
当作业完成时,在K8s作业(容器)中指定的内存请求/限制会发生什么?
我有多环境的k8s集群(EKS),我正在尝试为ResourceQuotas设置精确的值。
我注意到的一件有趣的事情是,当任务成功和有效地释放它正在使用的cpu/内存资源时,对cpu/内存保持的指定请求/限制“占用”了k8s集群中的。
因为我预计会有很多任务在环境上执行,这给我带来了一个问题。当然,我已经为成功执行的作业添加了对运行清理任务的支持,但这只是解决方案的一部分。
我知道TTL在k8s:https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#ttl-mechanism-for-finished-jobs上的特性,它仍然处于alpha状态,因此在EKS k8s集群中不可用。
我希望在特定的pod (容器/s)上指定的请求/限制也会被“释放”,但是当查看Grafana上的k8s度量时,我发现这不是真的。
这是一个示例(绿行标记当前资源使用情况,黄色标记资源请求,蓝色标记资源限制):
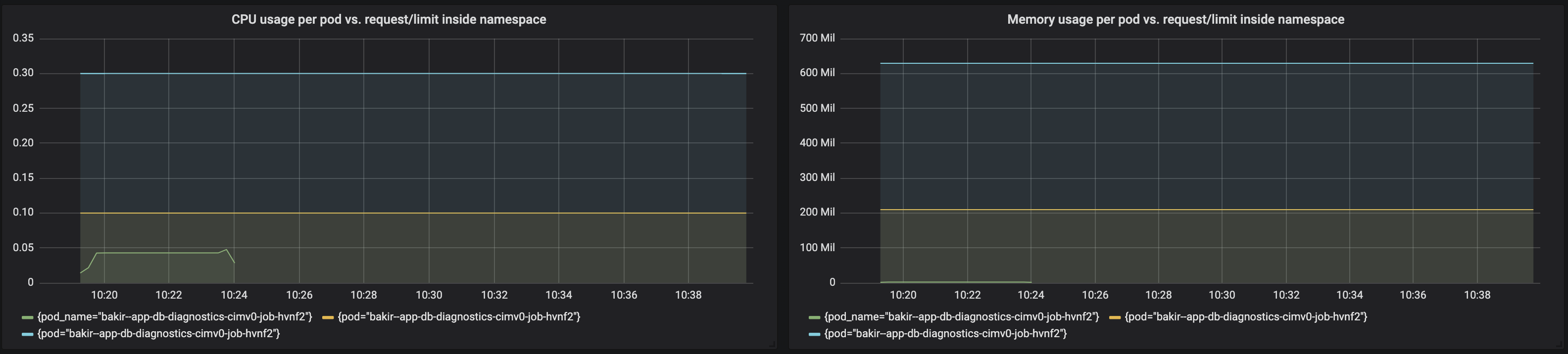
我的问题是:
是的,是的,在作业( behaviour?
- If )执行完成后,请求/限制没有发布的技术原因是什么?
回答 2
Stack Overflow用户
发布于 2020-03-07 20:44:01
我已经对我的环境进行了“负载”测试,以测试在已完成的作业(pod)上分配的请求/限制是否确实会对我设置的ResourceQuota产生影响。
这就是我的ResourceQuota的样子:
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-quota
spec:
hard:
requests.cpu: "1"
requests.memory: 2Gi
limits.cpu: "2"
limits.memory: 3Gi这是对每个k8s作业上存在的cpu/内存的请求/限制(准确地说,对于在Pod中运行的容器,由job派生出来):
resources:
limits:
cpu: 250m
memory: 250Mi
requests:
cpu: 100m
memory: 100Mi测试结果:
当前运行的作业数:66
- Expected和CPU请求(如果来自问题的假设是正确的),~= 6.6m
- Expected请求和(如果来自问题的假设是正确的) ~= 6.6Mi
- Expected的CPU限制和(如果来自问题的假设是正确的) ~= 16.5
- Expected的内存限制和(如果来自问题的假设是正确的) ~= 16.5
我创建了Grafana图表,如下所示:
CPU使用/请求/对一个命名空间中作业的限制
