
Flink Hadoop用多个并行桶执行斗槽的性能
我正在调查一个Flink作业的性能,它将数据从Kafka传输到一个S3水槽。我们正在使用BucketingSink来编写拼花文件。存储逻辑将每个类型的数据、租户(客户)、日期-时间、提取Id等划分为一个文件夹。这导致每个文件存储在由9-10层组成的文件夹结构中(S3_桶:/1/2/3/4/5/6/7/8/9/myFile.
如果数据以突发消息的形式分发给租户类型,我们可以看到良好的书面性能,但是当数据更多地分布在数千个租户、数十个数据类型和多个提取is上时,我们就会失去难以置信的性能。(约为300倍)
附加调试器时,问题似乎与S3上同时打开的用于写入数据的处理程序的数量有关。更具体而言:
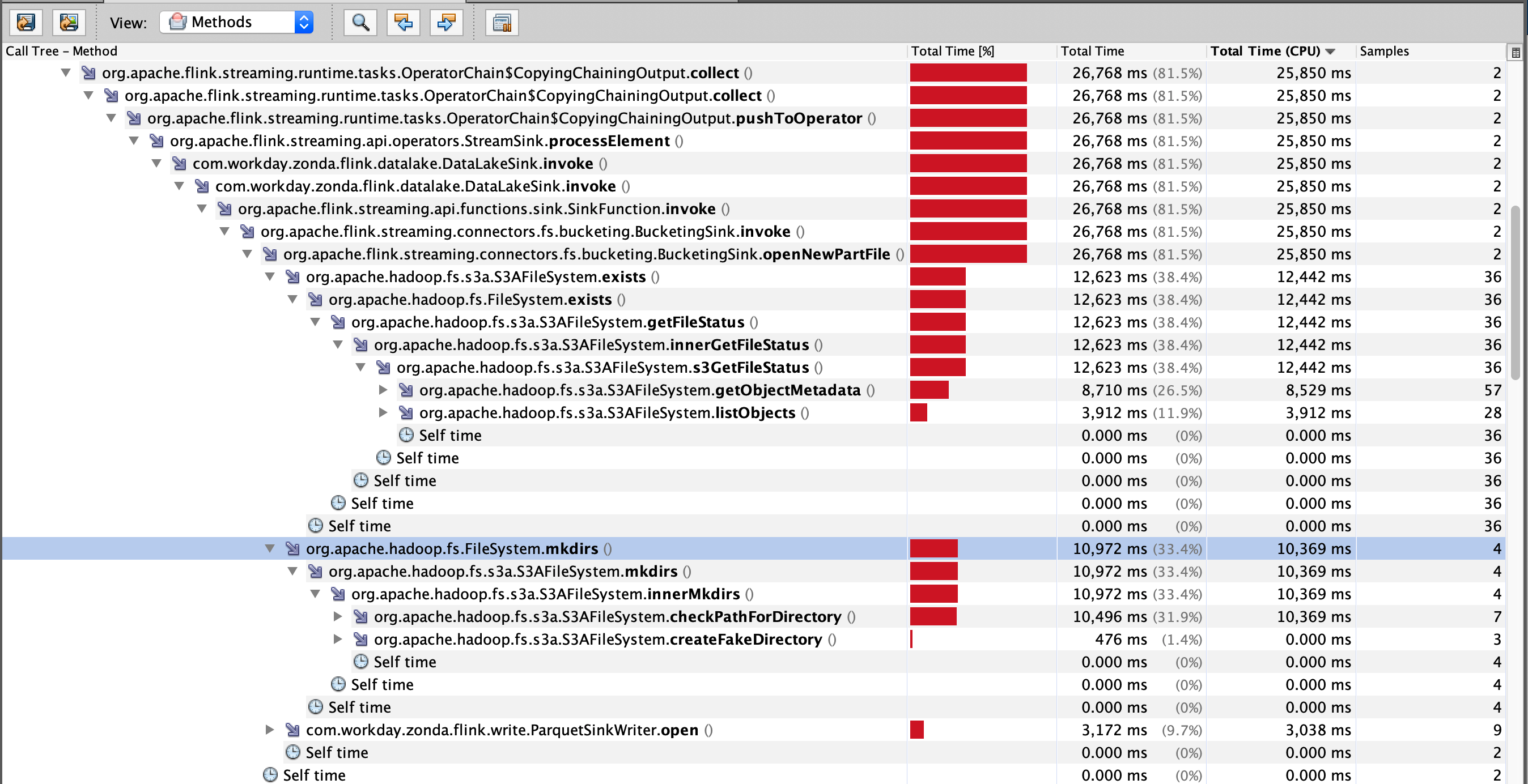
通过对用于向S3写入的hadoop库的研究,我发现了一些可能的改进设置:
<name>fs.s3a.connection.maximum</name>
<name>fs.s3a.threads.max</name>
<name>fs.s3a.threads.core</name>
<name>fs.s3a.max.total.tasks</name>但所有这些都没有对吞吐量产生很大影响。我还试图将文件夹结构扁平化,以便写入单个键,如(1_2_3_.)但这并没有带来任何改善。
注意:这些测试是用Hadoop FileSystem (BucketingSink)在Flink 1.8上完成的,它使用hadoop库2.6.x (因为我们将ClouderaCDH5.x用于保存点)写入S3,所以我们不能切换到StreamingFileSink。
回答 1
Stack Overflow用户
发布于 2020-02-07 10:35:00
仅这一项就需要4到5秒左右的时间,总共需要6秒来打开文件。来自已检测的调用的日志:
2020-02-07 08:51:05,825 INFO BucketingSink - openNewPartFile FS verification
2020-02-07 08:51:09,906 INFO BucketingSink - openNewPartFile FS verification - done
2020-02-07 08:51:11,181 INFO BucketingSink - openNewPartFile FS - completed partPath = s3a://....这与60秒无活动翻转的水桶池的默认设置一起意味着,当我们创建完最后一个桶时,一个槽上有10个以上的并行桶,第一个桶就过时了,因此需要旋转以产生阻塞情况。
我们通过替换BucketingSink.java和删除上面提到的FS检查来解决这个问题:
LOG.debug("Opening new part file FS verification");
if (!fs.exists(bucketPath)) {
try {
if (fs.mkdirs(bucketPath)) {
LOG.debug("Created new bucket directory: {}", bucketPath);
}
}
catch (IOException e) {
throw new RuntimeException("Could not create new bucket path.", e);
}
}
LOG.debug("Opening new part file FS verification - done");正如我们所看到的,没有它的接收器工作正常,现在打开文件需要1.2秒。
此外,我们将默认的非活动阈值设置为5分钟。通过这种更改,我们可以轻松地处理每个时隙200多个桶(一旦作业速度加快,就会在所有插槽上摄入,因此延迟了不活动的超时)
https://stackoverflow.com/questions/60111692
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号