
你如何在Python中建立超时的模型?
我正在寻找一种数据类型来帮助我在流体时间上建模资源可用性。
- 我们从9到6开放,可以处理5个并行作业。在我想象中的编程领域,我刚刚初始化了一个值为3的对象。
- 我们在账面上有约会,每一个都有开始和结束时间。
- ,我需要给出其中的每一个都是白天的
- ,这给我留下了一个有可用性的图表,但最终可以让我快速找到仍然可用的时间范围。
我从多个方面讨论了这个问题,但总是回到一个根本的问题,即不知道数据类型来对像整数这样简单的东西建模。
我可以将我的约会转换成时间序列事件(如约会到达意味着-1可用性,约会离开意味着+1),但我仍然不知道如何操作这些数据,这样我就可以提取出可用性大于零的时间段。
有人以注意力不足为理由投了一票,但我的目标似乎很奇怪,所以我会试着用图表来解释这个问题。我试图推断一段时间内,活跃工作的数量会低于给定的容量。
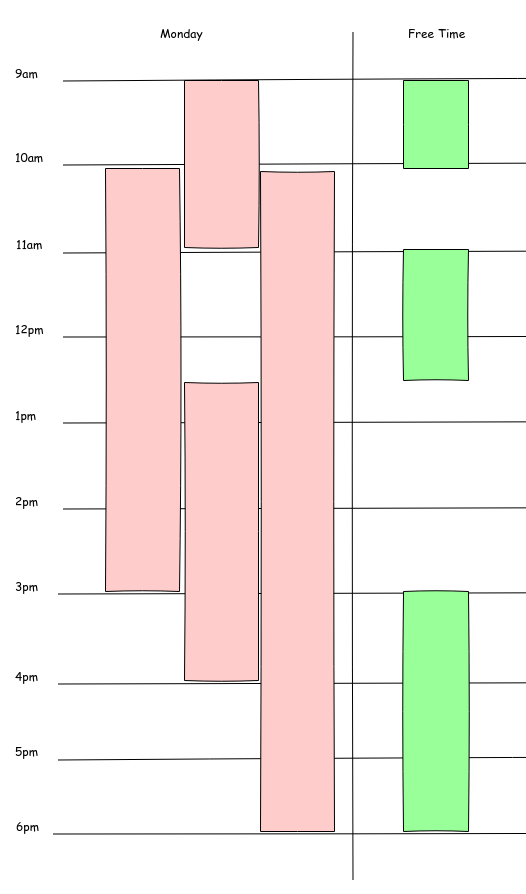
将已知的并行容量范围(如9-6之间的3)和具有可变开始/结束的作业列表转换为可用时间范围的列表。
回答 5
Stack Overflow用户
发布于 2020-03-05 13:43:05
我的方法是构建时间序列,但包含在此期间设置为可用性值的可用性对象。
availability:
[
{
"start": 09:00,
"end": 12:00,
"value": 4
},
{
"start": 12:00,
"end": 13:00,
"value": 3
}
]data: [
{
"start": 10:00,
"end": 10:30,
}
]在开始/结束时间上建立时间序列索引,并以值作为值。可用性的开始时间是+value,结束时间是-value。而对于一个活动,它将是-1或+1,正如你说的。
"09:00" 4
"10:00" -1
"10:30" 1
"12:00" -4
"12:00" 3
"13:00" -3然后按指数、和进行分组。
得到:
"09:00" 4
"10:00" 3
"10:30" 4
"12:00" 3
"13:00" 0大熊猫代码示例:
import numpy as np
import pandas as pd
data = [
{
"start": "10:00",
"end": "10:30",
}
]
breakpoints = [
{
"start": "00:00",
"end": "09:00",
"value": 0
},
{
"start": "09:00",
"end": "12:00",
"value": 4
},
{
"start": "12:00",
"end": "12:30",
"value": 4
},
{
"start": "12:30",
"end": "13:00",
"value": 3
},
{
"start": "13:00",
"end": "00:00",
"value": 0
}
]
df = pd.DataFrame(data, columns=['start', 'end'])
print(df.head(5))
starts = pd.DataFrame(data, columns=['start'])
starts["value"] = -1
starts = starts.set_index("start")
ends = pd.DataFrame(data, columns=['end'])
ends["value"] = 1
ends = ends.set_index("end")
breakpointsStarts = pd.DataFrame(breakpoints, columns=['start', 'value']).set_index("start")
breakpointsEnds = pd.DataFrame(breakpoints, columns=['end', 'value'])
breakpointsEnds["value"] = breakpointsEnds["value"].transform(lambda x: -x)
breakpointsEnds = breakpointsEnds.set_index("end")
countsDf = pd.concat([starts, ends, breakpointsEnds, breakpointsStarts]).sort_index()
countsDf = countsDf.groupby(countsDf.index).sum().cumsum()
print(countsDf)