sum(rate(container_cpu_usage_seconds_total{namespace="${namespace}", container="myjob"}[5m]))
sum(kube_pod_container_resource_requests_cpu_cores{namespace="${namespace}", container="myjob"})
sum(kube_pod_container_resource_limits_cpu_cores{namespace="${namespace}", container="myjob"})内存使用/请求/对一个命名空间中作业的限制
sum(rate(container_memory_usage_bytes{namespace="${namespace}", container="myjob"}[5m]))
sum(kube_pod_container_resource_requests_memory_bytes{namespace="${namespace}", container="myjob"})
sum(kube_pod_container_resource_limits_memory_bytes{namespace="${namespace}", container="myjob"})这就是图表的样子:
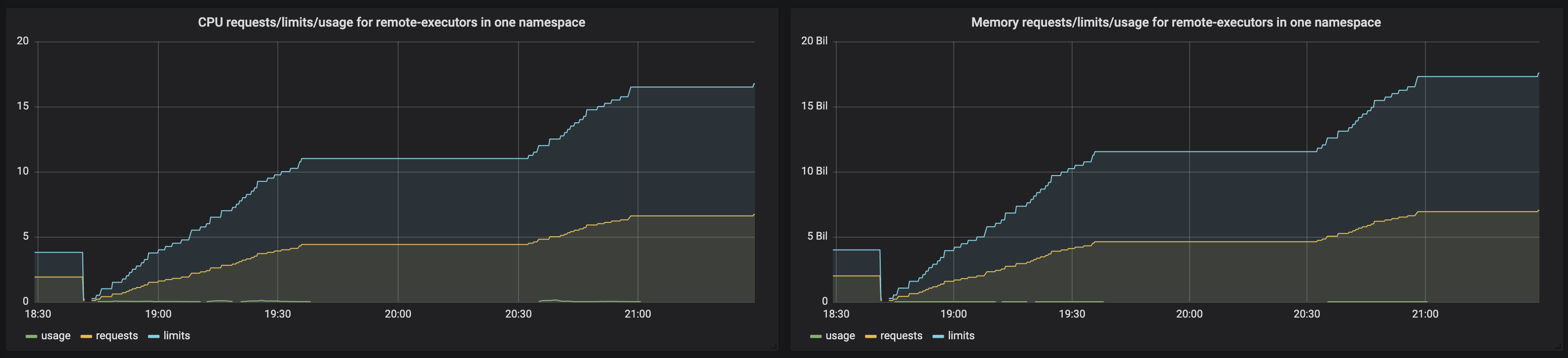
根据这个图表,请求/限制会累积起来,并且远远超过ResourceQuota阈值。然而,我仍然能够在没有问题的情况下完成新的工作。
此时,我开始怀疑指标显示的是什么,并选择检查度量的其他部分。具体来说,我使用了以下一组指标:
CPU:
sum (rate(container_cpu_usage_seconds_total{namespace="$namespace"}[1m]))
kube_resourcequota{namespace="$namespace", resource="limits.cpu", type="hard"}
kube_resourcequota{namespace="$namespace", resource="requests.cpu", type="hard"}
kube_resourcequota{namespace="$namespace", resource="limits.cpu", type="used"}
kube_resourcequota{namespace="$namespace", resource="requests.cpu", type="used"}内存:
sum (container_memory_usage_bytes{image!="",name=~"^k8s_.*", namespace="$namespace"})
kube_resourcequota{namespace="$namespace", resource="limits.memory", type="hard"}
