
(特性工具)如何计算聚合特性原语?
(特性工具)如何计算聚合特性原语?
提问于 2020-04-16 09:29:59
即使我用非常简单的数据进行了测试,我也不知道如何计算聚合特性原语。我还查看了特性工具代码,但找不到聚合操作发生在哪里。
以下是示例代码:
from sklearn.utils import shuffle
periods = 5
end_date = "2012-04-13"
train_df = pd.DataFrame(
{
"store_id": [0]*periods + [1]*periods + [2]*periods + [3]*periods,
"region": ["A"]*periods+["B"]*periods*3,
"amount": shuffle(range(periods*4)),
"transacted_date": [
"2012-02-05", "2012-02-10", "2012-03-01", "2012-03-18", "2012-04-23",
]*4
}
)
train_df["transacted_date"] = pd.to_datetime(train_df["transacted_date"])
train_df.sort_values(["store_id", "transacted_date"], inplace=True)
def make_retail_cutoffs_amounts(data_df, amount_start_date, amount_end_date):
store_pool = data_df[data_df['transacted_date'] < amount_start_date]['store_id'].unique()
tmp = pd.DataFrame({'store_id': store_pool})
amounts = data_df[
(data_df['store_id'].isin(store_pool)) &
(amount_start_date <= data_df['transacted_date']) &
(data_df['transacted_date'] < amount_end_date)
].groupby('store_id')['amount'].sum().reset_index()
amounts = amounts.merge(tmp, on = 'store_id', how = 'right')
amounts['amount'] = amounts['amount'].fillna(0) # 0으로 채워지는 애는 3개월 다 수익이 없는 녀석!
amounts['cutoff_time'] = pd.to_datetime(amount_start_date)
amounts = amounts[['store_id', 'cutoff_time', 'amount']]
amounts = amounts.rename(columns={"amount":"1month_amount_from_cutoff_time"})
return amounts
amount_start_date = "2012-02-01"
amount_end_date = end_date
agg_month = 1
data_df_list = []
date_list = pd.date_range(amount_start_date, datetime.strptime(end_date, "%Y-%m-%d") + pd.DateOffset(months=1), freq="MS")
for amount_start_date, amount_end_date in zip(date_list[:-agg_month], date_list[agg_month:]):
data_df_list.append(
make_retail_cutoffs_amounts(
train_df, amount_start_date, amount_end_date
)
)
data_df = pd.concat(data_df_list)
data_df.sort_values(["store_id", "cutoff_time", ], inplace=True)
import featuretools as ft
es = ft.EntitySet(id="sale_set")
es = es.entity_from_dataframe(
"sales",
dataframe=train_df,
index="sale_id", make_index=True,
time_index='transacted_date',
)
es.normalize_entity(
new_entity_id="stores",
base_entity_id="sales",
index="store_id",
additional_variables=['region']
)
# When using a training window,
# it is necessary to calculate the last time indexes for the entity set. Adding
es.add_last_time_indexes()
features = ft.dfs(
entityset=es,
target_entity='stores',
cutoff_time=data_df,
verbose=1,
cutoff_time_in_index=True,
n_jobs=1,
max_depth=2,
agg_primitives=["sum",],
trans_primitives=["cum_max"],
training_window="1 month",
)dfs工作良好,但不能解释结果特性。
以下是特征的样本数据:
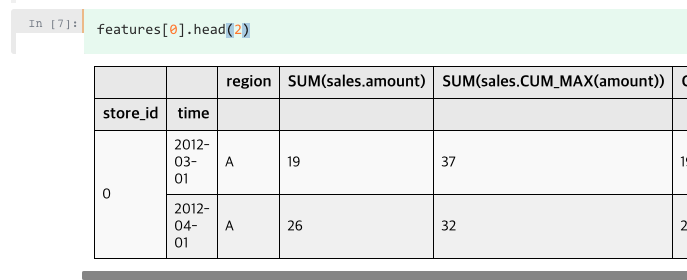
正如您在这里看到的,SUM(sales.amount)和SUM(sales.CUM_MAX(amount))的第一行分别为19,37。我想知道他们是怎么计算出来的。
下面是我对结果的解释:
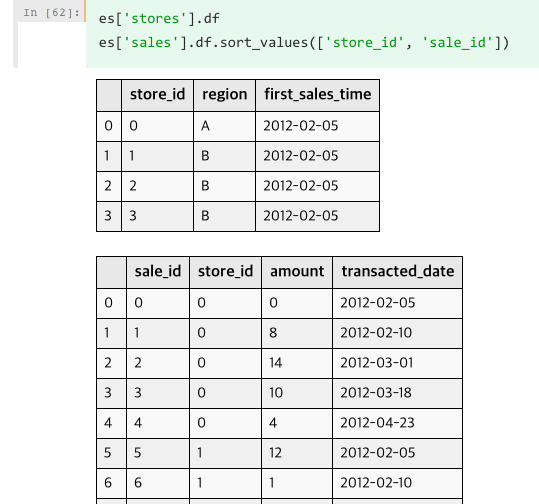
- 正如你在这里看到的,store_0在2012年2月有两个销售记录。因此,截止时间为2012-03-01年的
SUM(sales.amount)of store_id=0应该是0+8= 8,而不是19. - 同样,截止时间为2012-03-01年的
SUM(sales.CUM_MAX(amount))of store_id=0也应该是求和(sales.CUM_MAX(金额))= SUM(0,8) = 8,而不是37。
我错过什么了吗?他们是如何计算的?
