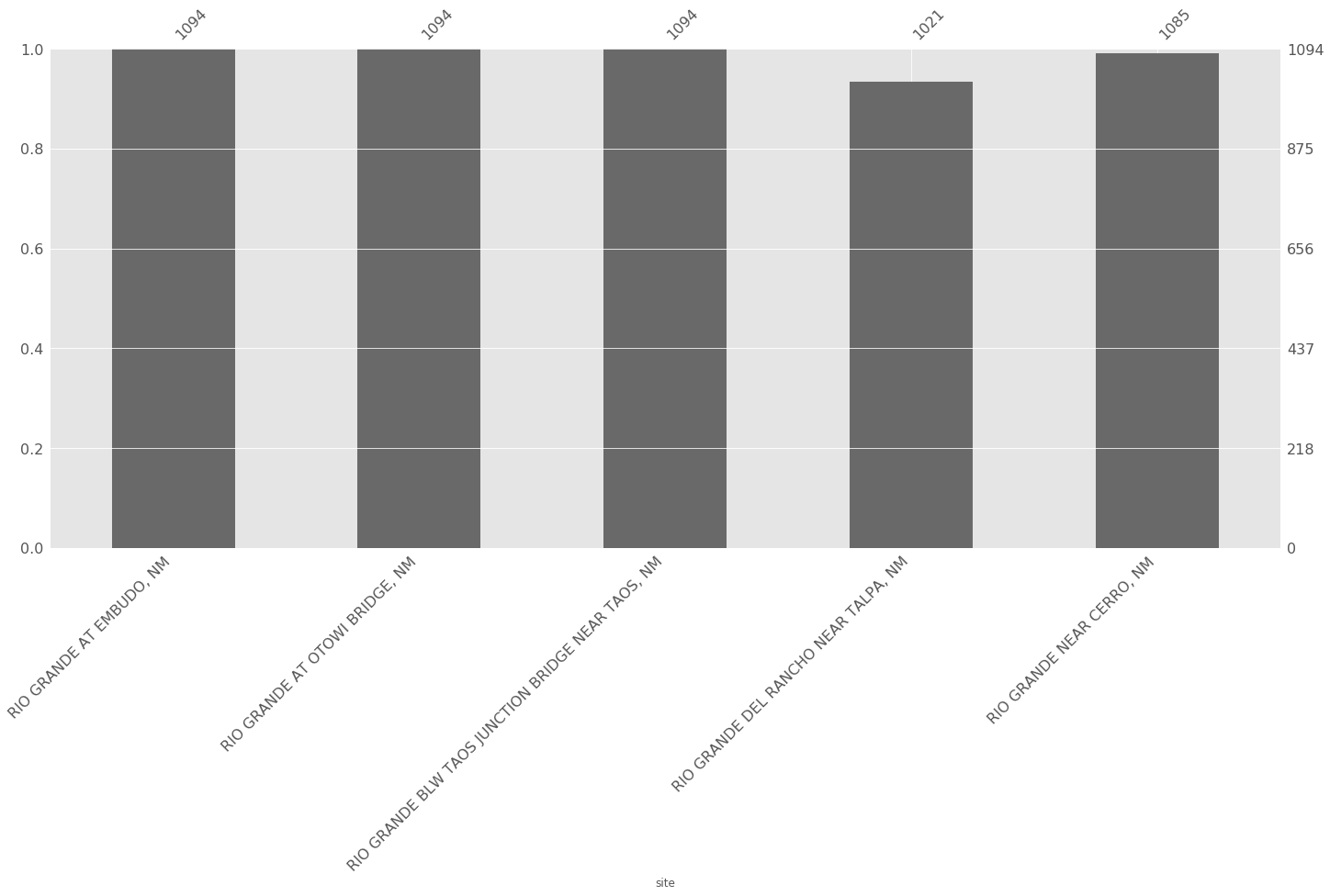
首先,我有一个显示丢失数据的位置的图。
import missingno as msno
msno.bar(dfp)
现在,我想要的是x轴上的时间和y轴上的一条水平线,它可以在那些时候跟踪站点包含数据的时间。我知道如何用蛮力的方式来实现这一点,这意味着手动选择有有效数据的起始日期和结束日期(我在下面组成)。
from datetime import datetime
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as dt
df=[('RIO GRANDE AT EMBUDO, NM','2015-7-22','2015-12-7'),
('RIO GRANDE AT EMBUDO, NM','2016-1-22','2016-8-5'),
('RIO GRANDE DEL RANCHO NEAR TALPA, NM','2014-12-10','2015-12-14'),
('RIO GRANDE DEL RANCHO NEAR TALPA, NM','2017-1-10','2017-11-25'),
('RIO GRANDE AT OTOWI BRIDGE, NM','2015-8-17','2017-8-21'),
('RIO GRANDE BLW TAOS JUNCTION BRIDGE NEAR TAOS, NM','2015-9-1','2016-6-1'),
('RIO GRANDE NEAR CERRO, NM','2016-1-2','2016-3-15'),
]
df=pd.DataFrame(data=df)
df.columns = ['A', 'Beg', 'End']
df['Beg'] = pd.to_datetime(df['Beg'])
df['End'] = pd.to_datetime(df['End'])