kube_resourcequota{namespace="$namespace", resource="requests.memory", type="hard"}
kube_resourcequota{namespace="$namespace", resource="limits.memory", type="used"}
kube_resourcequota{namespace="$namespace", resource="requests.memory", type="used"}这就是图表的样子:
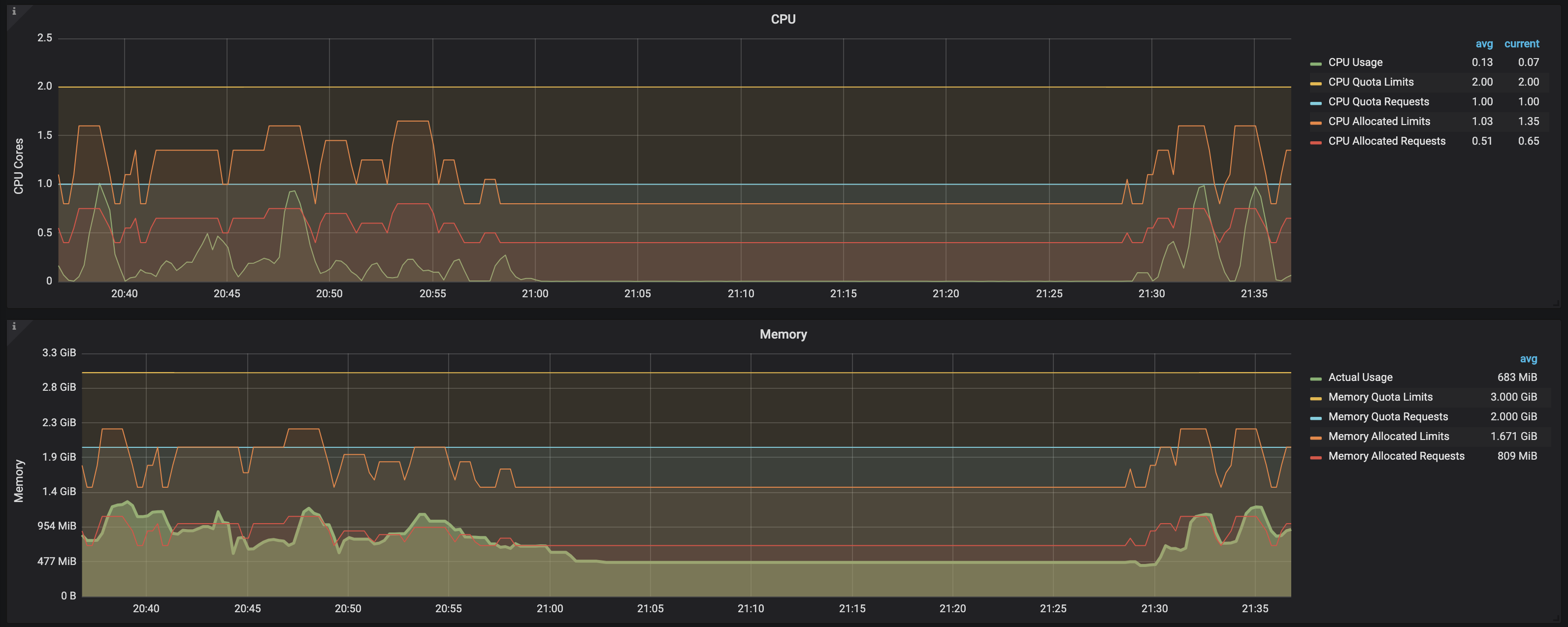
结论:
从这个屏幕截图中可以清楚地看到,一旦负载测试完成,作业进入完全状态,即使(准备好: 0/1和状态:完成)仍然存在,cpu/内存请求/限制也会被释放,不再表示需要计算到ResourceQuota阈值的约束。通过观察图表上的下列数据可以看出这一点:
CPU allocated requests
CPU allocated limits
Memory allocated requests
Memory allocated limits所有这些在系统负载发生和新作业创建时都会增加,但在作业完成后立即回到以前的状态(即使它们没有从环境中删除)。
换句话说,只有在作业(及其相应的)处于运行状态时,才会将两个cpu/内存的资源使用/限制/请求输入帐户。
Stack Overflow用户
发布于 2020-03-07 09:06:23
如果您做了kubectl get pod,您可以看到由作业创建的荚仍然存在于列表中,例如:
NAME READY STATUS RESTARTS AGE
cert-generator-11b35c51b71ea3086396a780dbf20b5cd695b25d-wvb7t 0/1 Completed 0 57d因此,任何资源要求/限制仍然由吊舱使用。要释放资源,您可以手动删除吊舱。它将在下一次工作运行时重新创建。
您还可以通过在作业上使用.spec.ttlSecondsAfterFinished将作业(因此也是pod)配置为在成功和/或失败时自动从历史记录中删除。但你可能会迷失方向,无法知道这份工作是否成功。
或者,如果您的作业实际上是由CronJob创建的,那么您可以将作业(因此是pod)配置为在CronJob上自动删除的.spec.successfulJobsHistoryLimit and .spec.failedJobsHistoryLimit。
https://stackoverflow.com/questions/60565324
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号