
我能把蒙特卡罗策略梯度算法和其他策略梯度算法结合起来吗?
我知道蒙特卡罗强化策略梯度算法在计算每个步骤的贴现累积未来报酬时,其计算报酬值的方法是不同的。
下面是计算每一时间步骤的贴现累积未来报酬的代码的宁静。
G = np.zeros_like(self.reward_memory, dtype=np.float64)
for t in range(len(self.reward_memory)):
G_sum = 0
discount = 1
for k in range(t, len(self.reward_memory)):
G_sum += self.reward_memory[k] * discount
discount *= self.gamma
G[t] = G_sum另一个提高准确性的例子是在被称为“奖励去”的行动之后计算奖励。另一个例子是添加熵加值。
是否有可能在蒙特卡洛方法中增加熵奖金和奖金,或者两者之一。
另外,在蒙特卡罗中,奖励计算后的另一步是将值归一化。
“在实践中,使这些问题正常化也是很重要的。例如,假设在上面的100次Pong游戏展示中,我们计算了所有20,000项动作的折扣累积奖励。一个好主意是“标准化”这些回报(例如,减去均值,除以标准差),然后再将它们插入后台。这样,我们总是鼓励和劝阻大约一半已执行的行动。在数学上,您也可以将这些技巧解释为控制策略梯度估计器的方差的一种方法“。
如果两种或其中一种增加了熵奖励或去修正的奖励,这会影响准确性吗?
这是来自于研究PDF https://arxiv.org/pdf/1506.02438.pdf
我正在学习策略梯度算法,我想知道如何改进这些算法。如果你能帮我一把,我会非常感激的。
编辑:
我还想补充一下,是否也可以添加advantage函数。
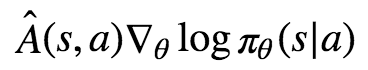
A(s,a)是优势函数;假设我们同时增加奖励和熵加成,是否可以将其添加到Monte方法中?
回答 1
Stack Overflow用户
发布于 2020-03-16 21:59:26
你在这上面混了些东西。
蒙特卡罗方法是计算状态-动作对的回报的一种方法:作为当前策略π之后的所有未来奖励的折扣和。(还值得注意的是,增强不是一种特别好的RL算法,而且相对于TD(λ),对收益的蒙特卡罗估计有很大的差异。)
另一方面,熵加成和优势函数是损失的一部分(用来训练您的演员的函数),因此与返回计算无关。
我建议您阅读强化学习手册以更深入地了解您正在做的事情。
https://stackoverflow.com/questions/60689453
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号