
在使用预训练模型的gensim中,working工作得很好,但是n_similarity不是。
在使用预训练模型的gensim中,working工作得很好,但是n_similarity不是。
提问于 2020-03-21 07:42:28
我用gensim的trained()函数用预先训练的模型计算了两句句子之间的距离。
现在,我希望它们之间有相似之处,并尝试使用n_similarity()函数,但是出现了键错误。
关键词错误:单词不在单词中
这显示了错误示例的截图。
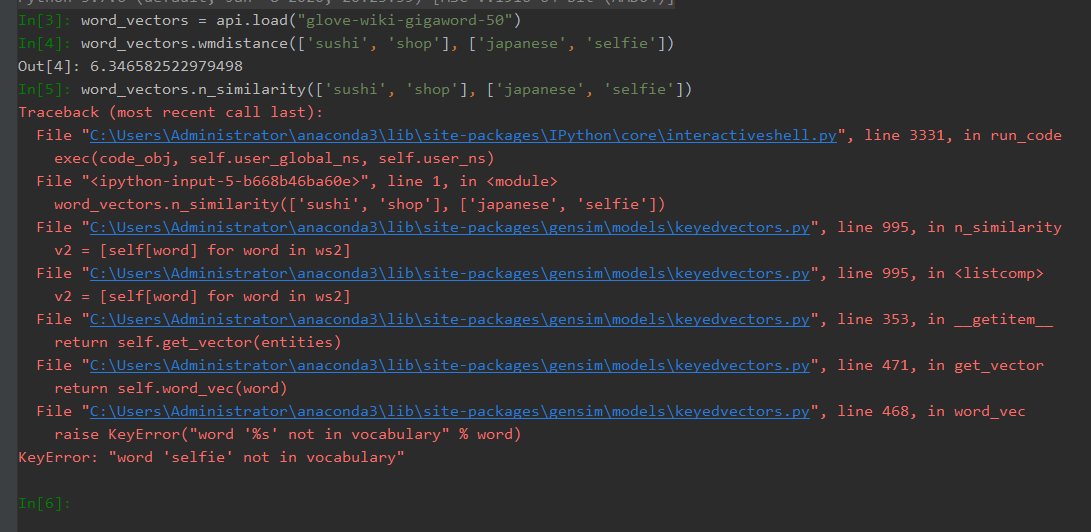
有人对此有想法吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-03-22 05:51:19
当你得到一个单词不在词汇表中的错误时,它意味着这个词不在那个模型中。
任何查找它的尝试都会生成一个KeyError,以使您知道您正在尝试获取一个不存在的字向量。
在将令牌列表传递给n_similarity()之前,您应该对它们进行筛选,以便只包含有效的单词。
当然,这意味着您无法获得关于单词'selfie'的有意义的结果。对于模型来说,这是未知的无稽之谈,就好像你想要单词'asruhfglaiwurfliuawiufsdfsdfs'一样。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60785538
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号