
C# WebClient - DownloadString错误编码
我试图从亚马逊下载一个html文档,但出于某种原因,我得到了一个糟糕的编码字符串,如"��K��g��g�e“。
下面是我尝试过的代码:
using (var webClient = new System.Net.WebClient())
{
var url = "https://www.amazon.com/dp/B07H256MBK/";
webClient.Encoding = Encoding.UTF8;
var result = webClient.DownloadString(url);
}在使用HttpClient时也会发生相同的情况:
var url = "https://www.amazon.com/dp/B07H256MBK/";
var httpclient = new HttpClient();
var html = await httpclient.GetStringAsync(url);我还试着阅读拜特斯的结果,然后将其转换回UTF-8,但我仍然得到了相同的结果。还请注意,这种情况并不总是发生。例如,昨天我运行了2个小时的代码,得到了一个正确编码的HTML文档。然而,今天我总是得到一个糟糕的编码结果。它每隔一天发生一次,所以不是一次。
==================================================================
然而,当我使用HtmlAgilitypack的包装器时,它就像预期的那样工作,每次都是()
var url = "https://www.amazon.com/dp/B07H256MBK/";
HtmlWeb htmlWeb = new HtmlWeb();
HtmlDocument doc = htmlWeb.Load(url);是什么原因导致WebClient和HttpClient得到错误的编码字符串,即使我显式地定义了正确的编码?默认情况下,HtmlAgilityPack的包装器是如何工作的?
谢谢你的帮助!
回答 1
Stack Overflow用户
发布于 2020-03-19 09:16:46
我启动了Firefox的web开发工具,请求了该页面,并查看了响应头:
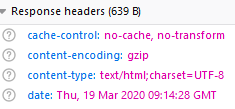
看到那个content-encoding: gzip了吗?这意味着响应是gzip编码的。
结果是,即使您不发送Accept-Encoding: gzip头(用另一个工具验证),亚马逊也会给您一个用gzip压缩的响应。这有点淘气,但并不少见,而且很容易解决。
这根本不是字符编码的问题。HttpClient擅长于从Content-Type头中找出正确的编码。
您可以通过以下方式告诉HttpClient对un的响应:
HttpClientHandler handler = new HttpClientHandler()
{
AutomaticDecompression = DecompressionMethods.GZip,
};
using (var client = new HttpClient(handler))
{
// your code
}如果您使用的是4.1.0至4.3.2版本的NuGet包,这将是自动设置的,否则您需要自己进行设置。
您也可以对WebClient,but it's harder做同样的事情。
https://stackoverflow.com/questions/60753996
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号