
Cox比例风险模型
我试图在4组数据上建立Cox比例风险模型。以下是数据:
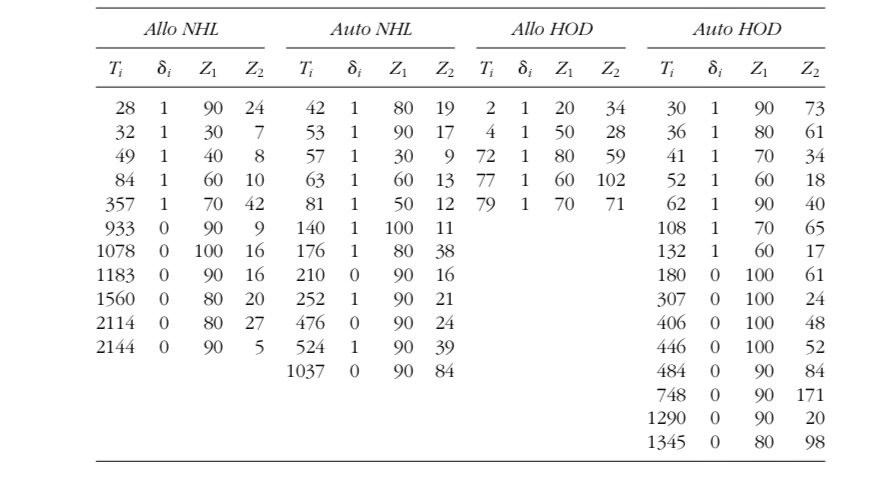
我正在使用以下代码:
time_Allo_NHL<- c(28,32,49,84,357,933,1078,1183,1560,2114,2144)
censor_Allo_NHL<- c(rep(1,5), rep(0,6))
time_Auto_NHL<- c(42,53,57,63,81,140,176,210,252,476,524,1037)
censor_Auto_NHL<- c(rep(1,7), rep(0,1), rep(1,1), rep(0,1), rep(1,1), rep(0,1))
time_Allo_HOD<- c(2,4,72,77,79)
censor_Allo_HOD<- c(rep(1,5))
time_Auto_HOD<- c(30,36,41,52,62,108,132,180,307,406,446,484,748,1290,1345)
censor_Auto_HOD<- c(rep(1,7), rep(0,8))
myData <- data.frame(time=c(time_Allo_NHL, time_Auto_NHL, time_Allo_HOD, time_Auto_HOD),
censor=c(censor_Allo_NHL, censor_Auto_NHL, censor_Allo_HOD, censor_Auto_HOD),
group= rep(1:4,), each= )
str(myData)问题是每一组都有不同数量的观察。我应该在代码中修改的内容:
myData <- data.frame(time=c(time_Allo_NHL, time_Auto_NHL, time_Allo_HOD, time_Auto_HOD),
censor=c(censor_Allo_NHL, censor_Auto_NHL, censor_Allo_HOD,
censor_Auto_HOD), group= rep(1:4,), each= )而不是编写each=#,这样我就可以正确地运行代码来完成Cox比例风险模型?
然后,我尝试使用以下代码运行Cox比例风险模型:
library(survival)
for(i in 1:43){
if (myData$group[i]==2)
myData$Z1[i]<-1
else myData$Z1[i]<-0
}
for(i in 1:43){
if (myData$group[i]==3)
myData$Z2[i]<-1
else myData$Z2[i]<-0
}
for(i in 1:43){
if (myData$group[i]==4)
myData$Z3[i]<-1
else myData$Z3[i]<-0
}
myData
Coxfit<-coxph(Surv(time,censor)~Z1+Z2+Z3, data = myData)
summary(Coxfit) 这就是我的全部。根本没有价值!!
接下来,我想测试移植类型和疾病类型之间的交互作用,使用主要影响和交互条件。
我将要使用的代码:
n<-length(myData$time)
n
for (i in 1:n){
if (myData$(here?)[i]==2)
myData$W1[i] <-1
else myData$W1[i]<-0
}
for (i in 1:n){
if (myData$(here?)[i]==2)
myData$W2[i] <-1
else myData$W2[i]<-0
}
myData
Coxfit.W<-coxph(Surv(time,censor)~W1+W2+W1*W2, data = myData)
summary(Coxfit.W)我不知道在这里应该从上面的代码写什么(myData$(here?)。
回答 1
Stack Overflow用户
发布于 2020-03-29 22:35:36
这看起来像是俄亥俄州立大学的骨髓移植研究。
正如您所提到的,每组有不同数量的观察。最后,我会考虑将每个子组中的行绑定到一起。
首先,为每个组创建一个数据框架。我会添加一个列,说明它们属于哪个组。因此,例如,在df_Allo_NHL中,所有的观测都有Allo NHL for group
df_Allo_NHL <- data.frame(group = "Allo NHL",
time = c(28,32,49,84,357,933,1078,1183,1560,2114,2144),
censor = c(rep(1,5), rep(0,6)))或者只是添加到您已经拥有的两个向量中:
df_Allo_NHL <- data.frame(group = "Allo NHL", time = time_Allo_NHL, censor = censor_Allo_NHL)然后,一旦您有了您的4个数据帧,您可以组合它们。一种方法是使用Reduce并将所有数据帧放入列表中。最终的结果应该已经准备好用于cox比例风险分析,在很长的形式上,您将有可用的group包括在内。(编辑:从表中为模型添加的Z1和Z2。)
time_Allo_NHL<- c(28,32,49,84,357,933,1078,1183,1560,2114,2144)
censor_Allo_NHL<- c(rep(1,5), rep(0,6))
df_Allo_NHL <- data.frame(group = "Allo NHL",
time = time_Allo_NHL,
censor = censor_Allo_NHL,
Z1 = c(90,30,40,60,70,90,100,90,80,80,90),
Z2 = c(24,7,8,10,42,9,16,16,20,27,5))
time_Auto_NHL<- c(42,53,57,63,81,140,176,210,252,476,524,1037)
censor_Auto_NHL<- c(rep(1,7), rep(0,1), rep(1,1), rep(0,1), rep(1,1), rep(0,1))
df_Auto_NHL <- data.frame(group = "Auto NHL",
time = time_Auto_NHL,
censor = censor_Auto_NHL,
Z1 = c(80,90,30,60,50,100,80,90,90,90,90,90),
