
不同分辨率的两个时间序列的最大差
不同分辨率的两个时间序列的最大差
提问于 2020-03-11 22:15:05
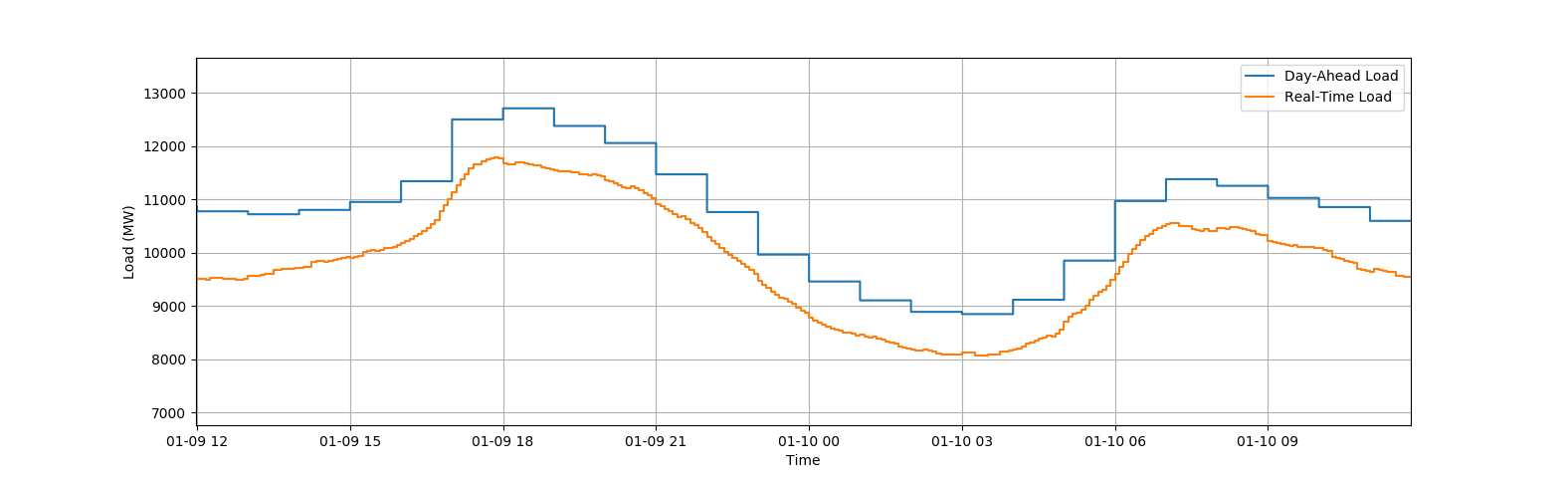
我有两个时间序列数据,给出一小时分辨率和五分钟分辨率的电力需求。我试图找出这两个时间序列之间的最大差异。因此,一小时分辨率数据有8760行(一年每小时),5分钟分辨率数据有104,722行(5分钟为一年)。
我只能想出一种方法,将每小时的数据扩展为5分钟的分辨率,重复12次每小时的数据,并找到两个数据集的最大差值。
如果这项技术是可行的,那么是否有一种简单的方法可以通过重复12次小时数据将我的每小时数据转换成5分钟的分辨率?
供你参考,我贴出了一天的这份数据图。
P.S>我正在使用Python来完成这个任务
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-03-11 22:27:48
Stack Overflow用户
发布于 2020-03-11 22:36:36
我强烈建议不要将每小时的数据转换为5分钟的数据。如果这两种情况下的数据都是指这些时间范围的平均负载,那么如果将每隔5分钟的时间间隔分组到每小时的数据集中,您将看到更准确的数据。您将获得更多的粒度,但粒度并不是基于准确的数据,因此您实际上并没有从中获得更多的价值。如果您将五分钟的块聚合成每小时的块,并以这种方式对系列进行比较,那么您可以对您的结果的可信度更有信心。
为了将它们组合在一起以获得结果,您可以像下面这样定义一个函数,并使用如下的apply方法:
def to_hour(date):
date = date.strftime("%Y-%m-%d %H:00:00")
date = dt.strptime(date, "%Y-%m-%d %H:%M:%S")
return date
df['Aggregated_Datetime'] = df['Original_Datetime'].apply(lambda x: to_hour(x))
df.groupby('Aggregated_Datetime').agg('Real-Time Lo页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60645104
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号