# Periods that are available
df = countsDf
df["available"] = df["value"] > 0
# Indexes where the value of available changes
# Alternatively swap out available for the value.
time_changes = df["available"].diff()[df["available"].diff() != 0].index.values
newDf = pd.DataFrame(time_changes, columns= ["start"])
# Setting the end column to the value of the next start
newDf['end'] = newDf.transform(np.roll, shift=-1)
print(newDf)
# Join this back in to get the actual value of available
mergedDf = newDf.merge(df, left_on="start", right_index=True)
print(mergedDf)最后返回:
start end value available
0 00:00 09:00 0 False
1 09:00 13:00 4 True
2 13:00 00:00 0 FalseStack Overflow用户
发布于 2020-03-05 00:36:09
我和你对待约会的方式一样。将空闲时间建模为自己的约会。对于每个结束约会,检查是否有另一个正在进行,如果是,跳过这里。如果没有,请查找下一个开始约会(开始日期大于此日期的约会)。
在迭代了所有的约会之后,您应该有一个倒转的掩码。
Stack Overflow用户
发布于 2020-03-13 13:28:41
您可以使用(datetime, increment)元组来跟踪可用性的变化。作业开始事件具有increment = 1,作业结束事件具有increment = -1.然后,itertools.accumulate允许以作业开始和结束的时间计算累积可用性。下面是一个实现示例:
from datetime import time
import itertools as it
def compute_availability(jobs, opening_hours, capacity):
jobs = [((x, -1), (y, +1)) for x, y in jobs]
opens, closes = opening_hours
events = [[opens, capacity]] + sorted(t for job in jobs for t in job) + [(closes, 0)]
availability = list(it.accumulate(events,
lambda x, y: [y[0], x[1] + y[1]]))
for x, y in zip(availability, availability[1:]):
# If multiple events happen at the same time, only yield the last one.
if y[0] > x[0]:
yield x这将添加人工的(opens, capacity)和(closes, 0)事件来初始化计算。上面的示例只考虑一天,但通过创建分别共享第一个和最后一个作业日的opens和closes datetime对象,可以轻松地将其扩展到多天。
示例
下面是OP的示例日程的输出:
from pprint import pprint
jobs = [(time(10), time(15)),
(time(9), time(11)),
(time(12, 30), time(16)),
(time(10), time(18))]
availability = list(compute_availability(
jobs, opening_hours=(time(9), time(18)), capacity=3
))
pprint(availability)其中的指纹:
[[datetime.time(9, 0), 2],
[datetime.time(10, 0), 0],
[datetime.time(11, 0), 1],
[datetime.time(12, 30), 0],
[datetime.time(15, 0), 1],
[datetime.time(16, 0), 2]]第一个元素指示可用性何时变化,第二个元素表示由该更改产生的可用性。例如,在上午9时提交一个作业,导致可用性从3降到2,然后在上午10点提交两个作业,而第一个作业仍在运行(因此可用性下降到0)。
增加新工作
现在我们已经计算了初始可用性,随着新作业的增加,一个重要的方面就是更新它。在这里,最好不要从完整的作业列表中重新计算可用性,因为如果跟踪许多作业,这可能会花费很大的代价。因为availability已经排序了,所以我们可以使用bisect模块来确定O(log(N))中相关的更新范围。然后需要执行许多步骤。假设作业被调度为[x, y],其中x、y是两个datetime对象。
event)).