Z2 = c(19,17,9,13,12,11,38,16,21,24,39,84))
time_Allo_HOD<- c(2,4,72,77,79)
censor_Allo_HOD<- c(rep(1,5))
df_Allo_HOD <- data.frame(group = "Allo HOD",
time = time_Allo_HOD,
censor = censor_Allo_HOD,
Z1 = c(20,50,80,60,70),
Z2 = c(34,28,59,102,71))
time_Auto_HOD<- c(30,36,41,52,62,108,132,180,307,406,446,484,748,1290,1345)
censor_Auto_HOD<- c(rep(1,7), rep(0,8))
df_Auto_HOD <- data.frame(group = "Auto HOD",
time = time_Auto_HOD,
censor = censor_Auto_HOD,
Z1 = c(90,80,70,60,90,70,60,100,100,100,100,90,90,90,80),
Z2 = c(73,61,34,18,40,65,17,61,24,48,52,84,171,20,98))
myData <- Reduce(rbind, list(df_Allo_NHL, df_Auto_NHL, df_Allo_HOD, df_Auto_HOD))编辑
如果您继续添加Z1 (Karnofsky评分)和Z2 (从诊断到移植的等待时间),您可以在下面这样做CPH生存模型。group已经是一个因素,在默认情况下,第一级Allo NHL应该是引用类别。
library(survival)
Coxfit<-coxph(Surv(time,censor)~group+Z1+Z2, data = myData)
summary(Coxfit) 输出
Call:
coxph(formula = Surv(time, censor) ~ group + Z1 + Z2, data = myData)
n= 43, number of events= 26
coef exp(coef) se(coef) z Pr(>|z|)
groupAuto NHL 0.77357 2.16748 0.58631 1.319 0.18704
groupAllo HOD 2.73673 15.43639 0.94081 2.909 0.00363 **
groupAuto HOD 1.06293 2.89485 0.63494 1.674 0.09412 .
Z1 -0.05052 0.95074 0.01222 -4.135 3.55e-05 ***
Z2 -0.01660 0.98354 0.01002 -1.656 0.09769 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
exp(coef) exp(-coef) lower .95 upper .95
groupAuto NHL 2.1675 0.46136 0.6869 6.8395
groupAllo HOD 15.4364 0.06478 2.4419 97.5818
groupAuto HOD 2.8948 0.34544 0.8340 10.0481
Z1 0.9507 1.05181 0.9282 0.9738
Z2 0.9835 1.01674 0.9644 1.0030
Concordance= 0.783 (se = 0.059 )
Likelihood ratio test= 32.48 on 5 df, p=5e-06
Wald test = 28.48 on 5 df, p=3e-05
Score (logrank) test = 39.45 on 5 df, p=2e-07数据
group time censor Z1 Z2
1 Allo NHL 28 1 90 24
2 Allo NHL 32 1 30 7
3 Allo NHL 49 1 40 8
4 Allo NHL 84 1 60 10
5 Allo NHL 357 1 70 42
6 Allo NHL 933 0 90 9
7 Allo NHL 1078 0 100 16
8 Allo NHL 1183 0 90 16
9 Allo NHL 1560 0 80 20
10 Allo NHL 2114 0 80 27
11 Allo NHL 2144 0 90 5
12 Auto NHL 42 1 80 19
13 Auto NHL 53 1 90 17
14 Auto NHL 57 1 30 9
15 Auto NHL 63 1 60 13
16 Auto NHL 81 1 50 12
17 Auto NHL 140 1 100 11
18 Auto NHL 176 1 80 38
19 Auto NHL 210 0 90 16
20 Auto NHL 252 1 90 21
21 Auto NHL 476 0 90 24
22 Auto NHL 524 1 90 39
23 Auto NHL 1037 0 90 84
24 Allo HOD 2 1 20 34
25 Allo HOD 4 1 50 28
26 Allo HOD 72 1 80 59
27 Allo HOD 77 1 60 102
28 Allo HOD 79 1 70 71
29 Auto HOD 30 1 90 73
30 Auto HOD 36 1 80 61
31 Auto HOD 41 1 70 34
32 Auto HOD 52 1 60 18
33 Auto HOD 62 1 90 40
34 Auto HOD 108 1 70 65
35 Auto HOD 132 1 60 17
36 Auto HOD 180 0 100 61
37 Auto HOD 307 0 100 24
38 Auto HOD 406 0 100 48
39 Auto HOD 446 0 100 52
40 Auto HOD 484 0 90 84
41 Auto HOD 748 0 90 171
42 Auto HOD 1290 0 90 20
43 Auto HOD 1345 0 80 98https://stackoverflow.com/questions/60919837
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号