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111)
ax = ax.xaxis_date()
ax = plt.hlines(df['A'], dt.date2num(df['Beg']), dt.date2num(df['End']))
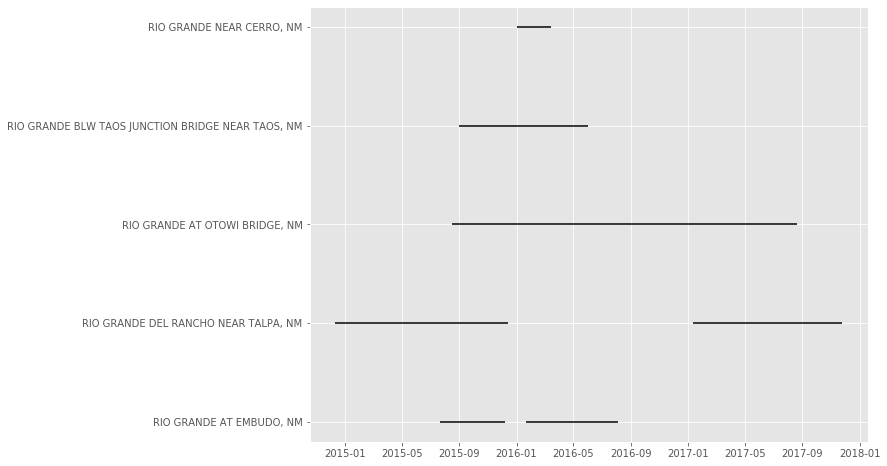
如何使用我提供的数据作为示例来生成一个图形(如上面所示)?理想情况下,我想避免使用蛮力法。
请注意:零的值被视为有效的数据点。
提前感谢您的反馈!
回答 2
Stack Overflow用户
发布于 2020-02-11 03:12:23
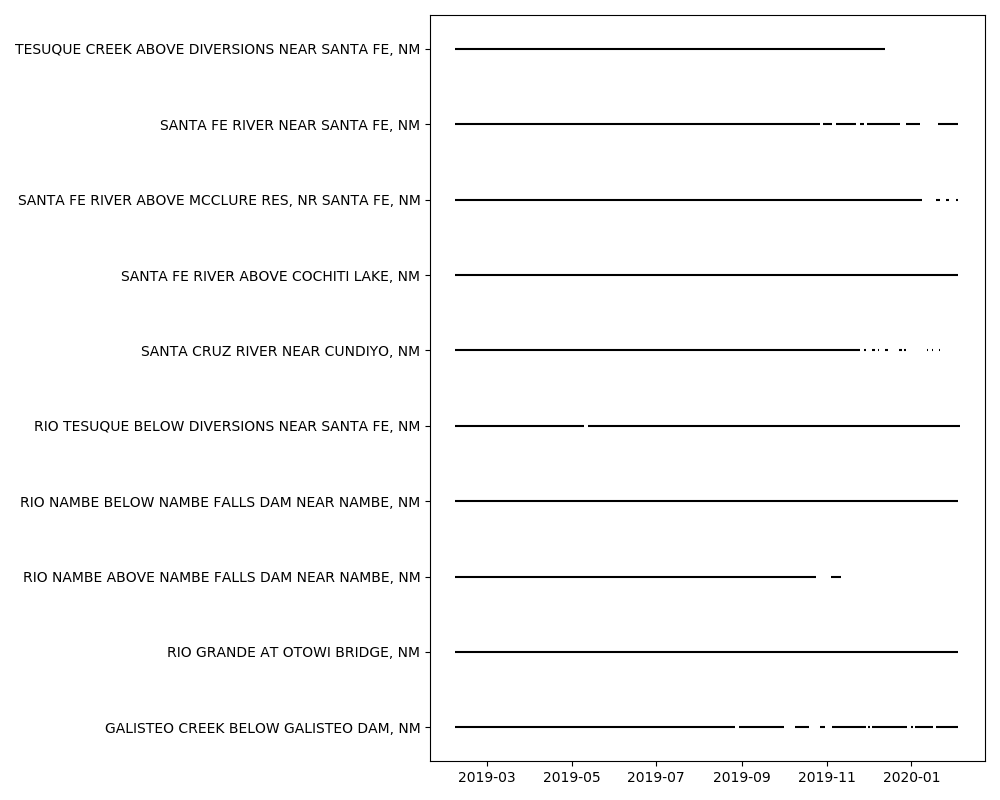
查找非空数据的日期范围
2020-02-12编辑澄清循环中的逻辑
df = pd.read_excel('Downloads/output.xlsx', index_col='date')确保日期按顺序排列:
df.sort_index(inplace=True)循环遍历数据,找出良好数据范围的边缘。获取相应的索引值和量规名称,并将它们全部收集到一个列表中:
# Looping feels like defeat. However, I'm not clever enough to avoid it
good_ranges = []
for i in df:
col = df[i]
gauge_name = col.name
# Start of good data block defined by a number preceeded by a NaN
start_mark = (col.notnull() & col.shift().isnull())
start = col[start_mark].index
# End of good data block defined by a number followed by a Nan
end_mark = (col.notnull() & col.shift(-1).isnull())