回答 1
Stack Overflow用户
发布于 2020-04-16 22:44:49
这些概念将帮助您理解如何计算这些特性:
- 使用包含截止时间的时间索引的数据来计算特征。
- 为了按每个商店计算
CumMax,需要将其放在groupby_trans_primitives中而不是trans_primitives中。
我将通过一个例子。这是CSV格式的数据。
store_id,region,amount,transacted_date
0,A,16,2012-02-05
0,A,15,2012-02-10
0,A,13,2012-03-01
0,A,2,2012-03-18
0,A,3,2012-04-23
1,B,9,2012-02-05
1,B,8,2012-02-10
1,B,14,2012-03-01
1,B,1,2012-03-18
1,B,5,2012-04-23
2,B,6,2012-02-05
2,B,12,2012-02-10
2,B,4,2012-03-01
2,B,7,2012-03-18
2,B,11,2012-04-23
3,B,18,2012-02-05
3,B,19,2012-02-10
3,B,0,2012-03-01
3,B,10,2012-03-18
3,B,17,2012-04-23首先,我加载数据集。
import pandas as pd
train_df = pd.read_csv('data.csv', parse_dates=['transacted_date'])
train_df.sort_values(["store_id", "transacted_date"], inplace=True) store_id region amount transacted_date
0 A 16 2012-02-05
0 A 15 2012-02-10
0 A 13 2012-03-01
0 A 2 2012-03-18
0 A 3 2012-04-23
1 B 9 2012-02-05
1 B 8 2012-02-10
1 B 14 2012-03-01
1 B 1 2012-03-18
1 B 5 2012-04-23
2 B 6 2012-02-05
2 B 12 2012-02-10
2 B 4 2012-03-01
2 B 7 2012-03-18
2 B 11 2012-04-23
3 B 18 2012-02-05
3 B 19 2012-02-10
3 B 0 2012-03-01
3 B 10 2012-03-18
3 B 17 2012-04-23然后,我使用作曲自动生成相同的截止时间。
import composeml as cp
def total_amount(df):
return df.amount.sum()
lm = cp.LabelMaker(
target_entity='store_id',
time_index='transacted_date',
labeling_function=total_amount,
window_size='1MS',
)
lt = lm.search(
train_df,
num_examples_per_instance=-1,
minimum_data='2012-03-01',
) store_id cutoff_time total_amount
0 2012-03-01 15
0 2012-04-01 3
1 2012-03-01 15
1 2012-04-01 5
2 2012-03-01 11
2 2012-04-01 11
3 2012-03-01 10
3 2012-04-01 17现在,我构造实体集。
import featuretools as ft
es = ft.EntitySet(id="sale_set")
es = es.entity_from_dataframe(
"sales",
dataframe=train_df,
index="sale_id",
make_index=True,
time_index='transacted_date',
)
es.normalize_entity(
new_entity_id="stores",
base_entity_id="sales",
index="store_id",
additional_variables=['region'],
)
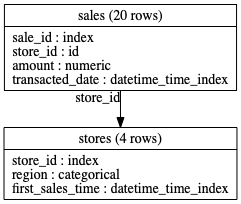
es.add_last_time_indexes()这是一个关于实体集是如何构造的阴谋。
es.plot()
最后,我运行DFS来计算这些特性。
fm, fd = ft.dfs(
entityset=es,
target_entity='stores',
cutoff_time=lt,
cutoff_time_in_index=True,
agg_primitives=["sum"],
groupby_trans_primitives=["cum_max"],
training_window="1 month",
max_depth=2,
verbose=1,
)
fm.filter(regex='SUM') SUM(sales.amount) SUM(sales.CUM_MAX(amount) by store_id)
store_id time
0 2012-03-01 44 48.0
2012-04-01 15 26.0
1 2012-03-01 31 32.0
2012-04-01 15 28.0
2 2012-03-01 22 30.0
2012-04-01 11 11.0
3 2012-03-01 37 56.0
2012-04-01 10 10.0我们可以看到,SUM(sales.amount)用于在截止时存储0,2012-03-01包含数据,直到并包含2012-03-01来计算特性。
>>> 16 + 15 + 13
44SUM(sales.CUM_MAX(amount) by store_id)在DFS中作为groupby_trans_primitives应用时也是如此。
>>> sum((16, 16, 16))
48如果这有帮助的话请告诉我。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61246974
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号