- Decrease
- 检查
[x, y]间隔中的可用性是否大于零(包括位于x左侧的事件)(即以前的[x, y]:[x, y]中所有事件的可用性为1。 - ,如果
x不在我们需要添加的事件列表中,则需要检查是否可以将x事件与其左边的事件合并。H 228H 129如果y不在我们需要添加的事件列表中。H 231G 232
以下是相关代码:
import bisect
def add_job(availability, job, *, weight=1):
"""weight: how many lanes the job requires"""
job = list(job)
start = bisect.bisect(availability, job[:1])
# Emulate a `bisect_right` which doens't work directly since
# we're comparing lists of different length.
if start < len(availability):
start += (job[0] == availability[start][0])
stop = bisect.bisect(availability, job[1:])
if any(slot[1] < weight for slot in availability[start-1:stop]):
raise ValueError('The requested time slot is not available')
for slot in availability[start:stop]:
slot[1] -= weight
if job[0] > availability[start-1][0]:
previous_availability = availability[start-1][1]
availability.insert(start, [job[0], previous_availability - weight])
stop += 1
else:
availability[start-1][1] -= weight
if start >= 2 and availability[start-1][1] == availability[start-2][1]:
del availability[start-1]
stop -= 1
if stop == len(availability) or job[1] < availability[stop][0]:
previous_availability = availability[stop-1][1]
availability.insert(stop, [job[1], previous_availability + weight])例程
我们可以通过在OP的示例计划中添加一些作业来测试它:
for job in [[time(15), time(17)],
[time(11, 30), time(12)],
[time(13), time(14)]]: # this one should raise since availability is zero
print(f'\nAdding {job = }')
add_job(availability, job)
pprint(availability)其中产出:
Adding job = [datetime.time(15, 0), datetime.time(17, 0)]
[[datetime.time(9, 0), 2],
[datetime.time(10, 0), 0],
[datetime.time(11, 0), 1],
[datetime.time(12, 30), 0],
[datetime.time(16, 0), 1],
[datetime.time(17, 0), 2]]
Adding job = [datetime.time(11, 30), datetime.time(12, 0)]
[[datetime.time(9, 0), 2],
[datetime.time(10, 0), 0],
[datetime.time(11, 0), 1],
[datetime.time(11, 30), 0],
[datetime.time(12, 0), 1],
[datetime.time(12, 30), 0],
[datetime.time(16, 0), 1],
[datetime.time(17, 0), 2]]
Adding job = [datetime.time(13, 0), datetime.time(14, 0)]
Traceback (most recent call last):
[...]
ValueError: The requested time slot is not available阻塞夜间时间
我们还可以使用此接口在服务不可用时(例如,从下午6点到次日上午9点)阻塞所有车道。只需在此时间跨度内使用weight=capacity提交一个作业:
add_job(availability,
[datetime(2020, 3, 14, 18), datetime(2020, 3, 15, 9)]
weight=3)从头开始构建完整的时间表
我们还可以使用add_job从头构建完整的计划:
availability = availability = list(compute_availability(
[], opening_hours=(time(9), time(18)), capacity=3
))
print('Initial availability')
pprint(availability)
for job in jobs:
print(f'\nAdding {job = }')
add_job(availability, job)
pprint(availability)其中产出:
Initial availability
[[datetime.time(9, 0), 3]]
Adding job = (datetime.time(10, 0), datetime.time(15, 0))
[[datetime.time(9, 0), 3],
[datetime.time(10, 0), 2],
[datetime.time(15, 0), 3]]
Adding job = (datetime.time(9, 0), datetime.time(11, 0))
[[datetime.time(9, 0), 2],
[datetime.time(10, 0), 1],
[datetime.time(11, 0), 2],
[datetime.time(15, 0), 3]]
Adding job = (datetime.time(12, 30), datetime.time(16, 0))
[[datetime.time(9, 0), 2],
[datetime.time(10, 0), 1],
[datetime.time(11, 0), 2],
[datetime.time(12, 30), 1],
[datetime.time(15, 0), 2],
[datetime.time(16, 0), 3]]
Adding job = (datetime.time(10, 0), datetime.time(18, 0))
[[datetime.time(9, 0), 2],
[datetime.time(10, 0), 0],
[datetime.time(11, 0), 1],
[datetime.time(12, 30), 0],
[datetime.time(15, 0), 1],
[datetime.time(16, 0), 2],
[datetime.time(18, 0), 3]]https://stackoverflow.com/questions/60536592
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号