end = col[end_mark].index
for s, e in zip(start, end):
good_ranges.append((gauge_name, s, e))
good_ranges = pd.DataFrame(good_ranges, columns=['gauge', 'start', 'end'])绘图
这里没什么新鲜事。从你的问题中抄袭得很直接:
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111)
ax = ax.xaxis_date()
ax = plt.hlines(good_ranges['gauge'],
dt.date2num(good_ranges['start']),
dt.date2num(good_ranges['end']))
fig.tight_layout()
Stack Overflow用户
发布于 2020-02-07 20:29:21
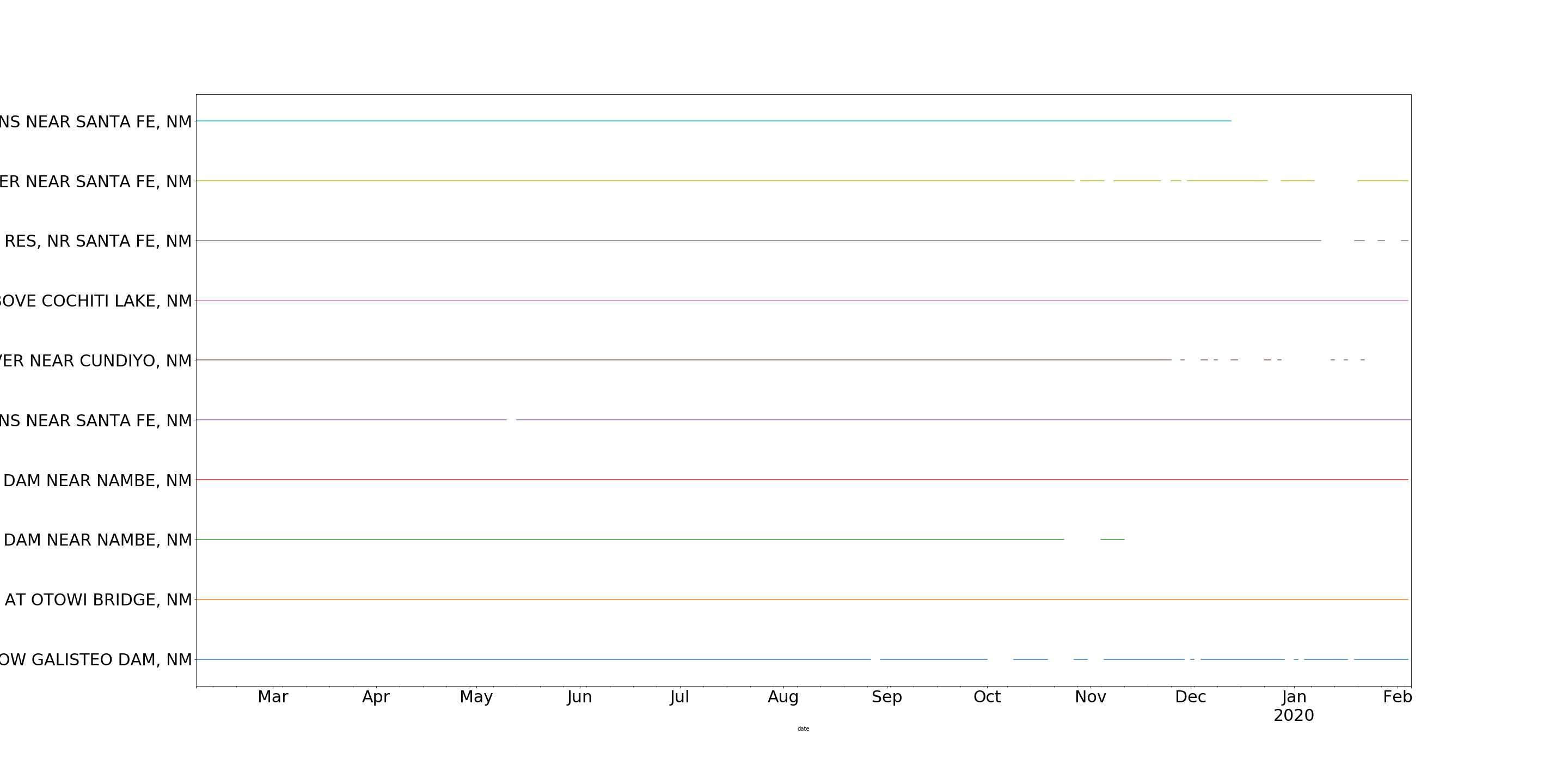
这里有一种您可以使用的方法,它有点麻烦,所以也许其他一些方法会产生一个更好的解决方案,但是它应该会产生您想要的输出。首先使用pd.where将非NaN值替换为一个整数,该整数稍后将确定y轴上直线的位置,然后逐行执行此操作,这样所有属于一起的数据都将位于相同的高度。如果您想要增加甘特图行间的间距,可以向i添加一个数字,我在下面代码块中的注释中提供了一个示例。
Y标签及其位置是在数据处理步骤中生成的,因此,无论列数多少,该方法都能工作,并且在更改上面描述的间距时将正确定位标签。
此方法返回matplotlib.pyplot.axes和matplotlib.pyplot.Figure对象,因此您可以调整图表的美观以适应您的目的(即改变线条的厚度、颜色等)。链接到文档。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_excel('output.xlsx')
dates = pd.to_datetime(df.date)
df.index = dates
df = df.drop('date', axis=1)
new_rows = [df[s].where(df[s].isna(), i) for i, s in enumerate(df, 1)]
# To increase spacing between lines add a number to i, eg. below:
# [df[s].where(df[s].isna(), i+3) for i, s in enumerate(df, 1)]
new_df = pd.DataFrame(new_rows)
### Plotting ###
fig, ax = plt.subplots() # Create axes object to pass to pandas df.plot()
ax = new_df.transpose().plot(figsize=(40,10), ax=ax, legend=False, fontsize=20)
list_of_sites = new_df.transpose().columns.to_list() # For y tick labels
x_tick_location = new_df.iloc[:, 0].values # For y tick positions
ax.set_yticks(x_tick_location) # Place ticks in correct positions
ax.set_yticklabels(list_of_sites) # Update labels to site names
https://stackoverflow.com/questions/60099737
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号