
刮除CrawlSpider: URL深度
刮除CrawlSpider: URL深度
提问于 2020-02-21 10:30:37
我正在尝试实现与ScreamingFrog相同的功能--测量url深度。为此,我访问response.meta的深度参数,就像这样:response.meta.get('depth', 0),但是我得到的结果与ScreamingFrog的结果有很大不同。因此,我想通过保存CrawlSpider通过的所有页面来调试发生这种情况的原因,以便进入当前页面。
我现在的蜘蛛是这样的:
class FrSpider(scrapy.spiders.CrawlSpider):
"""Designed to crawl french version of dior.com"""
name = 'Fr'
allowed_domains = [website]
denyList = []
start_urls = ['https://www.%s/' % website]
rules = (Rule(LinkExtractor(deny=denyList), follow=True, callback='processLink'),)
def processLink(self, response):
link = response.url
depth = response.meta.get('depth', 0)
print('%s: depth is %s' % (link, depth))在这里,比较爬行统计(同一网站,限制在第一至500页)之间的爬虫和尖叫青蛙:
Depth(Clicks from Start Url) Number of Urls % of Total
1 62 12.4
2 72 14.4
3 97 19.4
4 49 9.8
5 40 8.0
6 28 5.6
7 46 9.2
8 50 10.0
9 56 11.2
---------------------------- -------------- ----------vs

正如你所看到的,它有很大的不同,通过将前500页的爬行扩展到完整的网站,两种方法之间存在着巨大的差异。
我想知道是否有人能指出我正在做的错误,或者帮助我提出如何存储爬虫通过的所有页面的建议,以达到当前的页面。可视化将如下所示:
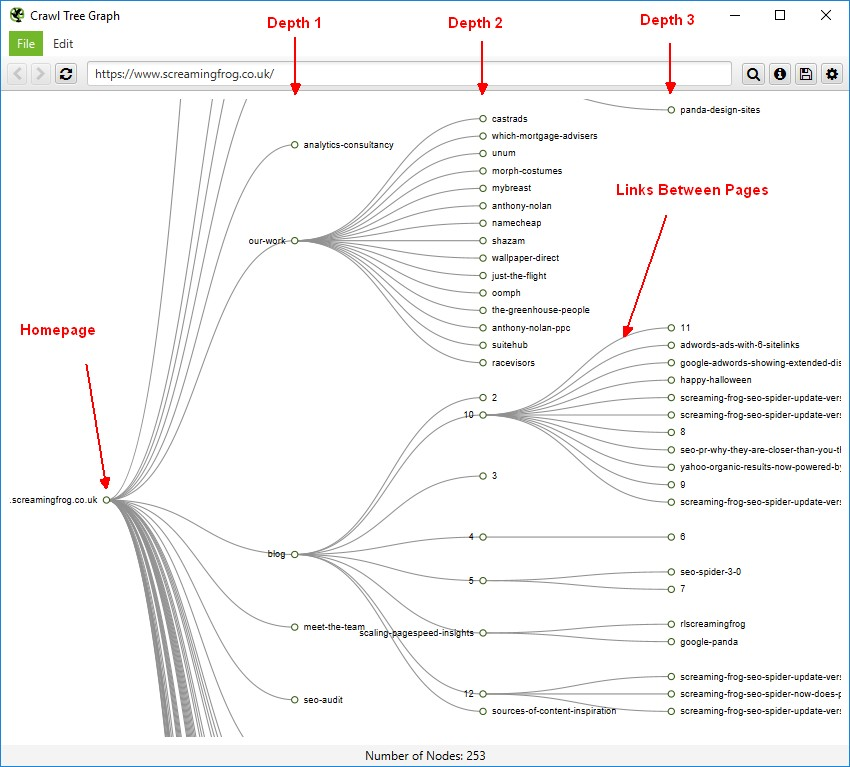
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-02-21 15:33:30
事实证明,问题是在刮刮的默认爬行顺序。通过将它从DFO改为BFO,我得到了预期的统计数据。
Stack Overflow用户
发布于 2020-02-21 11:30:59
您可以尝试DEPTH_STATS_VERBOSE (在设置中),然后检查两种结果是否相等。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60336718
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号