
cuda驱动程序指令执行命令
下面的代码
asm volatile("mov.u64 %0, %%clock64;" : "=l"(start) :: "memory");
asm volatile("ld.global.ca.u64 data, [%0];"::"l"(po):"memory");
asm volatile("mov.u64 %0, %%clock64;" : "=l"(stop) :: "memory");在SASS代码中如下所示
/*0420*/ CS2R R2, SR_CLOCKLO ; /* 0x0000000000027805 */
/*0430*/ LDG.E.64.STRONG.CTA R4, [R4] ; /* 0x0000000004047381 */
/*0440*/ CS2R R6, SR_CLOCKLO ; /* 我希望确保调度程序在CS2R、LDG指令和(而不是)之后发出第二个,这是由于任何优化,比如无序执行。我怎么能确定呢?
更新:
根据Greg的建议,我添加了一个依赖指令,它看起来像
asm volatile("mov.u64 %0, %%clock64;" : "=l"(start) :: "memory");
asm volatile("ld.global.ca.u64 data, [%0];"::"l"(po):"memory");
asm volatile("add.u64 %0, data, %0;":"+l"(sink)::"memory");
asm volatile("mov.u64 %0, %%clock64;" : "=l"(stop) :: "memory");其中定义了uint64_t sink = 0;。不过,我在CS2R指令之间只看到一个LDG。由于我又在阅读data,所以我希望也能看到一份IADD指令。我想我写的asm添加指令不正确,但不知道更多。
回答 1
Stack Overflow用户
发布于 2020-03-20 15:43:40
NVIDIA GPU的计算能力1.0 - 7.x将按顺序发出翘曲指令。特殊用途寄存器、时钟和clock64可以通过在指令序列前后读取寄存器来对代码的时间部分使用。
这对于估计单个翘曲的指令序列所需的周期数是很有用的。
案例1:指令发布延迟
clock64读取是在一系列指令前后插入的。在下面的例子中,clock64读取一个全局负载。这种样式估计全局load指令的指令问题延迟。翘曲可以在开始和结束之间停止CS2R,增加持续时间。延迟原因可以包括以下几个方面:- not_selected -翘曲调度器选择了一个更高优先级的翘曲- no_instruction - LDG在一个新的指令缓存线上,并且在获取缓存线之前,翘曲停止了--由于负载存储单元的指令队列已满,无法发出mio_throttle - LDG指令。无法发出lg_throttle - LDG指令,因为Load单元的指令队列已达到本地/全局水印。
为了提高准确性,建议测量指令序列,而不是单个指令。
PTX
asm volatile("mov.u64 %0, %%clock64;" : "=l"(start) :: "memory");
asm volatile("ld.global.ca.u32 data, [%0];"::"l"(po):"memory");
asm volatile("mov.u64 %0, %%clock64;" : "=l"(stop) :: "memory");SASS (SM_70)
/*0420*/ CS2R R2, SR_CLOCKLO ;
/*0430*/ LDG.E.64.STRONG.CTA R4, [R4] ;
/*0440*/ CS2R R6, SR_CLOCKLO ;案例2:指令执行延迟
在指令序列之前插入clock64读取。在指令序列之后插入一组保证完成指令序列和clock64读取的指令。在下面的情况下,将在最后一次读取之前插入一个整数添加,该数据依赖于来自全局加载的值。该技术可用于估计全局负载的执行时间。
PTX
asm volatile("mov.u64 %0, %%clock64;" : "=l"(start) :: "memory");
asm volatile("ld.global.ca.u32 data, [%0];"::"l"(po):"memory");
asm volatile("add.u32 %0, data, %0;":"+l"(sink)::"memory");
asm volatile("mov.u64 %0, %%clock64;" : "=l"(stop) :: "memory");SASS (SM_70)
/*0420*/ CS2R R2, SR_CLOCKLO ;
/*0430*/ LDG.E.64.STRONG.CTA R4, [R4] ;
/*0440*/ IADD R4, R4, 1 ;
/*0450*/ CS2R R6, SR_CLOCKLO ;图
案例1和案例2的测量周期显示在波形图中。该图显示了CS2R和IADD指令需要4个周期来执行。CS2R指令读取第三个周期的时间。
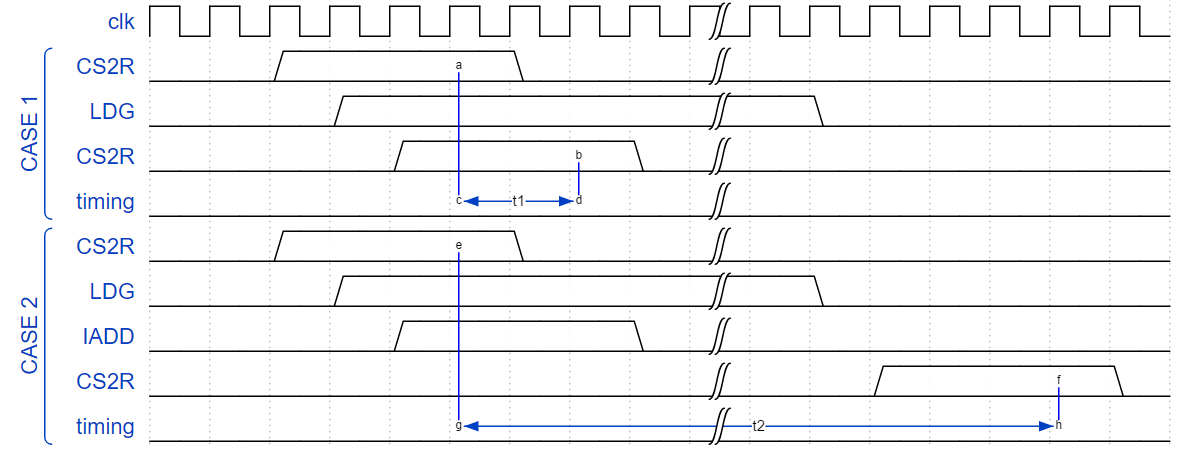
对于情况1,测量的时间可以小到2个周期。对于情况1,测量的时间包括来自全局内存的负载。如果加载在L1缓存中,那么时间是在20-50个周期内,否则时间可能大于200个周期。
警告
在实践中,这种类型的指令问题或指令执行延迟很难实现。这些技术可以用来编写微基准或大量的代码序列.在微基准测试的情况下,理解并潜在地隔离其他因素是至关重要的,例如翘曲调度、指令缓存丢失、常量缓存丢失等。
编译器不把读时钟/时钟64当作指令栅栏。编译器可以自由地将读取移动到意外位置。建议始终检查生成的SASS代码。
计算能力6.0及更高版本支持指令级抢占。指令级抢占将导致意外的结果。
https://stackoverflow.com/questions/60739210
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号